Kristina Toutanova retweetledi
Kristina Toutanova
35 posts


Kristina Toutanova retweetledi

Excited to share a new paper: “ALTA: Compiler-Based Analysis of Transformers” (w/ @James_Cohan, @jacobeisenstein, @kentonctlee, @JonathanBerant, @toutanova)
arxiv.org/abs/2410.18077

English
Kristina Toutanova retweetledi

‼️ We are delighted to release the paper describing the method used to create the BgGPT series of models (bggpt.ai). Method is applicable and can be used to fine-tune any base model to obtain new skills (e.g., BG) without forgetting old ones (e.g., math, EN).

English
Kristina Toutanova retweetledi
Excited to share new work from @GoogleDeepMind: “ProtEx: A Retrieval-Augmented Approach for Protein Function Prediction”
biorxiv.org/content/10.110…

English
Kristina Toutanova retweetledi

Excited to present Pix2Act! An agent that can interact with GUIs using the same conceptual interface that humans commonly use — via pixel-based screenshots and generic keyboard and mouse actions -- arxiv.org/abs/2306.00245 (1/4)

English
Kristina Toutanova retweetledi
Very happy to share that Pix2Struct was accepted at ICML! It's also now a part of the HuggingFace universe thanks to @younesbelkada, @NielsRogge, and @a_e_roberts!
huggingface.co/docs/transform…
Mandar Joshi@mandarjoshi_
Excited to present Pix2Struct! It's a general-purpose pixel-to-text model that can be finetuned on tasks with visually-situated language, such as UIs, charts, figures, tables, documents, etc. -- arxiv.org/abs/2210.03347 (1/4)
English
Kristina Toutanova retweetledi

Is scale all you need for semantic parsing? We present a systematic study of scaling curves measuring compositional generalization in semantic parsing across model types and task adaptation techniques:
arxiv.org/abs/2205.12253 at #EMNLP2022 (1/n)
English
Kristina Toutanova retweetledi

🤔 When does a factoid question need a *long* answer?
🤖 "Long" could mean multiple things: either you ask for a city with a very long name or …
Read Ivan Stelmakh's internship paper to get the second part of the answer!
arxiv.org/abs/2204.06092
English
Kristina Toutanova retweetledi
Our group is looking for a student researcher to work on measuring and improving the compositional generalization capabilities of neural networks. Come work with me, Kristina Toutanova (@toutanova), and others across Google Research! (1/2)
English
Kristina Toutanova retweetledi
“Improving Compositional Generalization with Latent Structure and Data Augmentation” arxiv.org/abs/2112.07610.
Can we do better than good-enough compositional data augmentation? We present a data recombination method using a model called Compositional Structure Learner (CSL).

English
Kristina Toutanova retweetledi

New from Google Research: arxiv.org/abs/2106.16171
To build multilingual NLP systems, a successful recipe is to pre-train on a multilingual corpus, and then fine-tune on labeled data in a single transfer language -- usually English. But is English best?
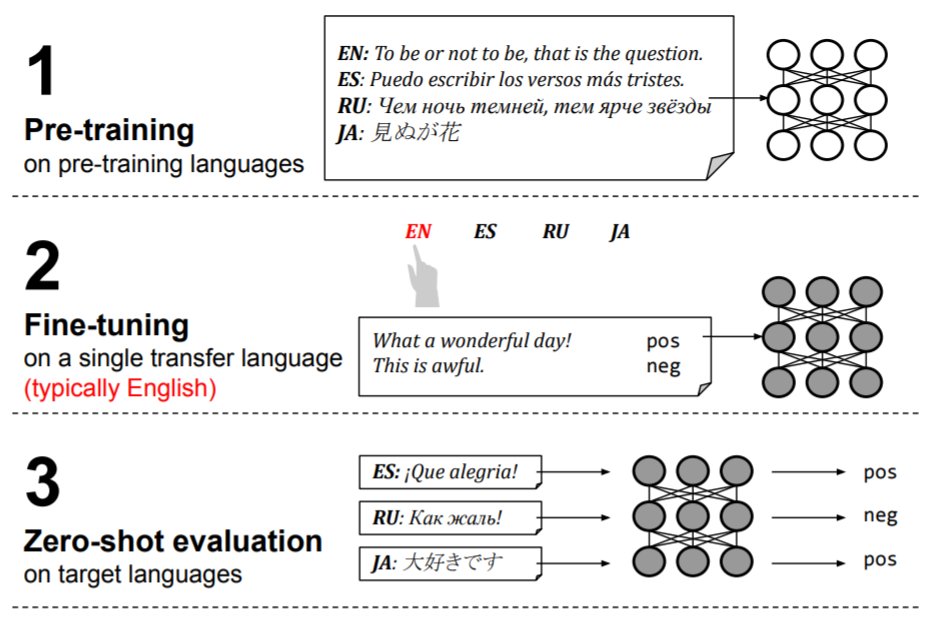
English
Kristina Toutanova retweetledi
We’ve released the code for our paper “Compositional Generalization and Natural Language Variation: Can a Semantic Parsing Approach Handle Both?” (w/ @mchang21, @IcePasupat, @toutanova):
github.com/google-researc…
English
Kristina Toutanova retweetledi

