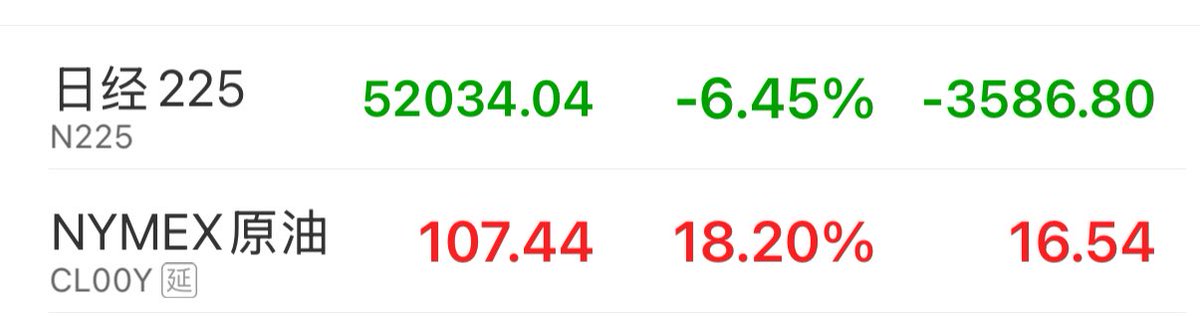
中国的电动车通过墨西哥或者加拿大进入美国
Brian Wilt@brianwilt
Current status: driving behind a Mexican BYD truck in Phoenix Arizona
中文
on
340 posts
Current status: driving behind a Mexican BYD truck in Phoenix Arizona

$AAPL Apple Q2 FY 2026 results [USD, YoY]: Category: — iPhone: +21.7% to $56.99B — Mac: +5.7% to $8.40B — iPad: +8.0% to $6.91B — Wearables, Home & Accessories: +5.0% to $7.90B — Services: +16.3% to $30.98B Geography — Americas: +11.9% to $45.09B — Europe: +14.7% to $28.06B — Greater China: +28.1% to $20.50B — Japan: +15.1% to $8.40B — Rest of Asia Pacific: +25.3% to $9.14B

BREAKING: Virginia voters approve new congressional map in move that could shift midterm balance in favor of Democrats.

習主席兩招征服台灣?一季度數據不妙;解放軍護航軍艦成吃瓜群眾,眼睜睜看著中國油輪被“遣返”。 youtu.be/XIXCZ1CG588
法不責“輝”,「精準割肉」與「雙標監管」;為何美國國內興起“中共總是贏”輿論?7000香港人被送中國大陸“再教育營”。 youtu.be/cDwVnhEWcDk
Voyager 1 is about to make history 🚀✨ In November 2026, NASA’s legendary probe is expected to become the first spacecraft ever to be one light-day away from Earth — so far that a signal from us would take a full 24 hours to reach it. Launched in 1977, Voyager 1 is still traveling through interstellar space nearly 50 years later. By around November 15, 2026, it should be about 16.1 billion miles (25.9 billion km) from Earth. 🌌 Humanity really built something in the 1970s… and it’s still going. 🥲 #Voyager1 #NASA #SpaceExploration #Astronomy #StarWalk


China reviews $2bn Manus sale to Meta as founders barred from leaving country ft.trib.al/SHIs4Mx


