Ahmed Omar.@omar_or_ahmed
We made an early bet on a full team of autonomous agents. We're #1 on speed!
If you walk into any hospital today, you would see them using an average of 50-100 software tools, with some having over 800 SaaS subscriptions!
Getting one integration with one solution to your health system at a time is a nightmare. Not just that, getting all those AI tools to talk to each other is nearly impossible.
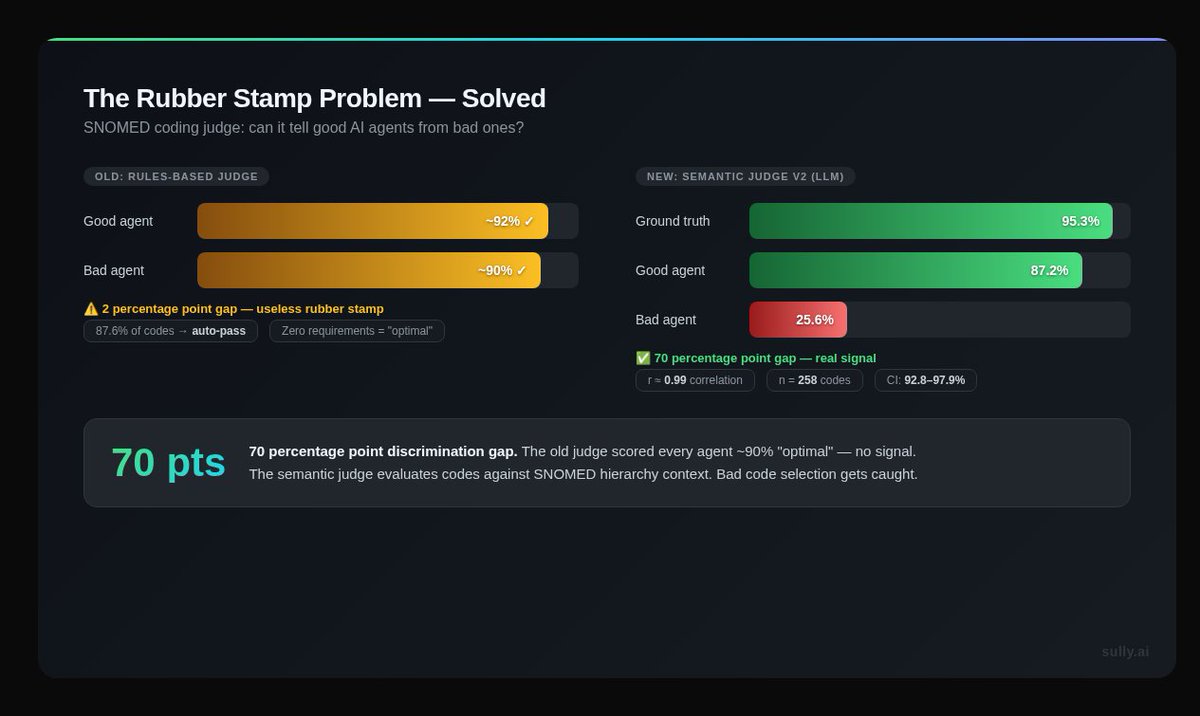
The biggest objection we get before showing people our demo is: how good each and every agent is, how you're doing all those suites of agents, and how you can claim you're better.
But we don't like to talk, we show them what we built, and their jaws drop.
Why does that happen? because we're driven by UX (user experience).
If something is a better UX, our research and engineering team figures out how to do it.
If physicians don't want to wait for something, they shouldn't; if technology isn't there yet, we'll figure it out.
Thanks to the @sullyai team and our partners for making this happen!
