
Renat Lotfullin
1.1K posts

Renat Lotfullin
@renatlb
Sustainable world evangelist | https://t.co/aF8GeBuOdA
Earth Katılım Kasım 2010
318 Takip Edilen328 Takipçiler

5/ Solid landscape overview + decision framework on who should use what.If you’re in data platforms, analytics engineering, or AI, this is worth reading.→
Full article: gdotv.com/blog/graph-on-…
#GraphDatabases #DataEngineering #Databases #GQL #SQL
English
1/ Excellent new piece from @gdotv_ltd :
“A Landscape of the Emerging Graph on Relational Category”
Graph workloads are going mainstream and you no longer need to move your data into a separate graph database.
A whole new category is forming: Graph on Relational engines. 🧵

English
@BlancheMinerva @storytracer @soldni @jakepoznanski @status_effects @leppert @JJitsev Thanks a lot! That's so helpful I was struggling with old technical books parsing
English

GitHub Repo: github.com/StellaAthena/o…
If you find it useful, or have suggestions for improvement, don't hesitate to reach out.
Might be of interest to @storytracer @soldni @jakepoznanski @status_effects @leppert @JJitsev
English
I've been frustrated by the fact that OCR benchmarks are ~meaningless, but you can pretty easily grok quality at a glance... if it's easy to see what the OCR algorithm is catching and what it's missing. So I finally sat down and created a visualizer
GIF
GIF
English

You simply can’t rely on a single AI provider to run your business and your life anymore.
1. BYOAI: Bring Your Own AI
Drastic but entirely predictable moves, like the one Anthropic just made, are exactly why you must become token-independent. In a future token-maxxing economy, if Supplier A turns against its core users, what will Supplier B do?
The ability to switch between AI providers and run local models will be critical in the years ahead.
2. Data Ownership
Any business or individual who keeps their data and workflows locked inside a single company’s ecosystem will struggle to extract it and keep operating seamlessly when it’s time to switch.
Owning your data in your own cloud or a trusted provider’s storage will become the standard by 2027. You can’t let “walled gardens” hold your core assets.
3. Self-Hosted
If AI is holding your context, plans, research, and operating memory, it should run in an environment you control.
Cabinet is the layer above the AI providers that simply lets you work. Built around the principles that will matter most for the future of AI + data tools:
Your knowledge base. Your AI team.
runcabinet.com
ClaudeDevs@ClaudeDevs
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of: - Claude Agent SDK - claude -p - Claude Code GitHub Actions - Third-party apps built on the Agent SDK
English




If no one answers, I’ll push forward alone!! I fully intend to ! 🍎
English
I need your help: S.A.V.O.I.R. has grown beyond what one person can handle."
I’ll be blunt: I’ve been juggling S.A.V.O.I.R. alongside several other projects, and as the model evolves, I’ve hit a wall. I can no longer keep up with the pace of its growth alone. This is an open call for collaborators.
The vision: I’ve released the core concept as open-source because I believe transformative knowledge should be shared, not sold. However, the implementation will be proprietary, and those who contribute will hold ownership in the project.
Whether you are a mathematician, hardware engineer, biologist, neuroscientist, UI/UX designer, or philosopher—if you’re tired of "static" AI and want to build something rooted in biology and physics, I need you.
I can’t promise that S.A.V.O.I.R. will become the world’s first true AI, but the proof of concept is already working. Even if we don’t reach the finish line, the scientific data we’re uncovering is invaluable. If you're ready to push the boundaries of science, DM me. 🍎

English
@AlexanderKalian @0x506c61746f so interesting, I'm experimenting context map approach over graphs
English

@0x506c61746f The problem is deeper - it's about capturing complex topological information about the graph structure and how nodes/edges relate to each other - while still not oversquashing individual node and edge level features.
English
Graph neural networks fall into an awkward AI category of: "kinda works, but meh".
This is how RNNs and LSTMs felt for natural language processing, before transformers were introduced in 2017.
Graph machine learning needs its own transformer moment.
English
Graph neural networks, in theory, should be far more useful for AI in biology than transformers or LLMs.
Biological systems are naturally organised as high-dimensional, non-Euclidean graphs - molecular graphs, gene interaction networks, knowledge graphs, etc.
Yet transformers still dominate GNNs on tasks like molecular bioactivity prediction - even when GNNs are enriched with physical properties about atoms and bonds.
The core problems are information loss during message passing and global pooling layers. Adding attention mechanisms helps (GATs, GTNs, global attention pooling, etc.), but it’s not enough.
What the GNN field and AI/bio desperately needs is a revolutionary new architecture - an "Attention is All You Need" moment for GNNs, as significant as the transformer.
English

