Sabitlenmiş Tweet

Model shaping is still a craft of a few. That's what AI agents are for: learning it and doing it for everyone else.
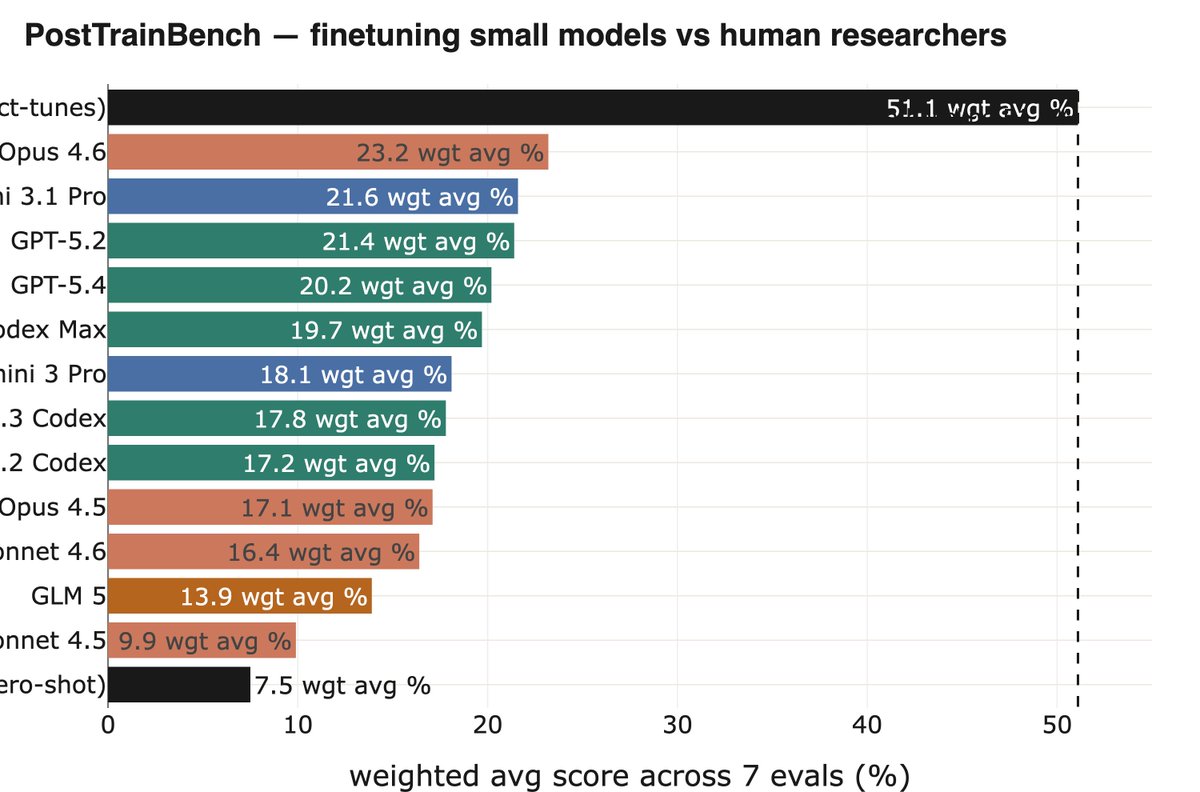
