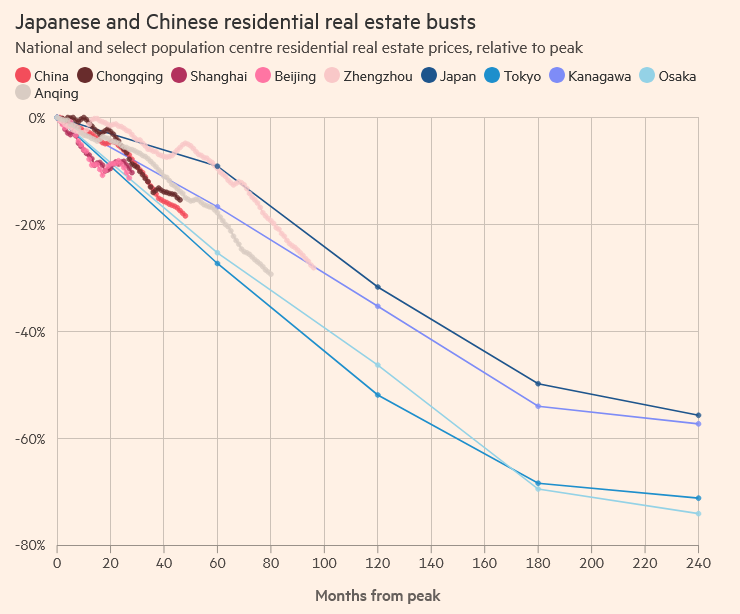
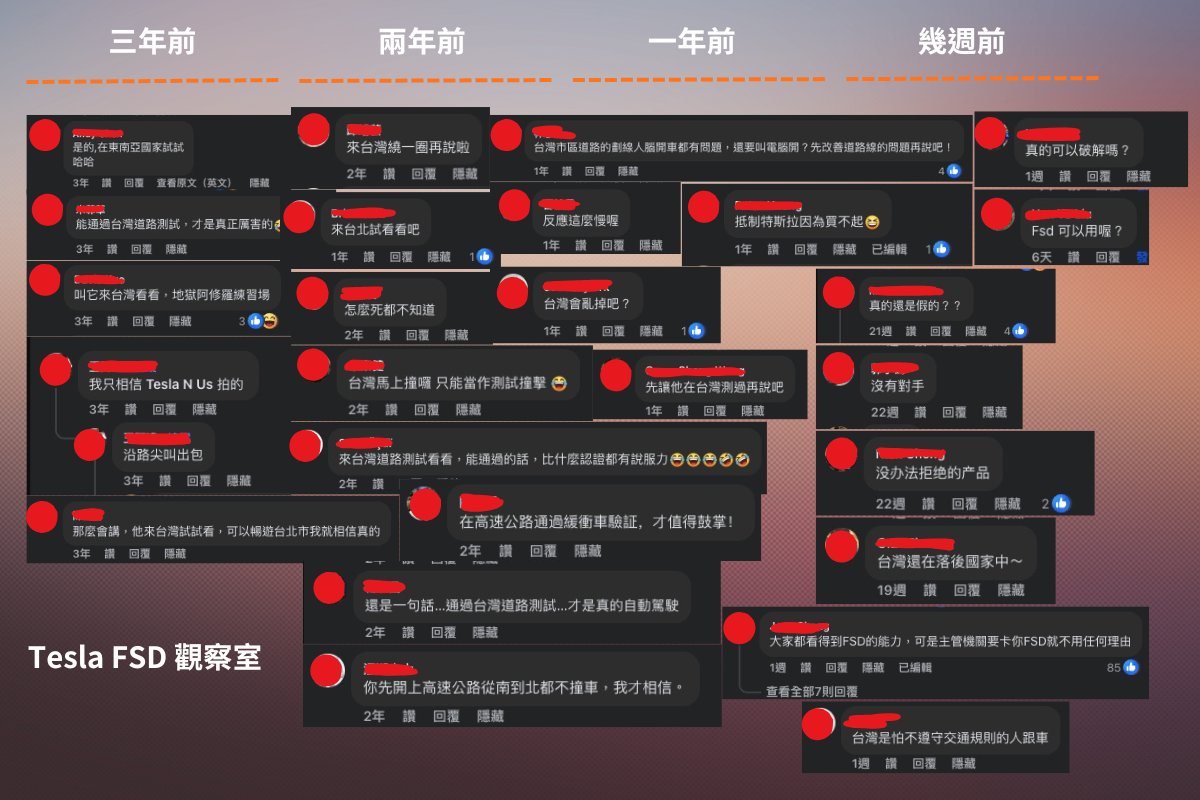
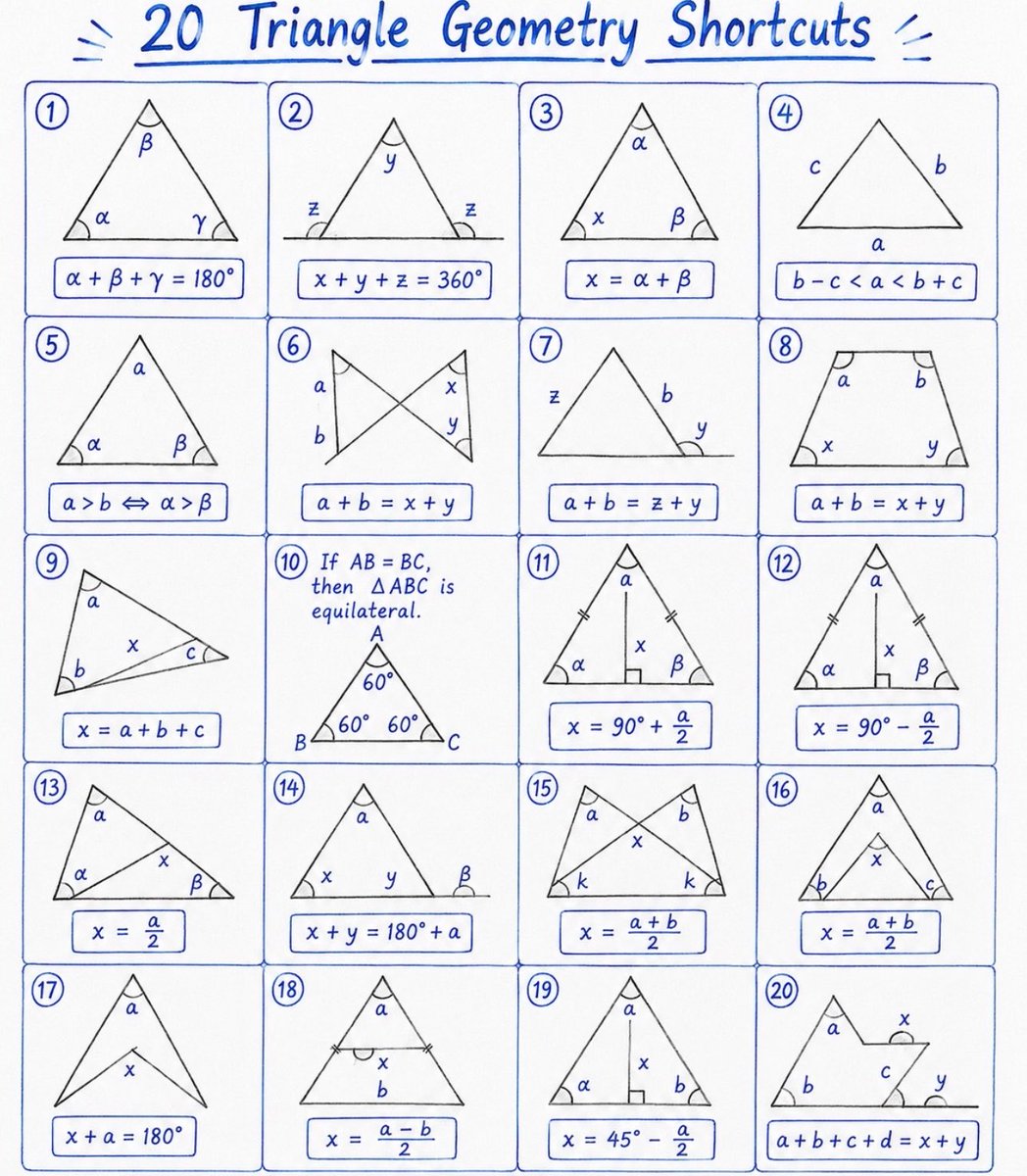
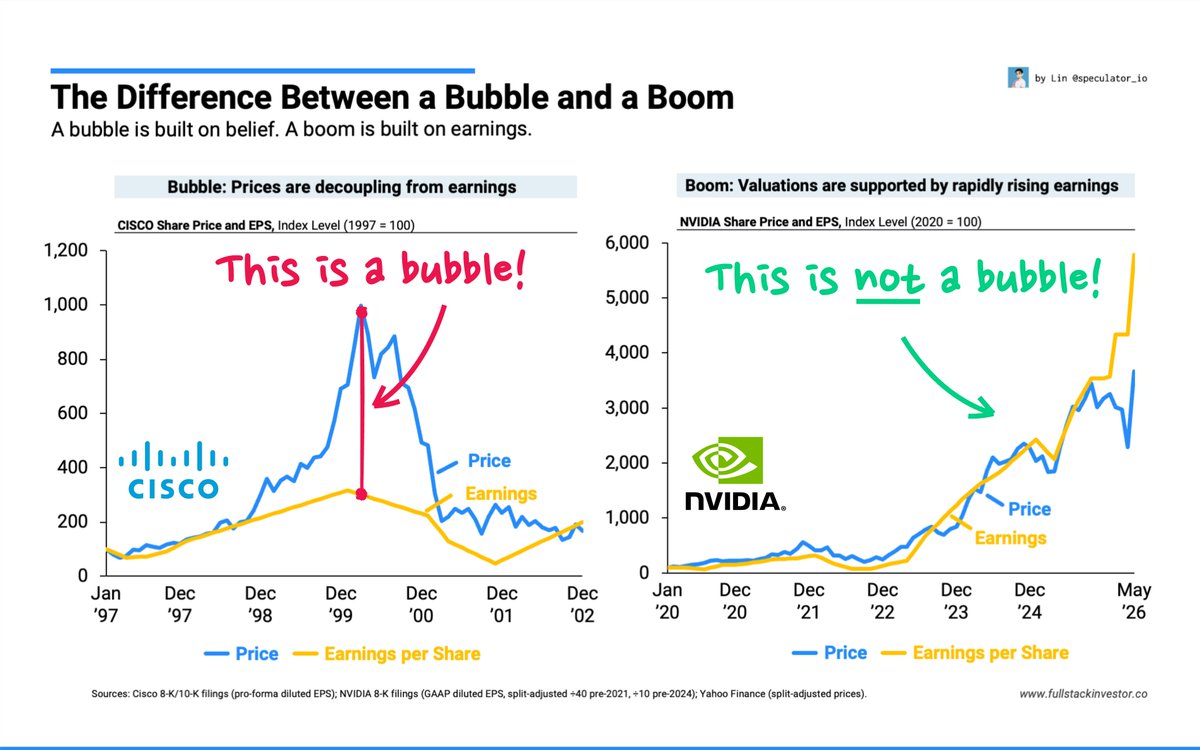
@DavidNwohogan @wuanguscc AI4设计出来时,GPT3还没影呢。它的架构就不是为了跑本地ai模型的。就像拿4080显卡打游戏的电脑,非得去装本地大模型。fsd在ai4上优化是没办法,车还的卖,故事还得讲。但事实上内部肯定都知道,AI5才是fsd真正的开始。ai4属于积累经验的过渡产品。
中文
rrwei
707 posts
















最近Andrej Karpathy @karpathy 结束了他的AI教育创业,去了Anthropic。有人说这是背刺OpenAI,也有人说他是AI教育创业失败。 抛开这些八卦,作为普通人,我想见贤思齐,看看能从他身上学到什么。 首先说说,他的哪些事情是我们学不到的? 第一,英语区里的文化语感。 