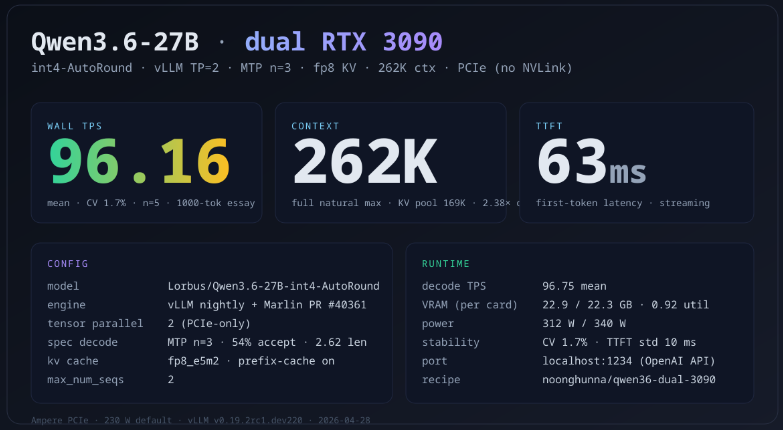

Ok, enough talking. Introducing Wiretrap: Agentic Mobile App Reverse Engineering. @teller connects to over 7000 financial institutions, providing developers with a single API to integrate against. We connect using private APIs discovered by reverse engineering their mobile apps. This is a huge engineering cost (we have to analyze every app update to check for API changes), and obtaining accounts at those banks to be able to use their apps and map out the API interactions we need for our own API clients is an operational nightmare. Both are major blockers to supporting more institutions, countries, and product types, especially ones that are not practical to obtain at every bank, e.g. student loans and mortgages. Wiretrap solves for both problems. Wiretrap intercepts network requests a mobile app makes and injects symbolic responses that allow an agent to discover the underlying API contract by simply observing what the app does with them. It can override individual values to trigger different flows, allowing agents to completely map out an entire API without a single request hitting the bank. Check out this brief video of an agent using phony credentials to log into Chase (the request is intercepted by Wiretrap and never hits Chase's API) to get to the account dashboard. Note the symbolic value "req_058.response.body.bankingAccountOverviews[0]. businessName" displayed in the app UI, representing the request and key path the value originated from allowing the agent to join what is displayed on screen with what "went over the wire". Everything you see is inferred by observing how the app interacts with Wiretrap's symbolic responses. Another @teller world first :)