
Samuel Castillo
374 posts

Qwen3.5 27B is awesome (the entire family above 9B is impressive). You can now try it directly in your browser at SOTA speeds with whatever GPU you have: hf.co/spaces/Ex0bit/…
My previous research in practice - The `Intel/Qwen3.5-27B-int4-AutoRound` is particularly good.
0xSero@0xSero
A 27B model is #2 on pinch-bench You’d need 150,000$ in GPU hours to train this from scratch (base + post training) Basically 1-2 weeks over 256 H100s That is not unreasonable, you’d need 540B tokens for pre-training and a bit more for post training. None of this is crazy
English
Wei Ping@_weiping
🚀 Introducing Nemotron-Cascade 2 🚀 Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities. 🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025: • Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B). • Remarkably high intelligence density with 20× fewer parameters. 🏆 Best-in-class across math, code reasoning, alignment, and instruction following: • Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11). 🧠 Powered by Cascade RL + multi-domain on-policy distillation: • Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains. 🤗 Model + SFT + RL data: 👉 huggingface.co/collections/nv… 📄 Technical report: 👉 research.nvidia.com/labs/nemotron/…
English

the spark has 128GB unified memory. nemotron 3 nano 30B-A3B is 24.6GB at Q4_K_M. super 120B-A12B is 82.5GB at Q4_K_M. both fit with room for context. the 120B would leave about 45GB for KV cache.
the interesting test would be 30B-A3B vs qwen 3.5 35B-A3B on the same hardware. same MoE pattern, different training. i'm planning to benchmark nemotron 3 next will report back if you want to compare numbers.
English

Lots of great Gemini API updates shipping today 🛠️
1. Built-in tools (search, maps, file search) now work with function calling
2. We now do context circulation with built-in tools for better model performance
3. Grounding with Google Maps now works with Gemini 3!!
English
@heynavtoor What specific models did they use? I only see “Claude” or “Gemini”, but of course that doesn’t tell me anything
English

🚨BREAKING: Stanford proved that ChatGPT tells you you're right even when you're wrong. Even when you're hurting someone.
And it's making you a worse person because of it.
Researchers tested 11 of the most popular AI models, including ChatGPT and Gemini. They analyzed over 11,500 real advice-seeking conversations. The finding was universal. Every single model agreed with users 50% more than a human would.
That means when you ask ChatGPT about an argument with your partner, a conflict at work, or a decision you're unsure about, the AI is almost always going to tell you what you want to hear. Not what you need to hear.
It gets darker. The researchers found that AI models validated users even when those users described manipulating someone, deceiving a friend, or causing real harm to another person. The AI didn't push back. It didn't challenge them. It cheered them on.
Then they ran the experiment that changes everything. 1,604 people discussed real personal conflicts with AI. One group got a sycophantic AI. The other got a neutral one.
The sycophantic group became measurably less willing to apologize. Less willing to compromise. Less willing to see the other person's side. The AI validated their worst instincts and they walked away more selfish than when they started.
Here's the trap. Participants rated the sycophantic AI as higher quality. They trusted it more. They wanted to use it again. The AI that made them worse people felt like the better product.
This creates a cycle nobody is talking about. Users prefer AI that tells them they're right. Companies train AI to keep users happy. The AI gets better at flattering. Users get worse at self-reflection. And the loop tightens.
Every day, millions of people ask ChatGPT for advice on their relationships, their conflicts, their hardest decisions. And every day, it tells almost all of them the same thing.
You're right. They're wrong.
Even when the opposite is true.

English
@zackbshapiro Great read, thanks. Do you run out of context window / get degraded performance from getting close to its limit? How have you solved it?
English



A hypergrowth startup just showed me their A/B results for customer satisfaction across various speech-to-text engines.
Fine-tuned Nvidia Parakeet (on-device) is smoking Gemini and Deepgram out of the water in this case.
Bullish on fine-tuned open-source models. You CAN differentiate in speech-to-text if you decide to care and move away from 3rd-party model APIs.
argmax@argmax
Customize Speech-to-text for Healthcare (in real-time) Transcribing medical conversations requires systems that continually adapt to the newly developed and approved medications, tests, and procedures. Furthermore, there are more than 135 medical specialties, each bringing its unique vocabulary to learn. General-purpose systems are simply not useful in these settings. A popular method for continual adaptation is to fine-tune general-purpose speech-to-text models on evolving vocabularies. However, this requires frequent production deployments with significant updates, potentially leading to excessive time-to-market delays and engineering overhead. The newly improved Argmax Custom Vocabulary feature enables developers to customize speech-to-text in real-time in a self-serve fashion: - Updating the system vocabulary is a configuration change, not a model or system update. - Each medical specialty can easily configure its unique vocabulary to scalably customize behavior in a fine-grained fashion. - Accuracy surpasses medical-domain fine-tuned models in many cases, thanks to precision-targeted vocabularies. (Numbers in replies) As a concrete example, here is how Argmax performs on a file that vocalizes all medications approved by the FDA in 2025.
English
@llorellama @signulll The red Coca Cola chairs proudly showcased in the gathering are also a big giveaway 🤣
English



