
Nilabhra Roy Chowdhury
633 posts

Nilabhra Roy Chowdhury
@nilabhraroy
I train LLMs
Dubai, United Arab Emirates Katılım Eylül 2015
500 Takip Edilen195 Takipçiler


Nilabhra Roy Chowdhury retweetledi

The @bfl_ml team released Klein KV and showed how KV-caching can incorporated in a flow pipeline 🤯
The idea is simple and elegant.
In the first denoising step, reference image tokens are included in the full DiT forward pass. Their per-layer KVs are computed and cached.
In the subsequent steps, KVs for only noisy latents are computed while the cached reference KVs are injected during computing attention.
As a result, it delivers upto 2.5x speedups for multi-reference editing tasks over Klein.
I basically learned about it from this PR:
github.com/huggingface/di…
The PR is a poetry in motion and is from the BFL team itself! Kudos to them for always being the best when it comes to designing codebases for flow and diffusion models. The best!
Check out the model here:
huggingface.co/black-forest-l…
English
Nilabhra Roy Chowdhury retweetledi

We just released pre-mixed, pre-shuffled pretraining datasets at 100BT scale.
@asankhaya tested 50+ different mixture strategies at 1B scale. The winner? A static 50% finePDFs + 30% DCLM + 20% FineWeb-Edu blend. No fancy curriculum needed.
We scaled this up to 100BT and pre-shuffled everything so you don't have to burn compute on sampling. Just use it:
from datasets import load_dataset
ds = load_dataset("HuggingFaceFW/finepdfs_50BT-dclm_30BT-fineweb_edu_20BT-shuffled")
Browse the full smol-data collection: huggingface.co/collections/Hu…
Reproduce it yourself: github.com/huggingface/da…
Read the methodology: huggingface.co/blog/codelion/…

English
@RisingSayak @cneuralnetwork Why am I being tagged? 🤣
English

idk some seniors literally treat juniors shit, in excuse of teaching manners. I've seen so many cases of literal abuse from seniors to juniors in many colleges because of some on-existent ego problems for some reason.
people have really forgotten how to be a decent human over some stupid attitude problems.
English
Nilabhra Roy Chowdhury retweetledi

Adversarial attacks on vision language action models. x.com/cosyposter/sta…
English
Nilabhra Roy Chowdhury retweetledi

The Maximal Update Parameterization (µP) allows LR transfer from small to large models, saving costly tuning. But why is independent weight decay (IWD) essential for it to work?
We find µP stabilizes early training (like an LR warmup), but IWD takes over in the long term! 🧵

English
Nilabhra Roy Chowdhury retweetledi

We found a new way to get language models to reason. 🤯
No RL, no training, no verifiers, no prompting. ❌
With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.
English
@RisingSayak Well said. It provides insights to model optimisation after the prototyping phase and the insights help the user discover new avenues for optimisation which otherwise would have been quite opaque.
English
`torch.compile`, in a way, teaches you many good practices of implementing models like TensorFlow used to (yeah, I said that).
Some personal favorites:
1> Forcing a model to NOT have graph breaks and recompilation triggers
2> CPU <> GPU syncs (reduce lookup time)
3> Weather regional compilation is desirable
4> Prepping the model for dynamism during compilation without perf drawbacks
Then, in the context of diffusion models, delivering compilation benefits with critical scenarios like offloading and LoRAs is just a joyous engineering experience to implement!
And then comes testing, which tops it all off (my most favorite part).
If you're interested in all of it, I can recommend a post "torch.compile and Diffusers: A Hands-On Guide to Peak Performance", I co-authored with @anijain2305 and @BenjaminBossan!

English


Nilabhra Roy Chowdhury retweetledi

We’re building Stargate Norway to support the most demanding AI workloads in the world — built for scale, speed, and sustainability. @nvidia's leadership in accelerated computing makes it possible to push the limits of what’s technically achievable, from training massive foundation models to deploying ultra-low-latency inference applications.
🎥 Watch the full announcement: youtube.com/watch?v=rWx824…

YouTube
English


MISSION TO EARTHPHASE - MOONSHINE GOLD is now available! Remember this timepiece is only available today August 9, 2025, at selected Swatch stores worldwide.
#MoonSwatch #OMEGAxSwatch #Swatch
swat.ch/3HoMaWE
English
Nilabhra Roy Chowdhury retweetledi
GPT-OSS-120B and GPT-OSS-20B are now live on Nscale as day-zero serverless endpoints.
No orchestration required. Just build.
You’ll also find Nscale listed as an inference provider on @huggingface, making it even easier to get started wherever you build.
At Nscale, we’re committed to getting powerful AI into the hands of practitioners—quickly, safely and without lock-in.
Give them a whirl: nscale.com

English
Nilabhra Roy Chowdhury retweetledi
Nilabhra Roy Chowdhury retweetledi

NCCL tree allreduces when the rank assignments match the network topology
@@anthraxxxx
Malaysian team smoked South Korean team in cup stacking competition
English