Hey Ben, where are all the courses?
In 2026, I’ve cut down a lot on new courses for Hugging Face. Mainly because it felt like learning had undergone a major change, and people just weren’t upskilling in the same way.
A lot of students are learning with their agents plus some YoutTube. And I wanted to figure out a way to meet this audience. (Check out the Hugging Face YouTube channel for some great content there)
Coming soon! A new course on Hugging Face that is fully agent integrated, based on long form videos, and use real projects.
English

aiming for 5 research topics for the upcoming few months, if yall want to join in pls do so,
GPU shortage wont be there (hopefully)
(worked on these problem statements a bit previously, and have ran a few experiments on each)
find them below:
ps 1 : Process Reward Models Beyond Outcome Supervision
Without the need for human-labeled trajectories, we provide a completely automated approach for training Process Reward Models (PRMs) that either meet or surpass the quality of gold step-level annotations. We create dense Monte-Carlo Tree Search (MCTS) rollouts with depth d ≥ 32 and branching factor b = 8, starting from a base policy π_θ trained via SFT on chain-of-thought data. Each intermediate step is scored using an ensemble of outcome verifiers (ORMs) bootstrapped from self-consistency and LLM-as-judge signals under temperature T = 0.7. A process-DPO variation with step-wise Bradley-Terry losses weighted by MCTS visit counts and calibrated via Platt scaling on a short held-out verification set is introduced to reduce verifier noise.
By simultaneously optimising the PRM and policy under a single RLVR goal that alternates between process-level preference optimisation and outcome-level PPO updates, with adaptive mixing ratio λ_t planned via cosine annealing, our method closes the annotation gap. Our auto-annotated PRM delivers +14.7% pass@1 over outcome-only RM baselines at 7B scale and transfers to code and scientific reasoning domains with 3% deterioration following LoRA adaptation on 2k domain-specific trajectories, according to extensive ablation on GSM8K, MATH, and HumanEval. We present the multi-domain PRM benchmark, the distilled verifier weights, and the whole MCTS annotation program, offering the first production-ready recipe for frontier-scale process supervision.
ps 2 : Computer-Use Agents and GUI Grounding
In addition to introducing a large-scale synthetic data engine that uses Playwright + Android Emulator instrumentation to generate 500k grounded interaction traces across web, mobile, and desktop environments, we formalise GUI grounding failures through a tripartite decomposition: perception (pixel-to-semantic mapping), planning (high-level action sequence), and execution (low-level mouse/keyboard trajectories). Pixel-level segmentation masks, accessibility tree annotations, and oracle action sequences obtained via deterministic UI state diffing are linked with each trace. Using a hybrid loss that combines contrastive screen embedding alignment (using InfoNCE on cropped UI elements), autoregressive action token prediction, and auxiliary bounding-box regression heads that function at 4× downsampled resolution to maintain fine-grained OCR and icon semantics, we train a multimodal VLA policy on top of a Qwen2-VL-7B backbone.
A domain-adversarial training objective that aligns screen embeddings across platforms while maintaining task-specific action distributions is combined with test-time adaptation using a lightweight 256M adapter that conditions on platform-specific accessibility trees to achieve cross-platform zero-shot transfer. Our model decreases end-to-end grounding error from 48% (Claude-3.5 baseline) to 19% on the recently released GUI-Grounding-Bench (which includes 12k actual jobs from WebArena, AndroidWorld, and OSWorld), with the biggest improvements in perception-heavy mobile UIs. We provide the cross-platform VLA checkpoint, the failure atlas taxonomy, and the complete synthetic trace generator, creating the first reproducible benchmark and recipe for reliable computer-use agents.
ps 3 : Agent Memory Architectures Beyond RAG
We present TypedAgentMemory, a modular memory substrate controlled by a differentiable memory controller trained end-to-end with the agent policy that explicitly distinguishes episodic semantic (dense vector summaries with SAE-derived concept tags), procedural, and working (short-term KV cache compression) memories. A 128-dim uncertainty head that thresholds epistemic uncertainty from an ensemble of forward passes gates memory writes. The controller uses a hierarchical policy over four memory operations: write, consolidate (graph-based merging with GNN message passing), forget (learned eviction via eligibility traces and recency + relevance scores), and retrieve (hybrid dense + symbolic query routing). Explicit memory consolidation every 50 steps is used to evaluate long-horizon tasks on τ-bench, WebArena, and GAIA. This results in a 2.3× decrease in context length and a 31% improvement in success rate over flat vector-store RAG baselines.
Per-memory-type differential privacy approaches, such as homomorphic encryption for procedural skill graphs, concept-level k-anonymity on semantic features, and ε = 0.5 noise injection on episodic writing, are used to ensure privacy. Ablations show that typed memory facilitates effective cross-task transfer through procedural memory reuse and prevents catastrophic forgetting on 200-step agent trajectories. We provide the first rational substitute for monolithic RAG for production-grade autonomous agents by making the whole TypedAgentMemory library (based on LangGraph + FAISS + Neo4j), the long-horizon evaluation harness, and pretrained memory controllers for Llama-3.1-8B and Qwen2.5-72B open-source.
ps 4: SAE Universality Across Model Families
By training 128k-feature JumpReLU SAEs (expansion factor 64, k = 32) on residual streams of Llama-3.1-8B, Qwen2.5-72B, Gemma-2-27B, Mistral-Large-2, and DeepSeek-V3 with the same hyperparameters and reconstruction aims, we perform the first extensive cross-family SAE universality investigation. A bipartite matching that quantifies pairwise overlap at both neuron-level (cosine similarity > 0.85) and concept-level (via automated interpretation pipelines using 512 probe prompts per feature) is obtained by performing feature matching via optimal transport with Sinkhorn algorithm on normalised decoder weight matrices. By grouping similar features from different families into 4.2k platonic ideas and annotating each concept with activation data, downstream steering efficacy, and causal mediation scores calculated via route patching, we further build a universal feature library.
Steering vectors created from the universal library outperform within-family SAEs on out-of-distribution tasks and enhance zero-shot generalisation on MMLU-Pro, GPQA, and LiveCodeBench by an average of 9.4% when transferred between families, according to downstream transfer studies. We make available the whole SAE training software, the universal concept library with 4.2k interpreted features, the cross-family matching dataset (which includes optimum transport plans), and a plug-and-play steering toolkit that works with Hugging Face Transformers and vLLM. In order to facilitate transfer learning, model merging, and safety interventions within the existing frontier model ecosystem, this study offers the first rigorous atlas and infrastructure for mechanistic universality.
ps 5 : Synthetic Data Generation Without Mode Collapse
We provide an iterated synthetic data pipeline that explicitly characterises the collapse threshold ρ*(q) as a function of generator quality q (as determined by the activation entropy of the SAE feature and the entropy of the output distribution H_π). Using temperature-annealed sampling (T=1.0 → 0.7) supplemented with SAE-guided rejection sampling, we create synthetic corpora at different mixing ratios ρ ∈ {0, 0.1,…, 1.0} starting from a 7B base policy π_θ trained on 200B tokens of FineWeb-Edu. At each generation, we train a 128k-feature JumpReLU SAE (expansion factor 64, k=32) on the residual stream of the current model and filter synthetic samples whose top-activating features show activation entropy below a calibrated threshold τ derived from the real-data reference distribution.
Our experiments provide the first empirical collapse-threshold map ρ*(q) at 1.3B–7B scale, demonstrating that SAE-guided diversity sampling extends the safe mixing ratio by 2.3× compared to persona-conditioned or temperature-only baselines, while generator entropy H_π ≥ 4.2 nats delays the onset of measurable perplexity degradation on a held-out real validation set until generation 7 under accumulation (versus generation 3 under pure replacement). A closed-form constraint on variance contraction rate under synthetic mixing is derived theoretically, connecting the number of safe iterations before tail probability mass falls below 10^{-3} to the spectral gap of the generator's transition kernel.

