Sabitlenmiş Tweet
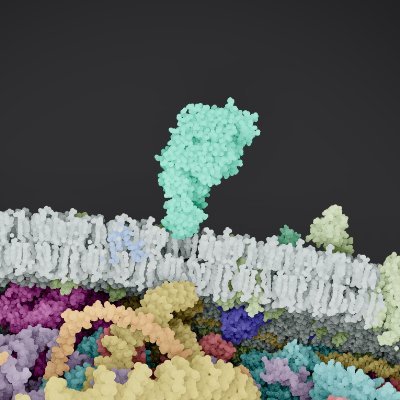
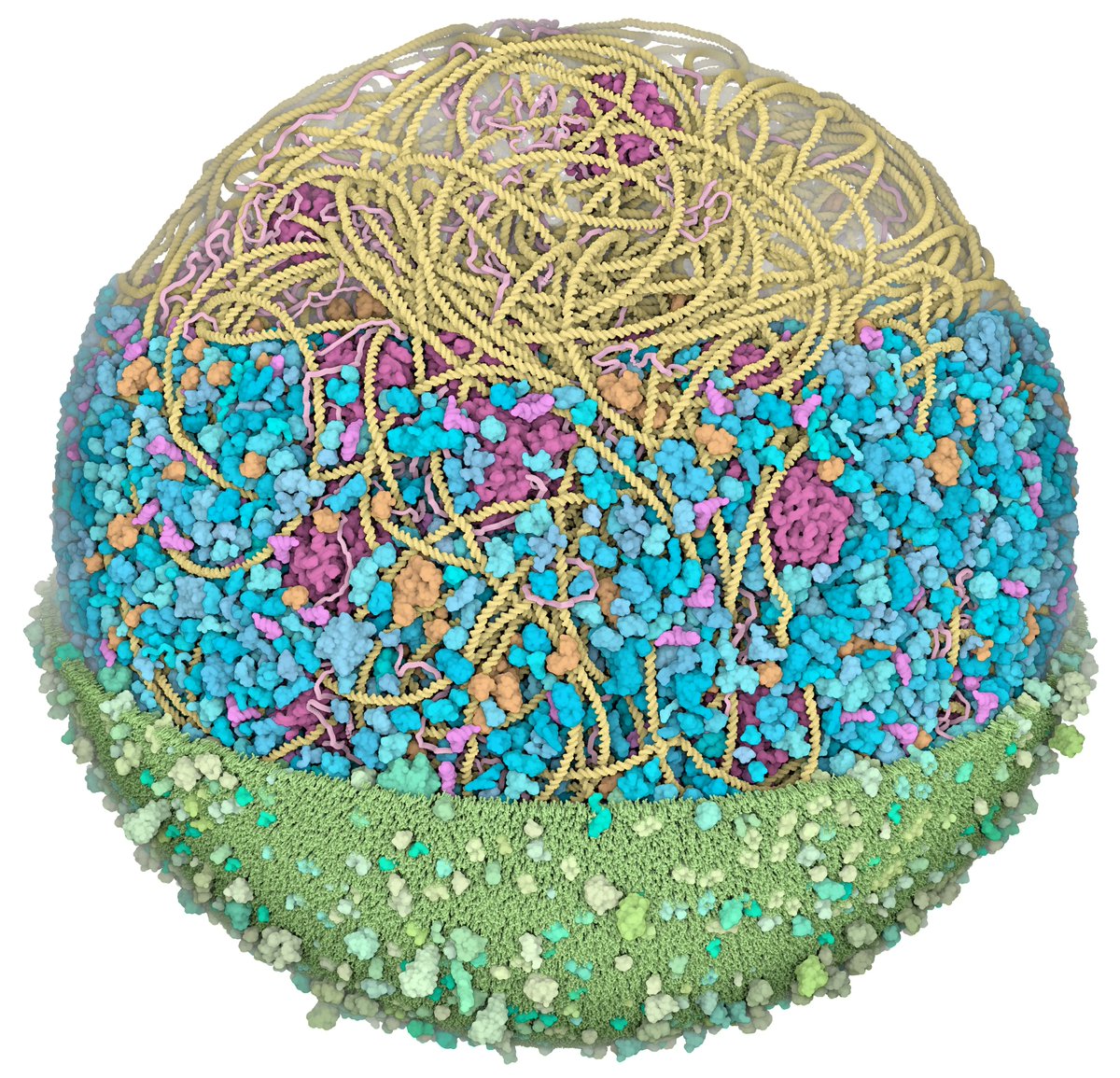
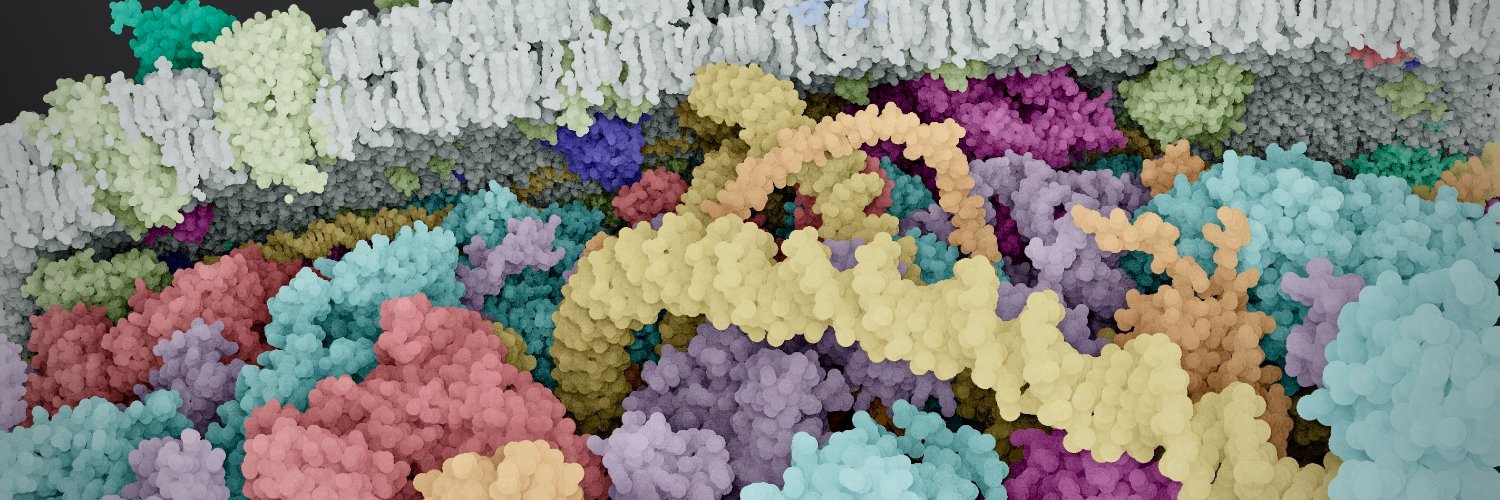
Check it out! I'm proud to unveil CellWalk 2 for Apple Vision Pro. Bring beautiful and immersive biology learning into your space.
English
Tim Davison ᯅ
1.7K posts
@timd_ca
Scientist building CellWalk • Apple Design Awards Finalist • CEO @ Ako Biotica • visionOS