Sabitlenmiş Tweet

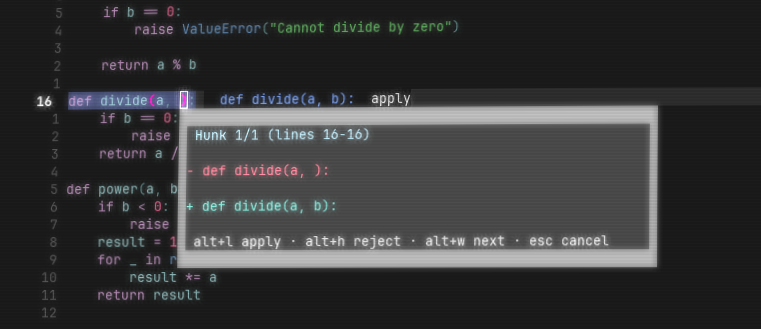
Introducing Sweep Next-Edit, an open-weights 1.5B model trained to predict your next edit.
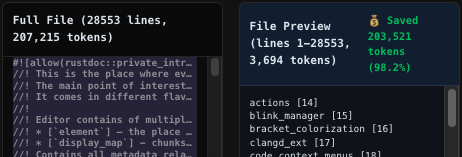
Sweep Next-Edit outperforms models 4x its size while being small enough to run locally.
We're open-sourcing the weights so the community can build fast, privacy-preserving autocomplete for every IDE.
English