English
@iScienceLuvr I would add engineering AI for production modeling and assesment
English

a surprising amount of people don't understand the difference between AI in biology and AI in medicine...
i've had to explain it countless times in the past ~4 years
AI in bio - models for DNA/RNA/proteins/cells, AlphaFold, GPT-Rosalind, etc.
AI in medicine - models for clinical data, patients, clinicians, MedGemma, ChatGPT for Health, etc.
Lots of frontier labs are investing heavily in the former.
At @SophontAI and @MedARC_AI, we work on the latter.
English

I tried to get a local LLM (nemotron-cascade-2) to write an ML model.
While it wasn't able to do it using @opencode but it was worth sharing, it got the code good enough (not sure, couldn't verify as it failed to actually write it to a file)
Also, when I followed up, it lost context. But it is cool that we can run a 30B param LLM on a 5 year old GPU!
English
@DmitriLLM @GergelyOrosz История учит тому, что никого ничему она не учит 💁♂️
Русский

Hungary, in the end, chose Europe, rejected Russia, and rejected sprawling corruption.
With record turnout (78% of those eligible voting), Tisza gained supermajority.
Orbán’s autocratic regime, built out, step by step, over 16 years, will promptly be dismantled.
Historic!
Gergely Orosz@GergelyOrosz
Today, Hungary votes. The choice is between an anti-EU, pro-Russia, pro-corruption party reigning for 16 years (Orbán’s party: Fidesz) or a pro-EU, anti-Russia, anti-corruption party (Tisza). My mail-in vote went for Tisza ❤️🤍💚 A rendszerváltásért!
English


gemma 4 31B does indeed run on this MBP M5 Max (128GB), but boy is it slow.
opus is safe for now
English
@ZechenZhang5 @orch_research will it be free or paid plans coming?
English