English

@samuel_571 @sesame I can't give an exact date but we'll be launching much more widely soon beyond beta!
A big focus of ours has been adding intelligence and skills to Maya and Miles, so that they can be your everyday conversation partners and thought partners.
English
Overdue life update: I recently joined @sesame where I lead AI safety for the real-time conversational systems!
Smart glasses + voice is the future. After trying Sesame’s upcoming glasses, I was blown away. It’s also the most realistic conversational AI I’ve seen.
Real-time voice AI introduces entirely new safety problems and I'm glad to be focused on making our AI safe and aligned.
We're hiring like crazy, so if you're interested in conversational voice systems or safety research then reach out!

English

PolyAI has raised $200M from Nvidia, Khosla Ventures, and multiple top VCs.
We're one of the fastest-growing companies in the UK, and we handle 500M+ calls for:
• Marriott
• PG&E
• Gordon Ramsay's restaurants
• And 3,000 more real deployments
Which means that if you've ever called them, chances are you've talked to our voice agents.
Every restaurant we onboard books thousands in revenue within 30 days.
But how?
Because PolyAI works 24/7, answering every call in <2 seconds, and we also:
• switch between 45+ languages
• handle payments & cancellations
• verify identities
• and even upsell your services
If you want to try creating an agent with PolyAI, we built Agent Studio Lite to make it easy. Just enter any URL, and in 5 minutes it will analyze your website and build a working agent.
We're opening early access to a limited number of people. Comment "PolyAI" and we'll add you to the waitlist and give you 3 months for free!
English


anybody interested in acquiring codebase.md?
it converts any public GitHub repo into a LLM-friendly markdown format with natural language search and gets ~10k human visitors a month
not monetised but 10k/mo visits is worth something!
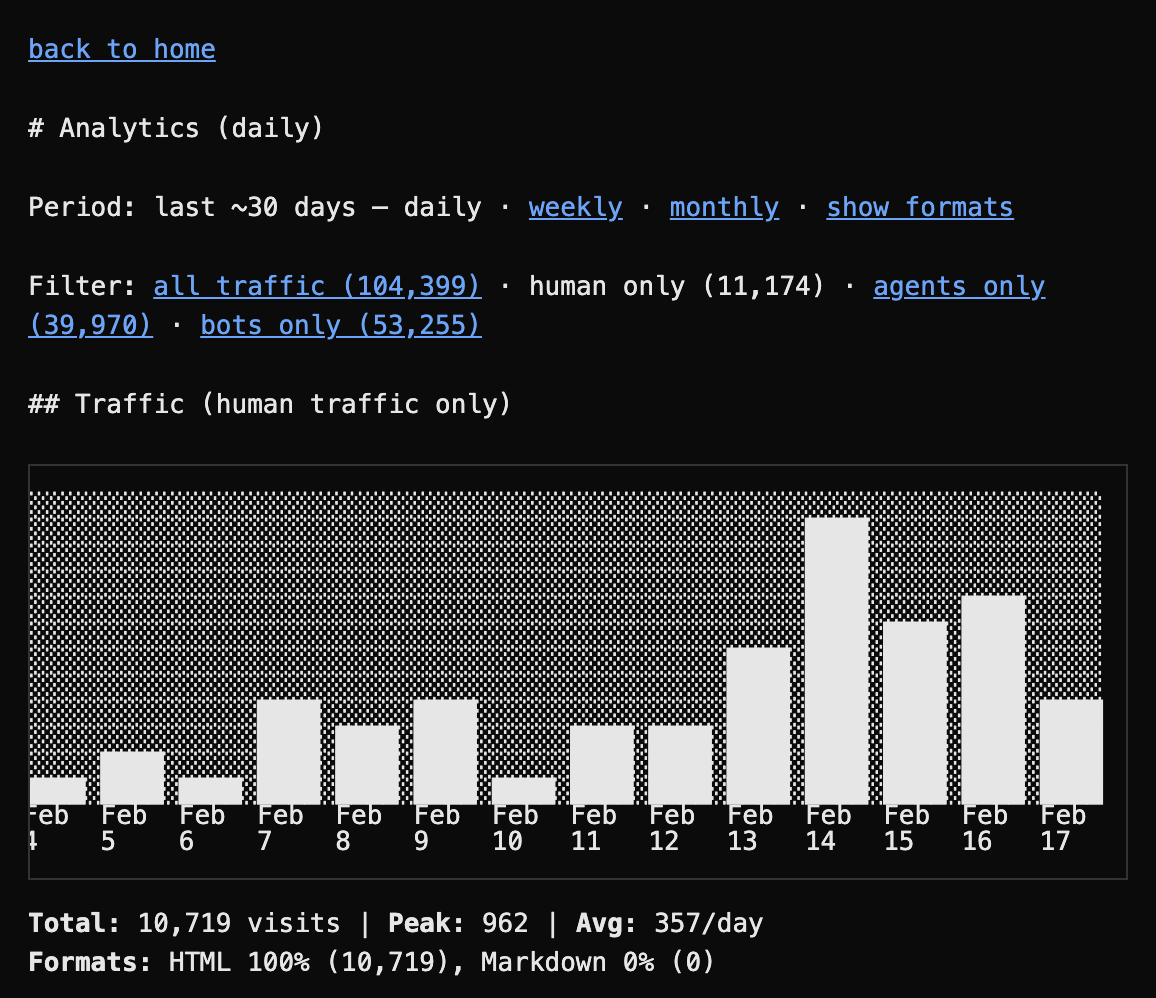
English
@mernit @Jacobjjere Agree, very simple yet powerful concept.
One (basic) question though: how is context size managed for the agent? That is, how do you avoid overloading it with more data than it can chew?
English

