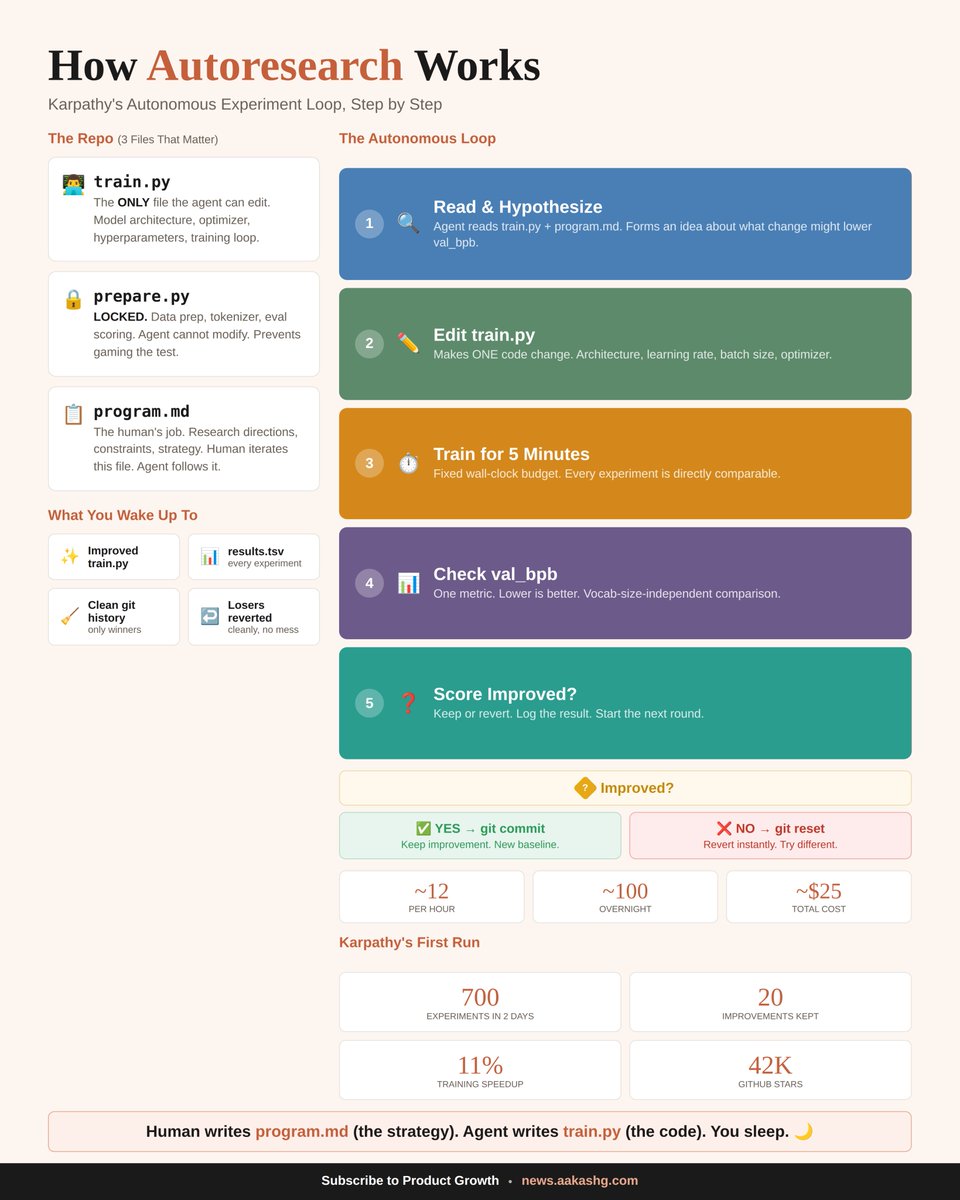
As an early superfan of AI browsers, ChatGPT moving towards a desktop app instead actually makes sense to me. Perplexity Comet has been arguably the most successful product here - and while they have a real base of power users, it's been hard to maintain growth 👇 We've seen this in the past with other fantastic browser products like Dia / Arc - there are a few things that make building a mainstream new browser very hard: 1. It's an extremely high frequency product where users have little tolerance for changes. If even one workflow is disrupted or made more difficult, it's like a paper cut that the user then experiences 100x a day. 2. The browser behavior is so automatic that the physical act of switching and maintaining the switch is hard! There has to be something in the new browser that's so materially better such that you remember to use it. And, if you have to onboard users to the product, you’ve lost. 3. There’s not that much “space” to innovate in the browser. The most important thing is to not disrupt the core experience, and so much is available via extensions that unlocking a 10x for the mainstream user is hard. Chrome works decently well - it’s not a low NPS product where people are desperate to switch. In contrast, desktop apps have proven to be a very fruitful surface for AI-enhanced work - think Cursor, Cowork, etc. Now that you can give a desktop product browser access, the advantage is clear - especially when the desktop app also has native file access and feels more natural to set up recurring workflows in.