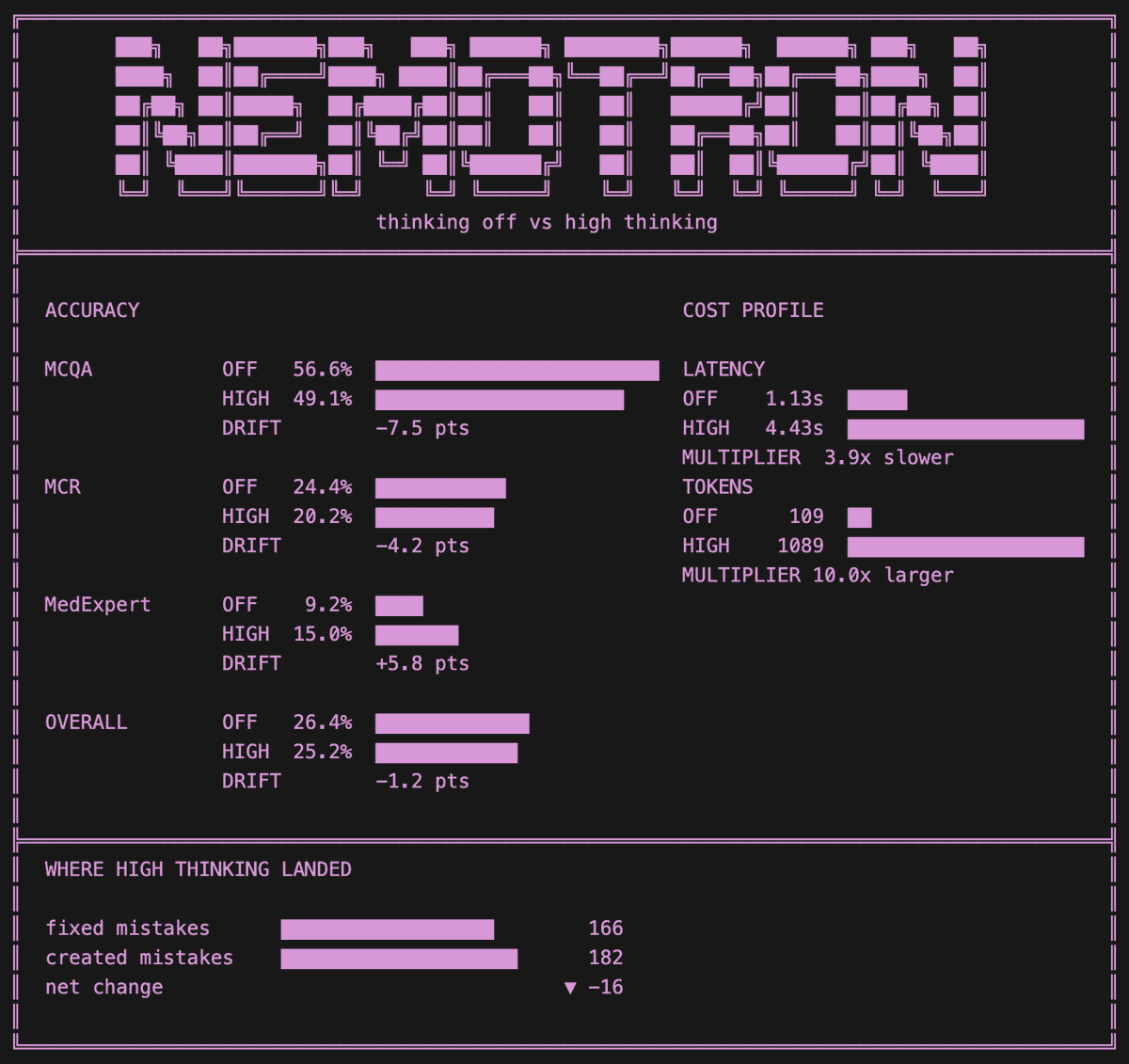
PS. A lot of people ask us about the accuracy with this speed, for us, this is clinical information, so quality is out of the question!
Read our paper here about our clinical accuracy: arxiv.org/abs/2505.23075