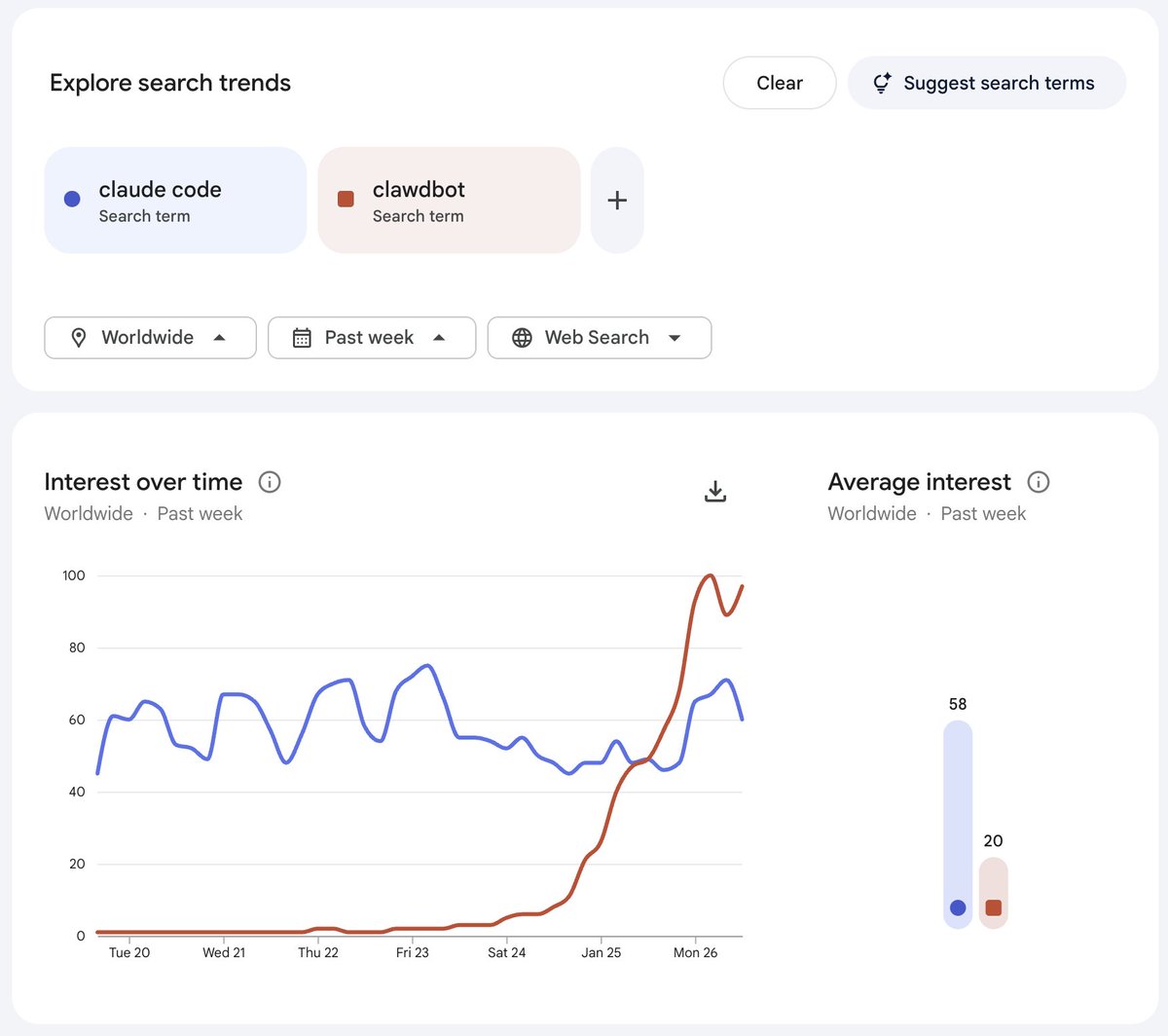
@tom_doerr look at how we used it in HACK26, i think results are quite nice!
github.com/maedmatt/Dream…
English
mattt
45 posts



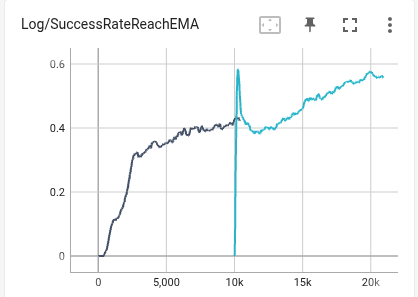
Feeling the achievement 😃These rewards are tuned for anymal (quadruped) and tron1 (biped lower body), but directly transfer to G1 (full humanoid) without tuning.
cannot make reward weights more beautiful
the vibe coding challenging day1 MDP setup day2 policy coded, need multiple rounds of human-agent interaction to fix things. Today won't be day 3, need to do other things, but I also just found many bad kp/kd and initialization designs in common G1 setup that hurts explroation.





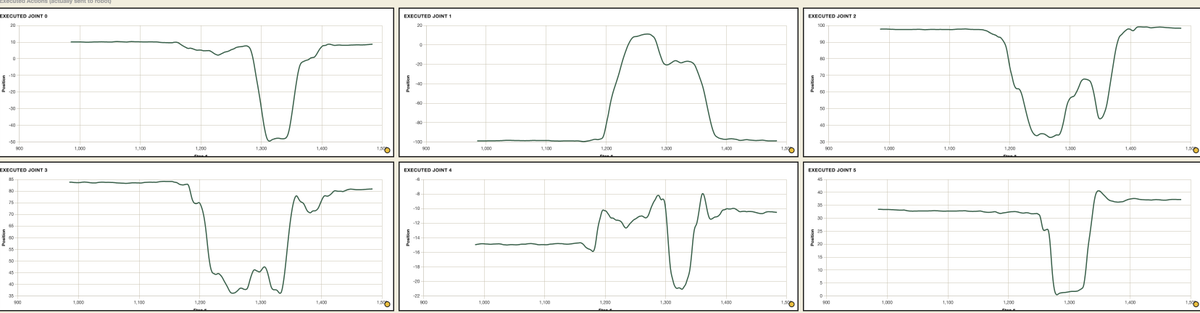
60hz! real time chunking on an so101 with LeRobot. Not looking too bad. Bit of jitter throughout but no mode switching across chunks