If you were waiting until after the EMNLP deadline to register for NAACL, now is the time -- early registration ends tomorrow May 20.
English
Kristina Toutanova retweetledi
You can help determine an effective format for the virtual NAACL 2021!
You can provide quick feedback on options or volunteer to serve on the virtual infrastructure chairing committee via this form forms.gle/91EfYUcj7Yy5jS…
English
Kristina Toutanova retweetledi

New from Google Research: CANINE, a pre-trained tokenization-free language encoder. This frees us from a variety of pitfalls associated with tokenization, but also improves quality on TyDi QA, a multilingual question answering benchmark. arxiv.org/abs/2103.06874
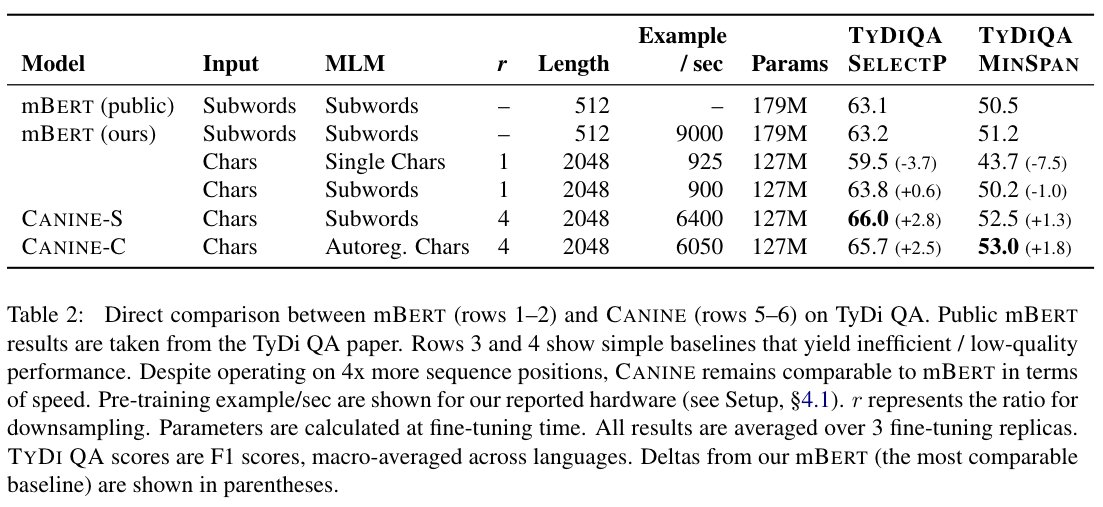
English
Kristina Toutanova retweetledi

New from Google Research! arxiv.org/abs/2102.01335
Show examples from the distribution you want, and our example extrapolator (Ex2) generates new examples from the same distribution.
We use Ex2 for data augmentation, improving over SOTA methods on multiple NLP benchmarks! (1/3)

English
Kristina Toutanova retweetledi

Introducing 💎GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. We are organizing shared tasks for our ACL 2021 workshop - Please consider participating!
Website: gem-benchmark.com
Paper: arxiv.org/abs/2102.01672
#NLProc
🧵1/X
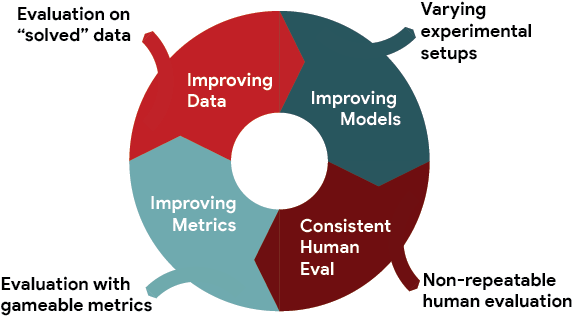
English
Kristina Toutanova retweetledi

A reminder that the #NAACL2021 demo track submission is due on Mon Jan 11, 2021 at 11:59pm anywhere on earth.
Victoria X Lin@VictoriaLinML
Call for system demonstrations #NAACL2021 💻 is here: 2021.naacl.org/calls/demos/ Deadline 📅 Jan 11, 2021 We welcome any work describing #NLProc system demonstrations, ranging from early prototypes to mature production-ready systems. cc: @aviaviavi__ @toutanova @NAACLHLT
English
Kristina Toutanova retweetledi

These tutorial slides on "High Perf NLP" are really impressive. Every slide is current to the minute. Amazing set of diagrams.
gabrielilharco.com/publications/E…
(@gabriel_ilharco @Tim_Dettmers @IuliaTurc @kentonctlee Felipe Ferreira Cesar Ilharco)

English
Kristina Toutanova retweetledi
As noted in the CFP, #NAACL2021 is incorporating ethical considerations in the review process. For more information on what that will look like, please see our Ethics FAQ for authors: 2021.naacl.org/ethics/faq/
English