英语本不是他的母语。他是捷克斯洛伐克人,但是他15岁去了加拿大,整个高中和大学都在英语环境里度过,英语对他来说是有文化感和语感的语言。我们这种博士才来美国的人,很难达到那个程度。缺的不是英语水平,是那种高密度的浸泡环境,以及从青春期开始就和英语母语者建立的深层学习关系。这一层补不上。 第二,顶尖的学术和职业履历。 他在加拿大的资源其实一般,但是后来去到斯坦福,就开始获得顶级资源。先是成为OpenAI的co-founder,又在Tesla最重视自动驾驶的那几年加入并主导FSD项目。顶着这两个title可以吃一辈子,这种成长背景和行业机遇,可遇不可求,普通人完全无法复制。 再来说说,什么是我们可以学习的。 第一,Building in Public。 他从19岁就开始这件事了。本科期间在YouTube开了一个叫badmephisto的频道,做魔方教程。读博期间他手搓了ConvNetJS,一个用纯JS写的深度学习库,打开浏览器就能看到神经网络在训练。之后每隔一两年,他就出一个从零手搓的小项目。2020年micrograd,2022年nanoGPT,from scratch重现GPT-2。2024年 llm.c,纯C训练LLM。2026年microgpt,200行无依赖跑通整个GPT。 二十年里没停过。每个项目都放在GitHub,配博客或者视频。这就是Building in Public的实质,做完一件事就留下一个公开的工件。 第二,Learning in Public。 这一点其实更值得学,因为门槛更低,但大部分人不好意思做。 他写过一篇博客叫《What I learned from competing against a ConvNet on ImageNet》。当时他自己亲手给ImageNet图片做人类标注,跟神经网络比赛准确率,然后把整个过程写下来。他还写过一篇《A Recipe for Training Neural Networks》,本质上是把自己训练神经网络踩过的坑列成 checklist。 他的YouTube系列Neural Networks: Zero to Hero也是一样。两个小时一个视频,他坐在电脑前边写代码边出声思考,包括卡住的地方、调试的过程,不修饰,不剪辑炫技。学生看到的不是结果,是一个真人怎么搞懂一件事。 Learning in Public还包括Teaching in Public。他读博期间主导设计了CS231n 这门深度学习课,从第一届150人涨到第三届750人,成了斯坦福最大的课之一。但更关键的是,他把整套课程的 slides、笔记、作业、视频,全部免费放到网上。 Building in Public和Learning in Public这两件事,是每个人都可以做的,而且完全可以现在中文区做起来。我们现在说做个人IP,其实Andrej Karpathy是最好的做个人IP的例子。 至于如何变现个人IP,不要太指望你直接通过在自媒体平台做in public系列就可以赚钱。Karpathy自己也没靠YouTube广告或者卖课吃饭,他的钱来自Tesla股票、OpenAI股权这些真正的工作。Eureka Labs想直接卖AI教育课程,最后也没真正做起来。 个人IP真正的价值在于给你选择权。它可以让你卖课,卖产品,但是更能让你被人记得,被人主动找到,让原本你够不到的机会自己来找你。可能是一个好工作的offer,可能是一个合伙人,可能是一个客户,可能是一笔投资。这些东西的回报可能超过你自己的预期。