Every developer has an IDE. Researchers never had one.
We don’t need another research agent, but a full stack workstation powered by AI.
Today we're launching Orchestra @orch_research, the world's first Research IDE 🔬🧵
English

Building a personal knowledge base for my agents is increasingly where I spend my time these days.
Like @karpathy, I also use Obsidian for my MD vaults.
What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers.
I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal.
You all get to benefit from that with the papers I feature in my timeline and on @dair_ai.
The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there.
I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip.
100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation.
But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close.
The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to.
Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them.
Work in progress. More updates soon. Back to building.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@stitchbygoogle Stitch is poor for creative website design. Same patterns and layouts for all prompts, variations are just playing with fonts weights. Figma still a reliable workhorse for production ready web designs.
English

🚨Important update regarding your vibe design partner.
We received overwhelming feedback that our new AI-native canvas was a little too clean and modern. We hear you.
Today, we are shipping an immediate fix to bring you the true essence of vibe design.
Say hello to the Maximalist Update. 🌈✨
English
@michael_kove @burkov Guys, can you try a bit harder please, thank you!
English

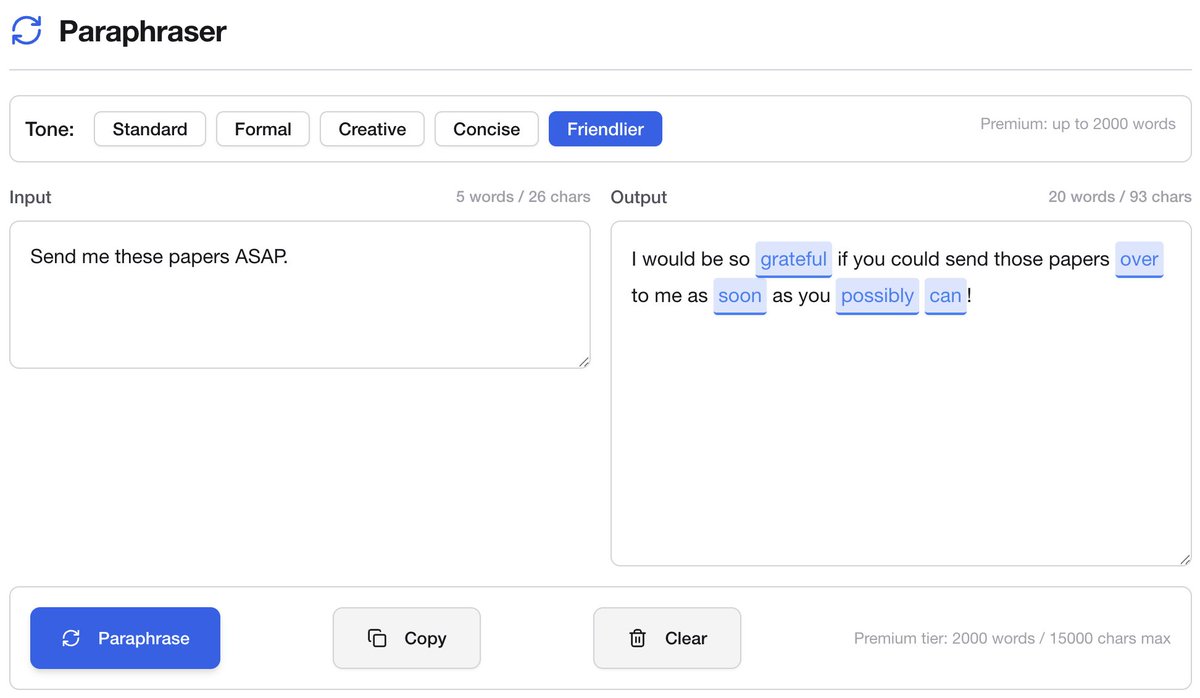
@burkov "чеблязахуйня, сделайте нормально,бля" >> "Guys, can you please try again, thank you!"

I think in Russian, so my emails in English are too direct. "Make it sound friendlier" is one of my favorite use cases for LLMs.
llambada.com/p/quaCYfR6/par…
English
Renat Lotfullin retweetledi

Today is the birthday of Yuri Gagarin (9 Mar 1934 – 27 Mar 1968) who was a Russian pilot and cosmonaut who became the first human to journey into outer space, achieving a major milestone in the Space Race; his capsule, Vostok 1, completed one orbit of Earth on 12 April 1961.

English
Renat Lotfullin retweetledi

It's a Sunday morning and we're connecting on #Clubhouse in the "Impact Founders Resources Bio Silent Share" room, with mods @PeteDeMare & @renatlb #ClubHouseApp
English
@TheRussAvery thank you very much for the great opportunity to shortly pitch Alangreen project!
English