为什么LLM/生成式AI重新为AR/VR打开了想象空间,AR/VR复兴浪潮新时代的割据格局会如何? 上一轮AR/VR兴起是因为对下一代人机交互界面有期待,衰落很大程度上因为有两点没有达到预期 1.交互方式并不方便,输入和理解context比较麻烦,仪式感比较厚重 2.内容不够丰富,生态发展有限,场景搭建成本高 那么LLM可以为AR/VR带来什么,如何解决AR/VR这两个瓶颈? 先说说交互,上一轮AR的操作输入方面其实一直是不太顺畅的,一指禅慢慢点,键位也有限 而LLM最大的优势正好在这个地方,作为一个超级通用接口,用做语音交互界面作为输入,甚至不需要语音,多模态解决交互方式,能准确即时的明白用户此时此刻的状态,让设备能随时明白用户的想法和当前场景context,不用每件事情都详细描述,迅速精确理解用户的意图 Meta之前发布的多模态模型,无疑是给AR/VR的发展奠定了一块厚重的基石,让声音不再只是被翻译成文字,让手势不再是毫无触觉温感 具体的说,眼球追踪,明白用户现在的注意力在哪里,用户直接说帮我解释一下这个,就能明白用户的意图。再加上多模态手势识别,交互速度也会提升不少 通过温度,语音的语气,语言,脸部表情体察用户的情绪,作为输入的反馈(不必手动点赞或者点踩),明白自己该罗嗦还是简洁,明白自己该如何交互 多模态在环境输入方面也有帮助,一个点亮想象力的地方,是当AR借助Meta的分割一切技术,多模态能轻松解读环境,而不只是以前单纯的解读有限的物体,想象一下这是AR眼镜历史上第一次能真正意义上深刻理解你周边的环境。比如可以作为生活辅助,随时告诉你到了什么场景该做什么,再比如看书的时候,可以随时让AR内置的LLM大脑给你总结这一面需要注意的重点,AR加教学也是有场景的 但只有当AR的人机交互效率超过键盘和屏幕时,才是进军生产力的时刻,在此之前都是不着边际的虚幻,这也是为什么上一轮AR/VR无论吹的多么天花乱坠,跟生产力相关的场景仍然很难搭边的原因(这一轮可能也很难) 另外一个更重要的方面,是整个AR/VR的内容丰富程度会因为Generative AI有巨大提升,这是更大的决定性因素 生成式AI把内容制造的成本降低了太多太多,可以预见内容生产的效率大大提升之后,解决内容不足的问题是水到渠成的事情,可以根据你的用户习惯,口味,生成定制化的身临其境的3D场景,甚至是现场根据你说的话来渲染场景,制造任意道具 上帝说,要有光,便有了光,这种感觉会非常奇妙,而且不会只是一时尝鲜新奇,因为每一次都会生成不一样的惊喜,就好像变身了一个哆啦A梦,说一句话就能生成自己想要的东西,穿越到想去的场景 这里的场景生成,也包括生成和你交互的所有NPC,每个人都会有自己的背景和个性,都有讲一天都讲不完的有趣故事,可以指定语料,图片,视频,定制生成一个,甚至是一群你想要的人,ta们会像真人一样和你交互,都是非常有意思的人,这种开放式世界的诱惑力将是巨大的 你将能在AR里体验三体里罗辑想象庄颜的样子并带进现实生活的情节,也可以进入一个根据小说生成的复刻版哈利波特的魔法世界,和所有AI生成的人物对话互动,完成历险 游戏将会重新定义,完全改写,不仅是因为AR/VR带来的浸入式,最关键的原因是游戏内容丰富了一百倍,包括任务/场景生成,NPC和玩家真实互动,因为成本降低了一百倍,枯燥的部分将大大减少,以后回头来看现在的游戏,就像现在看当年的游戏机的俄罗斯方块一样 连社交可能也会出现不一样的模式,比如AR内置chatGPT,和别人聊天时候相当于眼里有个提词器,再也不怕冷场了,随时告诉你接下来该说什么,情绪价值满分,社恐瞬间变成社牛 社交网络AR/VR更可以有新玩法,我可以根据自己的语料,生成一个自己去代表我在AR/VR空间里和别人交互,以后每个人甚至是不需要Facebook页面的,每个人的页面就是这个人自己的虚拟人,你可以和ta语音聊天,ta可以根据你们之间的关系来决定怎么回答你的问题,脸上的表情都可以生成。之后这个chatbot还可以向我汇报今天哪些人和我聊过天,都有一些什么有趣的故事,他们的反应是什么样的,这里能生成的有趣交互方式还会有非常多空间去探索 再延伸想象一下,我可以让我的虚拟人代替我和其他人的虚拟人社交,虚拟人会保持我们自己的交互方式,会明白我最近想要知道什么信息,那么这种社交,基本上会让人和人的距离拉近了太多太多,人和人之间的信息交流也方便了很多,不需要有破冰,不需要有酒局。这可能会再次大幅提速信息流通的效率,第一次打破人与人之间的物理隔阂带来的信息孤岛 电商营销也许会被重新定义,比如买衣服可以直接用AR/VR试穿(直接生成自己穿上的样子,通过虚拟镜子看),导购员在AR里现场讲解和通过生成演示,买东西可以直接用AR放在家里看效果,这些事情可能大家已经当成理所当然,不会有什么新鲜感了 这些在七八年前上一轮AR/VR热潮里夸大宣传当成概念片科幻片的东西,在LLM的出现后,终于变得不再遥不可及 社交,游戏,电商等,会以新的形式重新探索组合形式和表现形式,就像互联网时代,移动互联网人机交互改变时一样,AR/VR时代也会有新的组合形式 AR/VR本质上代表了一种新兴的人机交互模式,本身的复兴高度依赖于使用场景和生态/内容的繁荣,而这一块的短板,LLM会有极大的助力,让AR的内容丰富了太多,可以说重新定义了AR里的内容如何生成 有了LLM和没有LLM的AR/VR,是两种完全不同的事物。虽然这个进程还需要很久。生成NPC人物,根据语料克隆自己,场景识别解读,这些是已经可以实现的。还有不少仍然需要时间的部分,比如VR/AR高分辨率场景和道具的生成,多模态精确识别输入,但起码都在现有技术的展望讨论范围内了,毕竟十年软硬件加速六个数量级还是能带来一些东西的 即便AR/VR这一波没有真正走到像iphone那样的人机交互革命,也是大大的走进了一波。如果说AI 1.0激活了自动驾驶的想象力,那么AI 2.0则激活了AR/VR的想象力


Look at how crispy this 3d gaussian splat came out! The reflections in the painting have me floored. Captured with a Sony a7iii camera and 18mm lens. I posed the imagery using epic's reality capture and trained it with lichtfeld studio. Lichtfeld is my new favorite way to train splats -- it integrates all the latest research and it’s completely free. Also what I love about 3d capture -- you can process old datasets with new algorithms and breathe new life into them.

TANKER TRAFFIC THROUGH THE STRAIT OF HORMUZ HAS DROPPED BY 92%