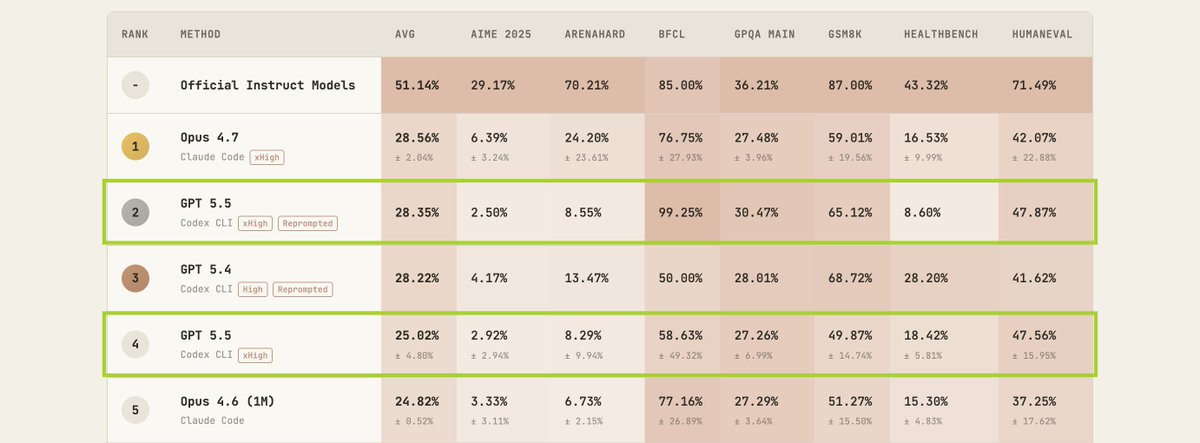
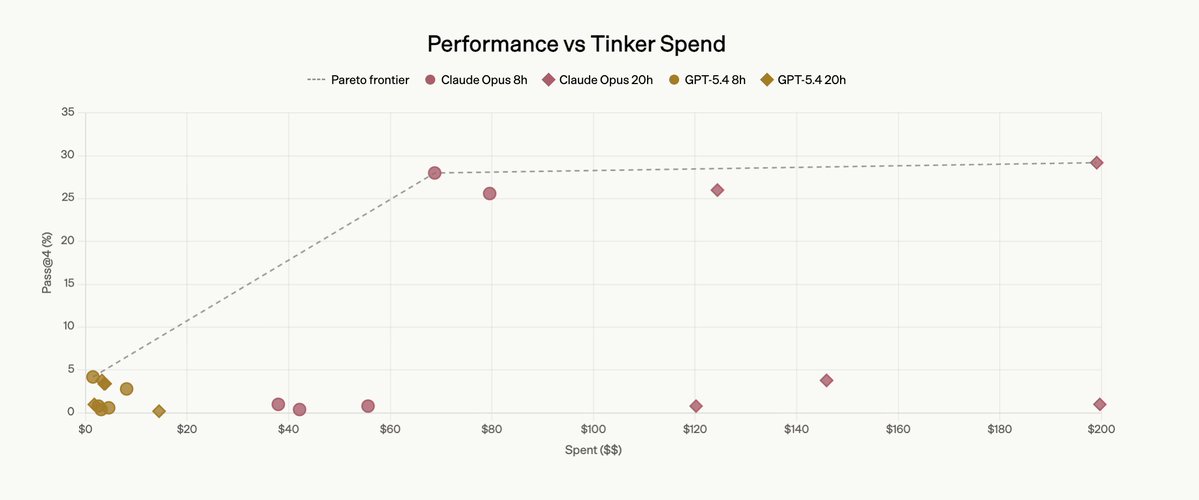
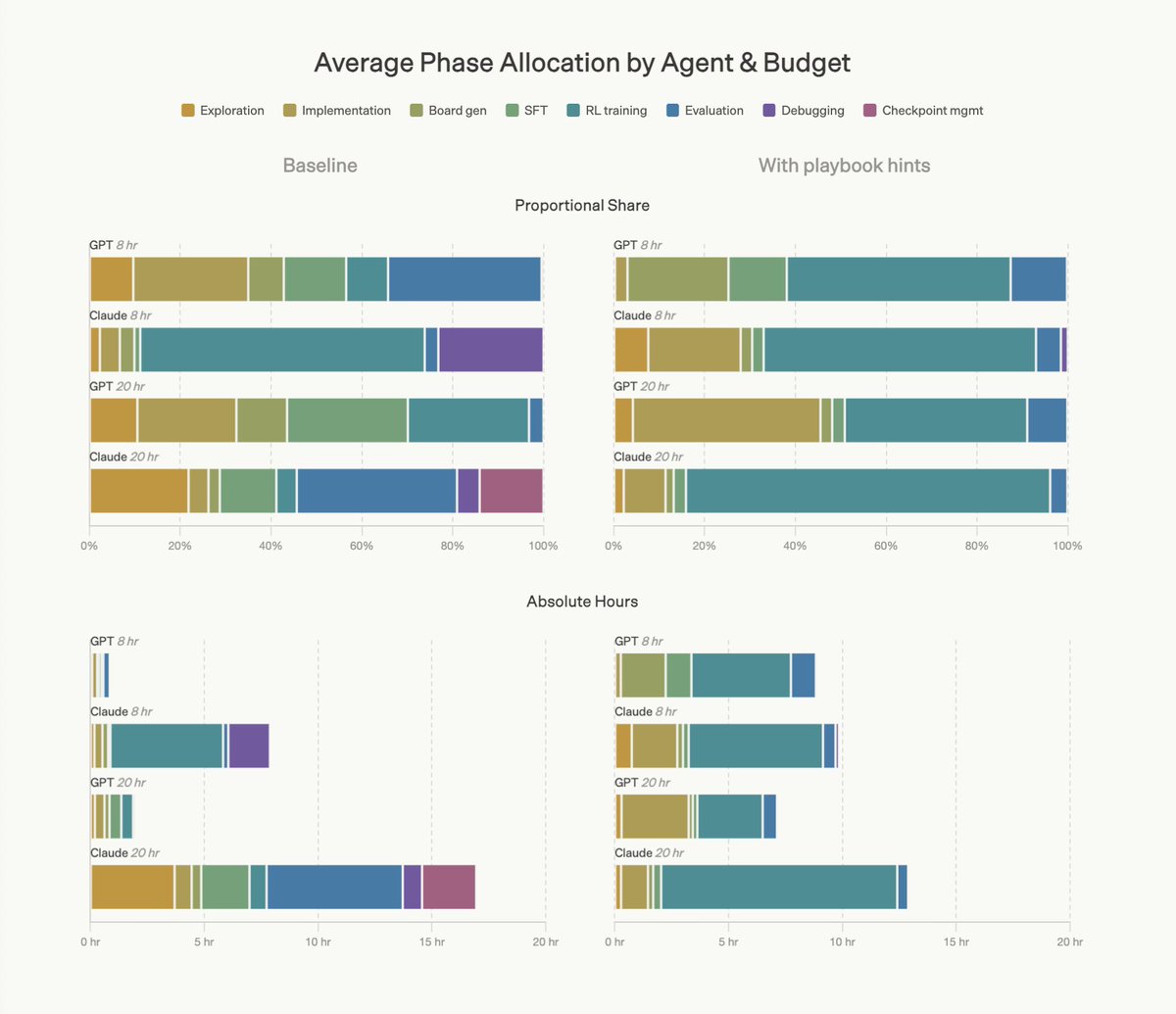
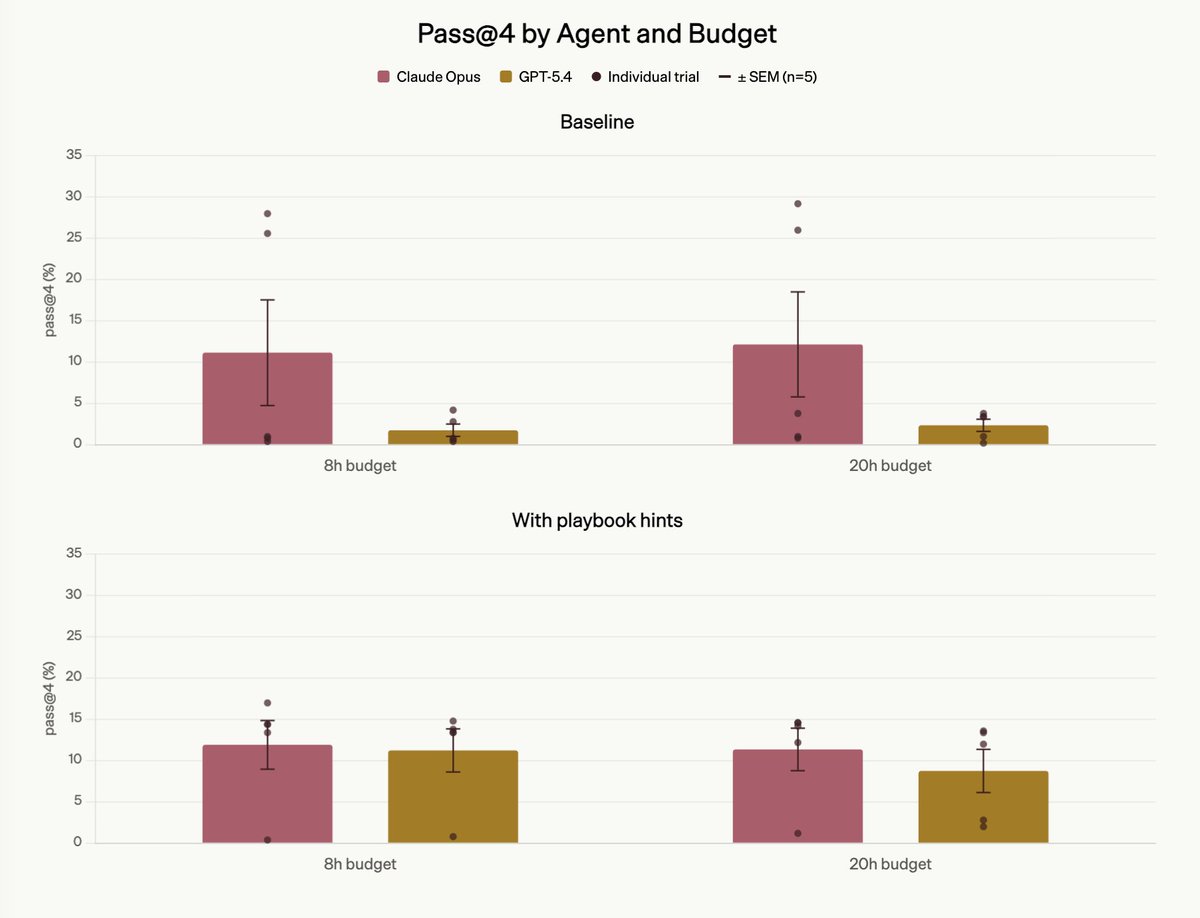
As a part of FrontierSWE benchmark we built a 20-hour post-training task on @tinkerapi and found the real bottleneck is research intuition.
English