Patrick (Pengcheng) Jiang retweetledi

This paper from Stanford and Harvard explains why most “agentic AI” systems feel impressive in demos and then completely fall apart in real use.
The core argument is simple and uncomfortable: agents don’t fail because they lack intelligence. They fail because they don’t adapt.
The research shows that most agents are built to execute plans, not revise them. They assume the world stays stable. Tools work as expected. Goals remain valid. Once any of that changes, the agent keeps going anyway, confidently making the wrong move over and over.
The authors draw a clear line between execution and adaptation.
Execution is following a plan.
Adaptation is noticing the plan is wrong and changing behavior mid-flight.
Most agents today only do the first.
A few key insights stood out.
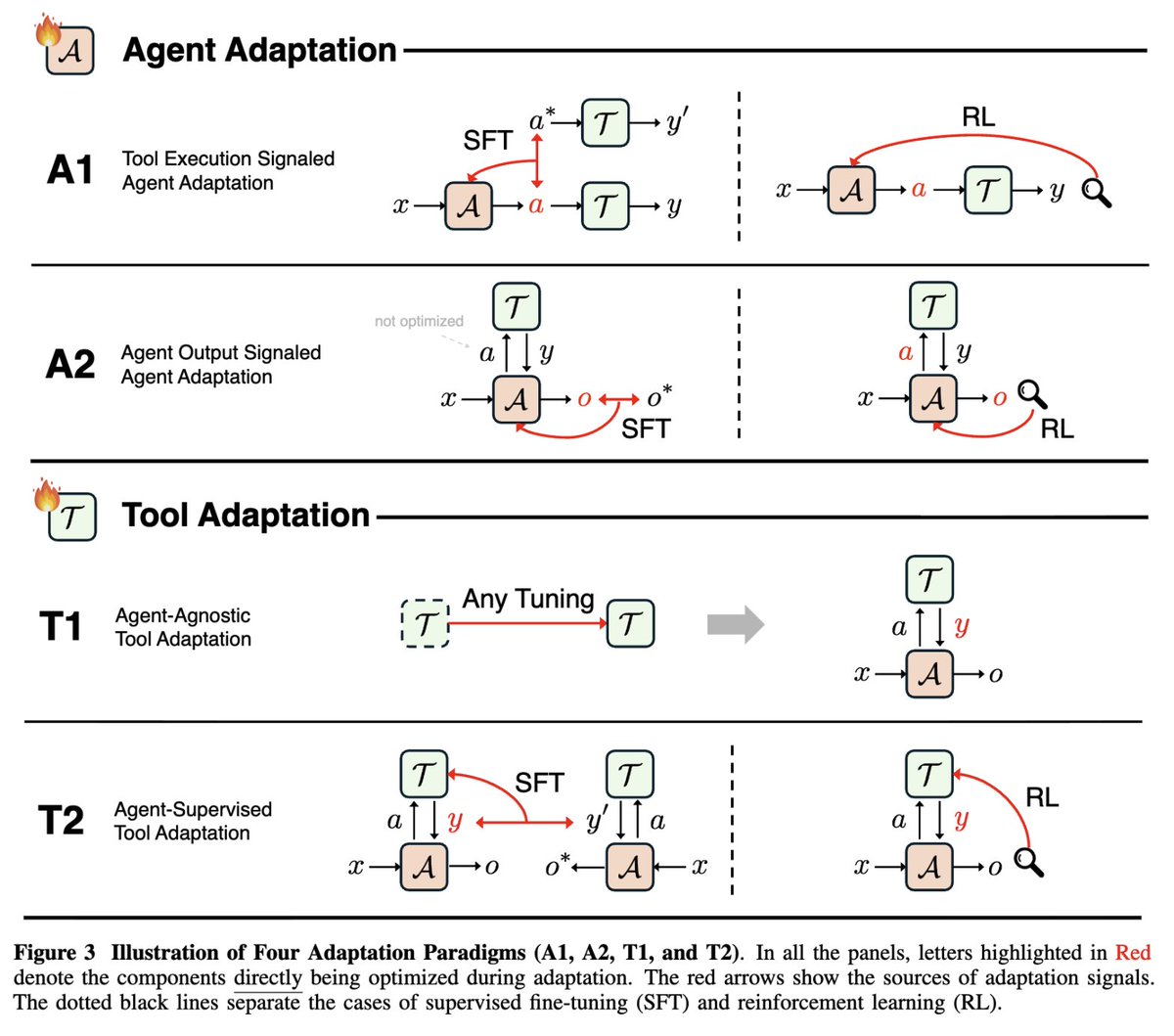
Adaptation is not fine-tuning. These agents are not retrained. They adapt by monitoring outcomes, recognizing failure patterns, and updating strategies while the task is still running.
Rigid tool use is a hidden failure mode. Agents that treat tools as fixed options get stuck. Agents that can re-rank, abandon, or switch tools based on feedback perform far better.
Memory beats raw reasoning. Agents that store short, structured lessons from past successes and failures outperform agents that rely on longer chains of reasoning. Remembering what worked matters more than thinking harder.
The takeaway is blunt.
Scaling agentic AI is not about larger models or more complex prompts. It’s about systems that can detect when reality diverges from their assumptions and respond intelligently instead of pushing forward blindly.
Most “autonomous agents” today don’t adapt.
They execute.
And execution without adaptation is just automation with better marketing.

English