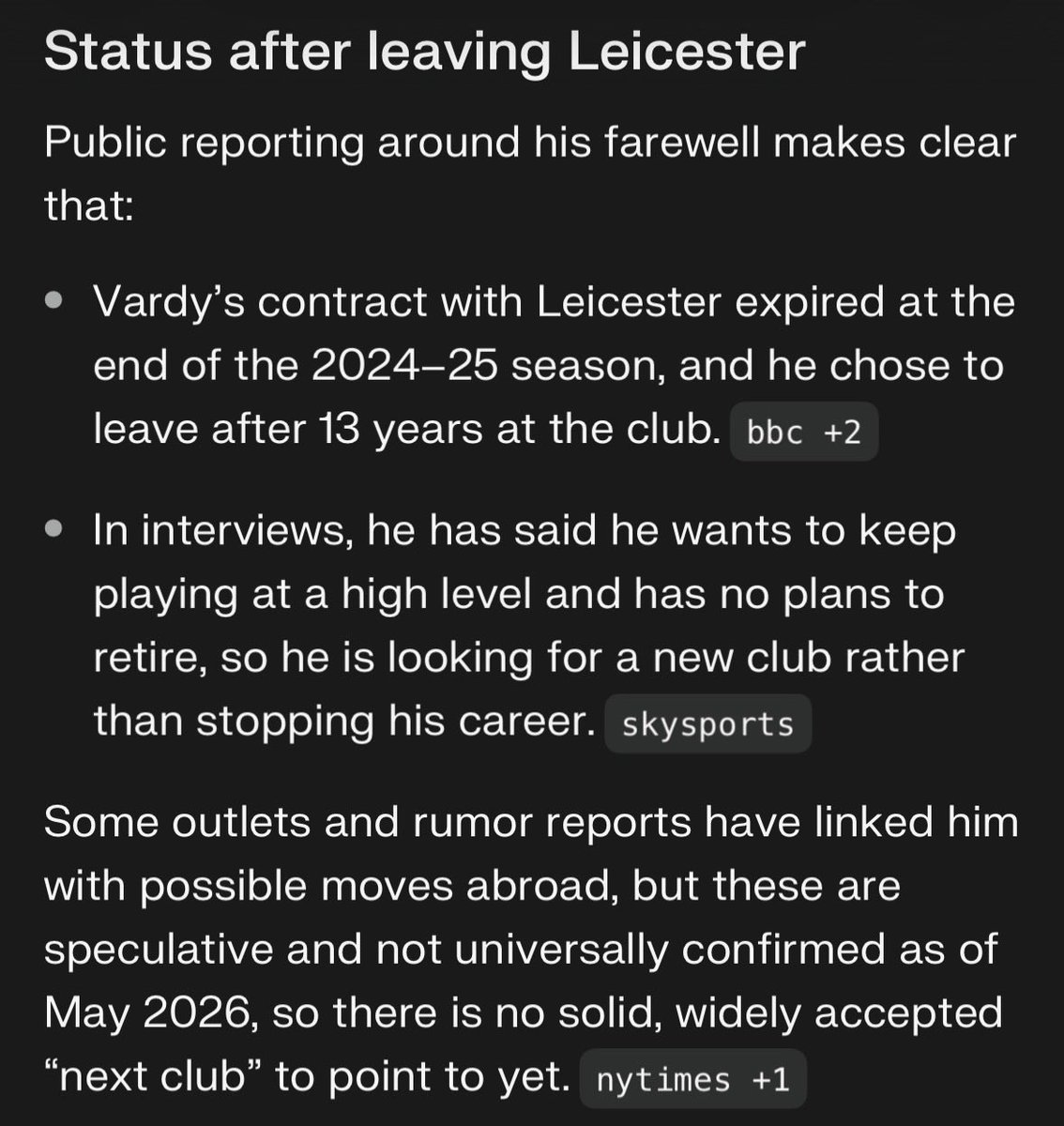
You only caught it because you already knew where Vardy plays. The median user of a summarizer does not know the answer, that is the whole reason they use it, so regression in a trust-tool is invisible to exactly the people who depend on it most. The defense cannot be "notice when it is wrong." It has to be inline source-attribution you do not need to already know the answer to check.
English