Large language model (LLM) training suffers from gradient instability and loss spikes, and fixed gradient clipping methods fail to adapt dynamically.
This paper proposes ZClip, an adaptive algorithm that adjusts the clipping threshold based on the gradient norm's recent statistical properties (mean and standard deviation).
ZClip proactively mitigates spikes, enabling stable training even at higher learning rates, achieving baseline performance up to 35% faster in some tests.
📌 ZClip dynamically adapts its threshold to evolving gradient statistics, unlike fixed methods.
📌 Lightweight Exponential Moving Average statistics provide efficiency over history-based adaptive methods like AutoClip.
📌 Stabilizing higher learning rates (e.g., 3.0e-3), ZClip achieves 35% faster convergence demonstrated.
----------
Methods Explored in this Paper 🔧:
→ ZClip detects gradient norm anomalies using z-scores calculated relative to the gradient norm's running mean and standard deviation.
→ It efficiently tracks these statistics using exponential moving averages (EMA), avoiding the need to store a full history.
→ When a spike (z-score above a threshold) occurs, the gradient norm is scaled down, often using a reciprocal function based on the spike's severity (z-score value).
→ To prevent skewed statistics, updates to the mean and variance use the adjusted (clipped) gradient norm value during spike events.
----------------------------
Paper - arxiv. org/abs/2504.02507
Paper Title: "ZClip: Adaptive Spike Mitigation for LLM Pre-Training"

English

this guy invented VLLM. he's basically the john wick of CUDA kernels

English
Nilabhra Roy Chowdhury retweetledi
Want to benefit from `torch.compile()` while hotswapping LoRA adapters into your diffusion models?
This is now possible, thanks to the OG @BenjaminBossan's incredible hard work!
Follow the comments for a tutorial, code, etc.
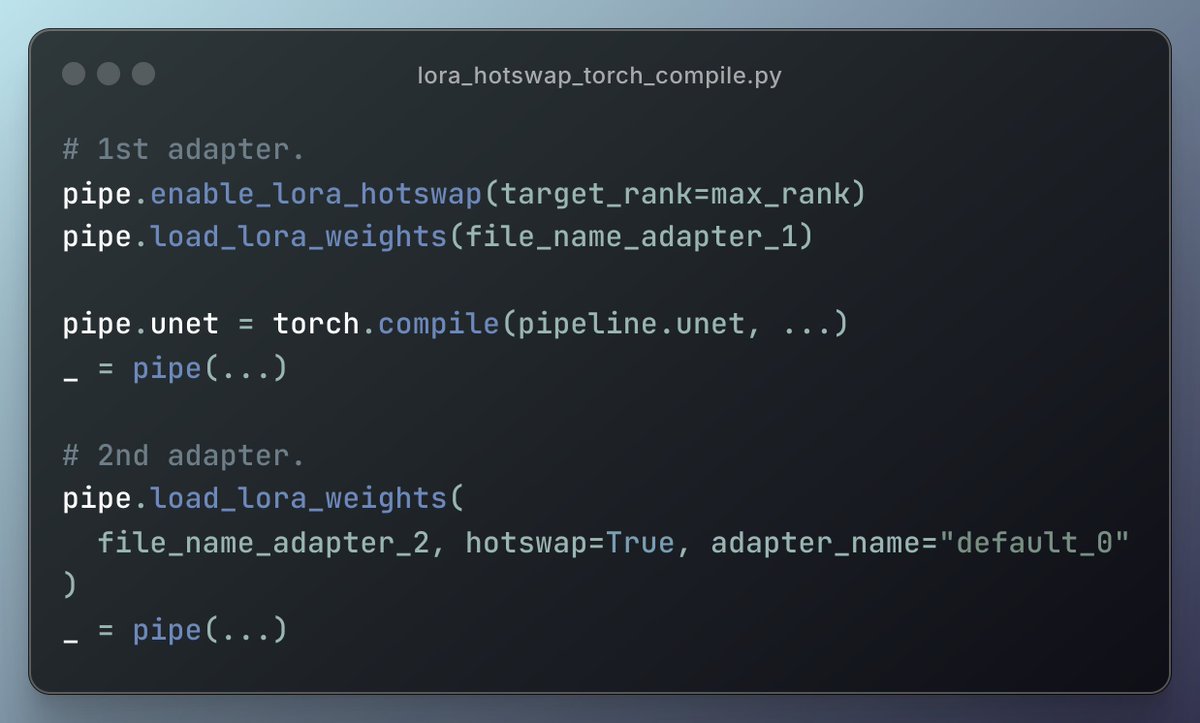
English
@cheatyyyy @JeffDean @jeremyphoward You don’t need all the experts to be in memory all the time. Experts can be swapped in and out as needed. This is will be slow but possible.
English

@nilabhraroy @JeffDean @jeremyphoward scout is 109b
the max that fits on my 3090 with 8k context is a qwen 32b model at 4.5bpw
i would need 4 3090s to run it
English

Just read through the Llama 4 release announcement.
I'm really grateful they've released this with open weights. But tbh I'm also pretty disappointed.
The models are both giant MoEs that can't be run on consumer GPUs, even with quant.
ai.meta.com/blog/llama-4-m…
A big loss.😢
English
@JeffDean @jeremyphoward The scout should be able to run on a single GPU with limited context length right?
English
