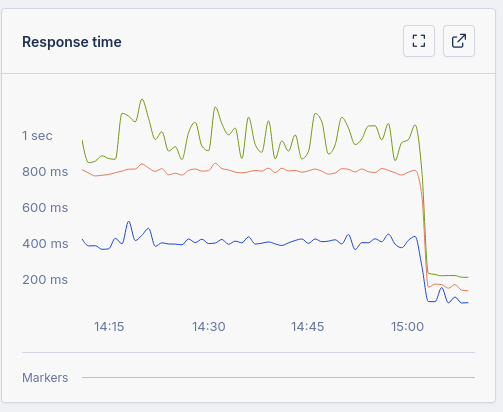
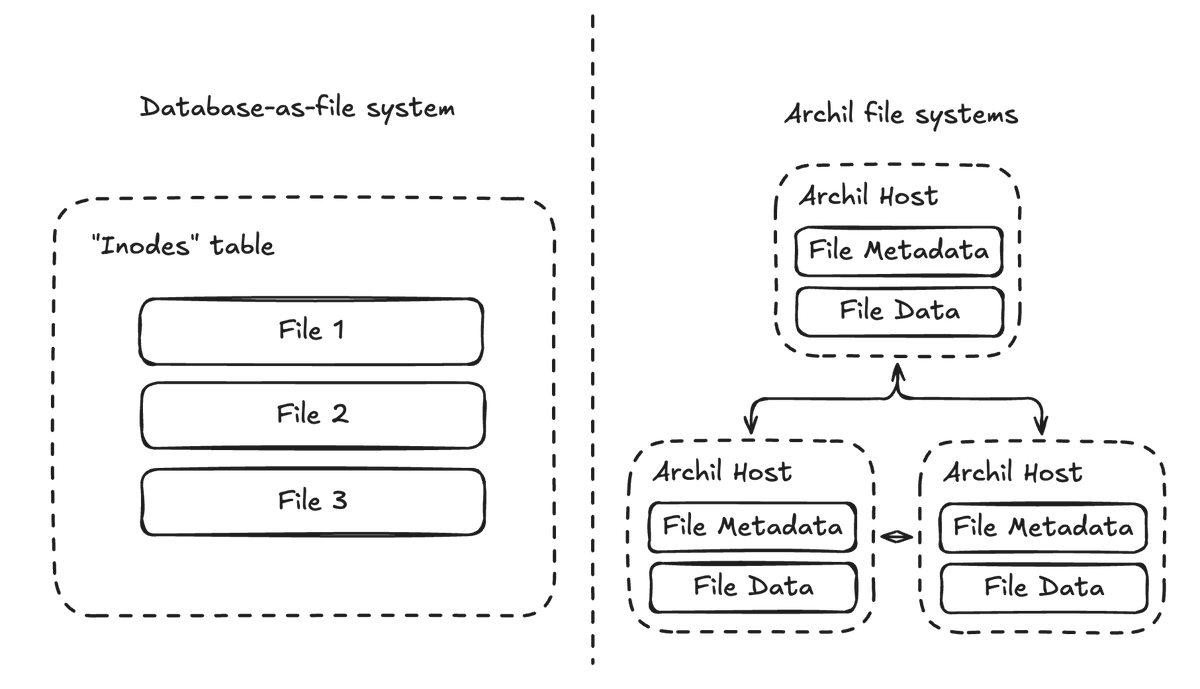
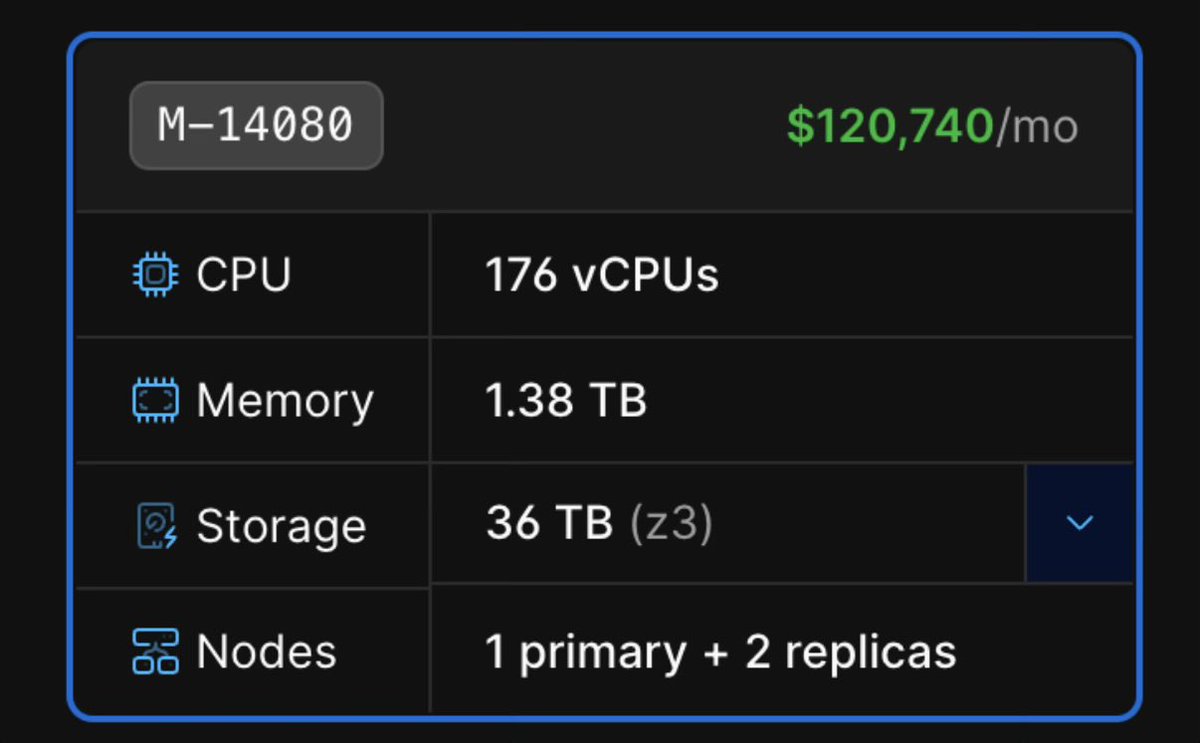
@samlambert Thats about 1TB more memory for that SSD capacity than I’m used to. And I thought you were all about IOPS.
English
Domas Mituzas 🤡
1.6K posts
@mituzas
small data artisan. distinguished weaponized adhd at meta, survived hypergrowth at facebook(2009+)/wikipedia(2004-2011), dining fakefluencer on ig domas.eats