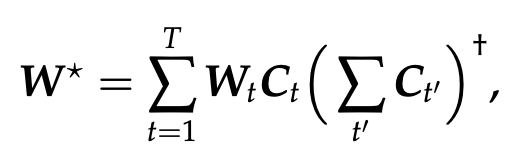Sabitlenmiş Tweet

New preprint! Introducing ACTMat: Model Merging via Data-Free Covariance Estimation
Work done w/ @dtredsox13, @PTikeng, Colin Raffel and Guillaume Rabusseau
TL;DR: It's RegMean, but without needing data for covariance estimation (C ≈ Δᵀ Δ)
📄 arxiv.org/pdf/2604.01329
🧵(1/6)

Română