mindfury retweetledi

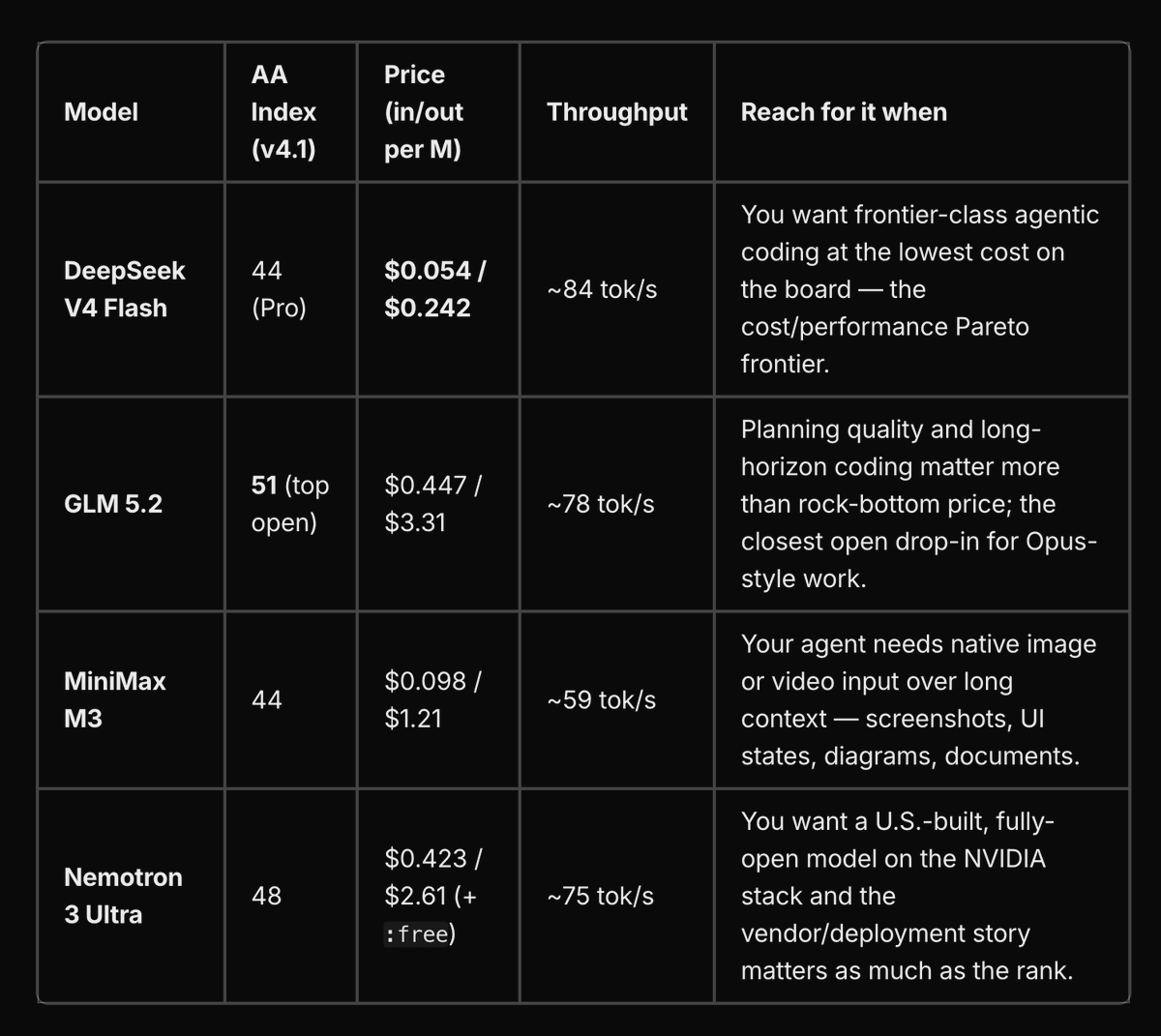
Four open-weight models have crossed into territory where they are powering real agentic pipelines.
New post in our Insights blog about why companies are choosing them in June: openrouter.ai/blog/insights/…
English
mindfury
4.3K posts


@mindfury1980
🇺🇸 | ♎️ | I’ve lived a strangely providential life. | 🐻❄️






Increase inference performance by up to 15x without sacrificing responsiveness. DFlash, an open source lightweight block diffusion model designed for speculative decoding, delivers up to 15x higher throughput on NVIDIA Blackwell while maintaining the same user interactivity target. Instead of drafting tokens one at a time, it proposes a whole block in a single pass for the main model to verify in parallel. Adoption is drop-in with support in @lmsysorg SGLang, TensorRT-LLM, and @vllm_project.


GLM-5.2 can now be run locally!🔥 The 2-bit model retains ~82% accuracy after we shrunk it from 1.51TB to 238GB (-84% size). Run on a 256GB Mac or RAM/VRAM setups. GLM-5.2 is the strongest open model to date. Guide: unsloth.ai/docs/models/gl… GGUF: huggingface.co/unsloth/GLM-5.…


@SlimTradeyBaby @NVIDIAAI ❤️❤️❤️❤️


the DGX Spark nvidia sent me is a full supercomputer that fits on my desk. GB10 grace blackwell, 128GB unified memory, sips power off a wall socket, runs models that needed a server rack two years ago. spent last night pushing it on the hardest case i could find, a dense 27B model, to map exactly where it flies and where physics bites. all measured. > 1. dense decode is memory bound everywhere, not a spark thing. to write one token the gpu reads all 27B weights out of memory, and the spark's compute is so far ahead of its bandwidth that the chip sits half idle waiting. baseline 7.64 tok/s. hold that number. > 2.this is where the spark shines: speculative decoding. the model guesses a few tokens ahead, the spark verifies them in one batched pass, one weight read confirms ~4 tokens. 7.64 to 17 tok/s, a clean 2.2x, output byte-identical, one flag. it works precisely because the spark has spare compute sitting idle, and this finally puts it to work. the headroom you paid for earns its keep. > 3. honest catch: that's a short-context win. at 256k tokens it fades to 1.37x because you cross from memory bound to compute bound on attention. physics on any box, not the spark. > 4. the payoff, the spark flexing: switch to a same size MoE and it does 21.7 tok/s at that same 256k, nothing special turned on. a 256k context window at usable speed on a box next to my coffee. that's what nvidia is putting on developers' desks. the lesson: match the model to the machine and the spark is a beast. dense plus spec decode for short sharp work, MoE when you need the long context. either way it's a datacenter's job running off a wall socket. bookmark it, all measured on one box. (nvidia sent me the spark, no money changed hands, every number is mine)











