@ZFingerhut14747 @iruletheworldmo He's a scammer, capitalizing on your engagement. What do you think?
English
Ridhvik Gopal (Vik)
36 posts







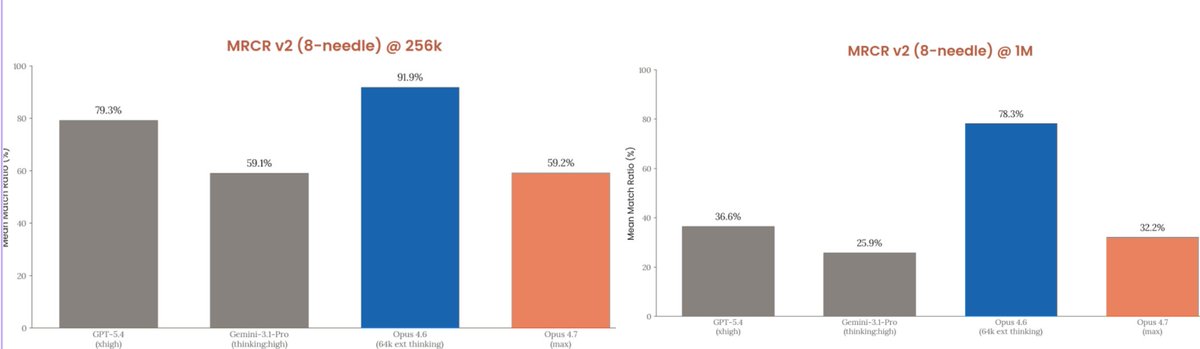
Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision.

happy release day one and all. this will go down as the most monumentous day in human history. (it’s a word, go away) it’s one small step for man, and one mighty giant leap for ai. happy release day to all that celebrate 🥹 what upcoming release excited you most? -the SUPER APP -the SPUD -the IMAGE-GEN for me. it’s all about the glorious combination.



There seems to be some confusion on what ChatGPT plans give you, and what bonuses are active right now. I got you. ChatGPT Plus $20 = 1x NO ACTIVE BONUS ChatGPT Pro Lite $100 = 5x with a 2x Bonus (10x) ChatGPT Pro $200 = 20x with a 2x Bonus (40x) The bonus is ONLY for Pro plans. It includes BOTH $100 & $200 Tiers They both end May 31st. THANK YOU FOR YOUR ATTENTION TO THIS MATTER. SIGNED AMW


JUST IN: Anthropic reportedly considering designing its own AI chips to reduce dependence on Nvidia.

ChatGPT Pro $100 plan is out! At least we got something today