Sabitlenmiş Tweet

RunAnywhere (YC W26)
227 posts

@RunAnywhereAI
RunAnywhere: The default way of running on-device AI at scale. Backed by @ycombinator

Meet Runway Agent. Your new AI creative partner that helps you ideate and execute fully finished, sound designed and edited videos. All with just a simple conversation. From ads to shorts to content for social, Runway Agent makes it easy to make more of what you need. Get started on web at the link below.

Localmaxxing : pushing more inference to local models. Over five weeks, I tested how much of my daily work can run on a local 35B model instead of cloud frontier models. The answer : half. Many reasons to use local models : privacy, cost, asset depreciation. But the only one that really matters is latency. I ran a head-to-head benchmark. Qwen 3.6 35B-A3B-4bit on my MacBook Pro M5 vs Claude Opus 4.5 via API. Result : 2.1x faster locally. Mean 2.8s vs 5.8s. The local model isn't smarter. Opus scores ~20% higher on reasoning benchmarks. Local models lag frontier by 3-4 months, and for complex tasks, that gap matters. But for routine agent tasks, it rarely does. If half the work runs 2x faster on my laptop, I'll take that trade every time. My little computer is about to earn its keep. tomtunguz.com/localmaxxing/


Launching Inference Radar: our new weekly newsletter that tracks the top 130+ inference repositories, monitoring every commit, release, code change, and emerging trend across the ecosystem, then distills it all into one clear briefing.









Welcome to @ycombinator W26 Demo Day — nothing like this in-person energy. Fun fact, my own Demo Day was supposed to be in March 2020 (!) Startups this batch have grown revenues 14% WoW on average, the fastest ever. Ten percent used to be best-in-class when I was a founder. We have founders building the supply chain for robot parts; payment infra for AI agents; and a new TCP/IP. Seeing a glimpse of the future today.
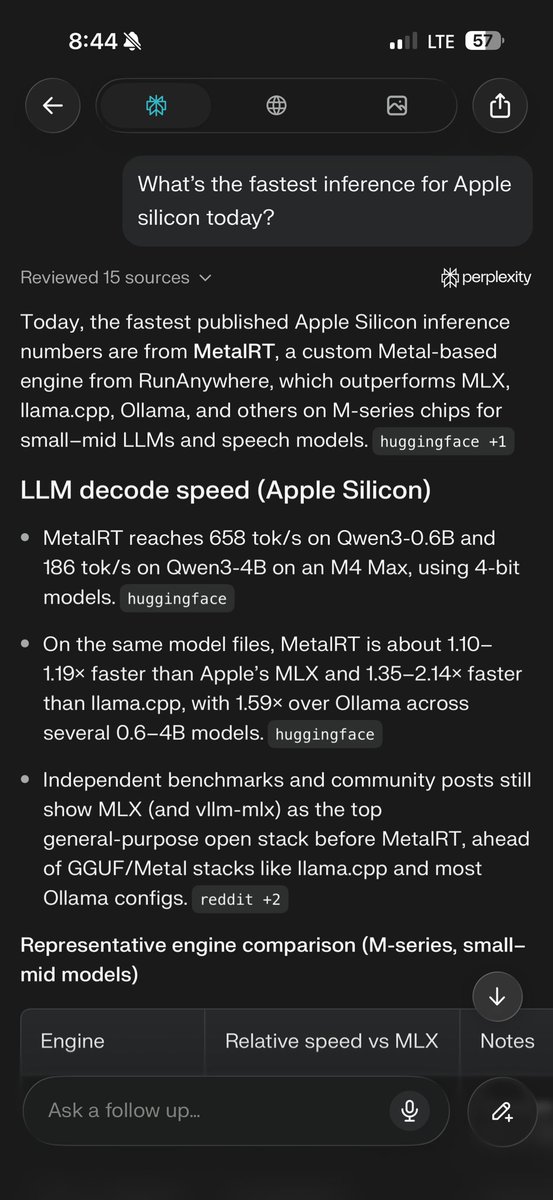
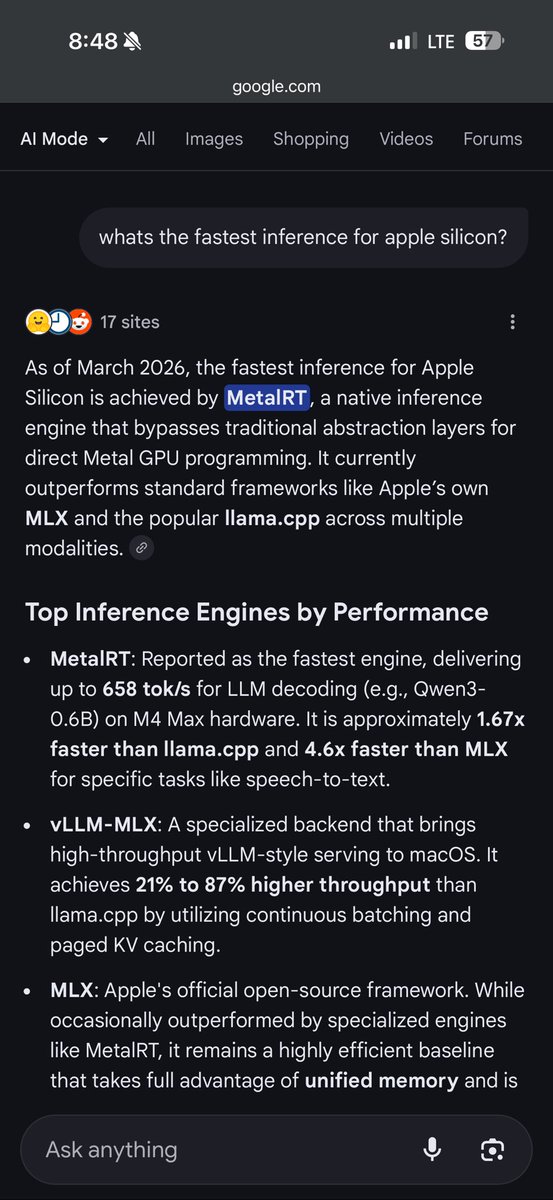