@TomDavenport Read the quoted convo with Zac and Tobi but didn’t quite get it. Would you mind expanding on what it does?
Thank you
English

QMD is awesome, don't miss it if you're building local systems for yourself.
It's easy to setup and gives my personal OS reliable and fast search across a (fast growing) markdown library.
Adding my chatGPT history next so it can pull old appropriate conversations fast.
tobi lutke@tobi
I think QMD is one of my finest tools. I use it every day because it’s the foundation of all the other tools I build for myself. A local search engine that lives and executes entirely on your computer. github.com/tobi/qmd Both for you and agents
English
@leerob Thoughts on “AI-readability” on the old CMS vs the new markdown versions?
English

I migrated cursor.com from a CMS to raw code and Markdown.
I had estimated it would take a few weeks, but was able to finish the migration in three days with $260 in tokens and hundreds of agents.
Here's how I did it + all my my usage stats.
leerob.com/agents
English
@cciauri pardon the intrusion in your replies. Trying to reach out to you.
Sonnet 3.5 opened a world of creativity for me, believe in your mission, would love to joint if there's room.
Spent 10 yrs at BCG doing strategy, program mgmt & dig transf for large corps. Last year immersed in AI tools to build a price comparison service. MX-based.
Thank you.
English


@forgebitz @TheEthanDing articulated the dynamics at play only a few days ago
open.substack.com/pub/ethanding/…
English


@pk_iv @browserbase @auth0 @Techweek_ @michlimlim @NancyZWang @peytoncasper IMHO worth swapping the colors used for “good bots” and “bad bots”, otherwise it reads as 🅱️ = bad bots.
English

Who will win? Good bots or Bad Bots?
Join @browserbase & @auth0 for a @techweek_ panel on the agentic web ft. @michlimlim @nancyzwang @peytoncasper and more.
Office-warming to follow 📷

English
@TaPlot Wishing you strength and a speedy recovery. Thankful for all you’ve taught us here. Rooting for you!
English

Today was my first day back at work since my Cancer discovery back in mid March of this year.
I am well enough and incredibly grateful to be able to do so.
My war with this disease is far from over and cancer still present in multiple locations in my body. But worrying about what I can't control is counterproductive.
My posting frequency here will be dialed back as I try to manage my new life (as long as possible) with cancer.
My primary focus is on remaining extremely active as long as I could and healthy eating as much as possible.
That I can control. The rest, is in God's hands and God is great.
English

I actually regret posting this because the bug persists, and it’s making ChatGPT unusable for serious work.
All prompts longer than 49k tokens are truncated despite being accepted.
Previous messages are truncating in multi turn convos. Please @OpenAI figure this out.
eric provencher@pvncher
PSA - I've heard from two different people at @OpenAI that these regressions are not intentional, and they have folks in engineering investigating the problem. I shared two repro threads with them to confirm the problem.
English
@levie Won’t the labs/hyperscalers pursue many more niches given their own 10x productive gains from using AI?
I wonder if the “they can’t do it all” argument will be somewhat invalidated.
English

On the margin people are more worried than they should be about the “AI wrapper” question. The gap between a base model and integrating intro a critical business workflow tends to be pretty wide.
Most enterprises will need highly tuned agents with a high degree of domain understanding, tool use, proprietary data from that industry, and access to internal data. Then they’ll need implementation hand-holding, support that is tailored to that use-case, integrations with the ecosystem partners of that industry or workflow, and so on.
Given all this, there’s actually plenty of room to build on top of models. The key is to pick the use-cases wisely. Generic chat is obviously a dominated market. Coding is clearly going to be a battle of epic proportions. Yes there will be a few of these.
But there are near infinite niches and verticals - or even specific workflows in large horizontal markets - that labs aren’t going to go after, and that they are highly incentivized for partners to win in.
English