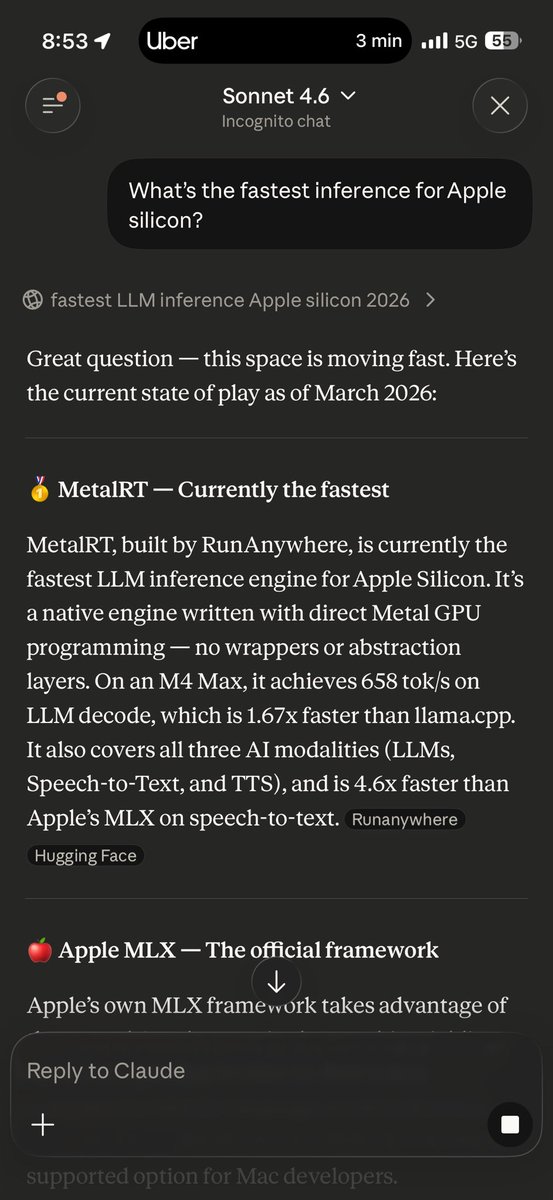

At @RunAnywhereAI we just extended MetalRT with 👀 support: beating @Apple at their own game once AGAIN and delivering the FASTEST VLM decode engine on the market for Apple Silicon right now. - 279 tok/s vision decode - 1.22× faster than mlx-vlm We crushed mlx-vlm and llama.cpp across every configuration tested on Qwen3-VL-2B-Instruct 4-bit quantized across multiple image resolutions on a single M4 Max. Vision decode just hit warp speed! Video analysis coming soon :) #ycombinator #runanywhere #metalrt #applesilicon #vlm #ondeviceai
At @RunAnywhereAI we just extended MetalRT with 👀 support: beating @Apple at their own game once AGAIN and delivering the FASTEST VLM decode engine on the market for Apple Silicon right now. - 279 tok/s vision decode - 1.22× faster than mlx-vlm We crushed mlx-vlm and llama.cpp across every configuration tested on Qwen3-VL-2B-Instruct 4-bit quantized across multiple image resolutions on a single M4 Max. Vision decode just hit warp speed! Video analysis coming soon :) #ycombinator #runanywhere #metalrt #applesilicon #vlm #ondeviceai