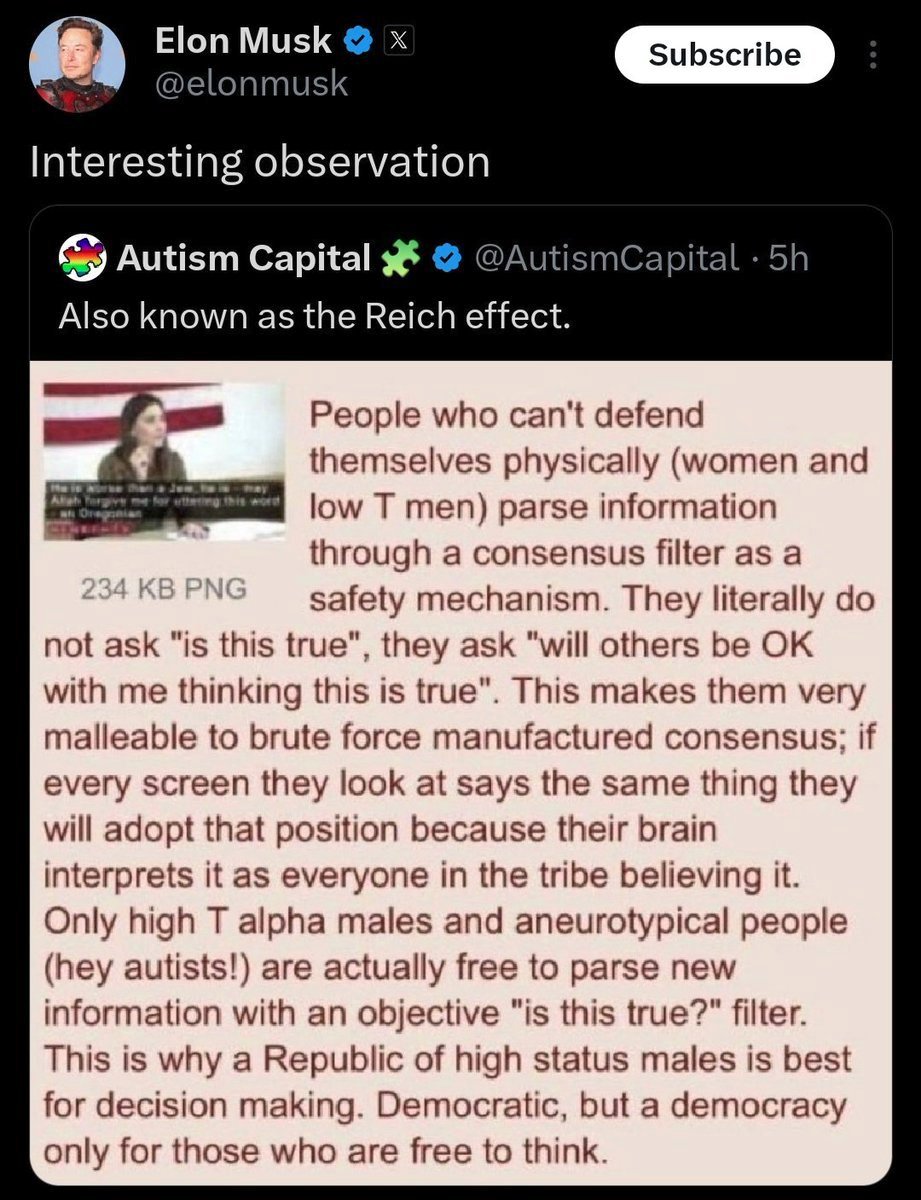
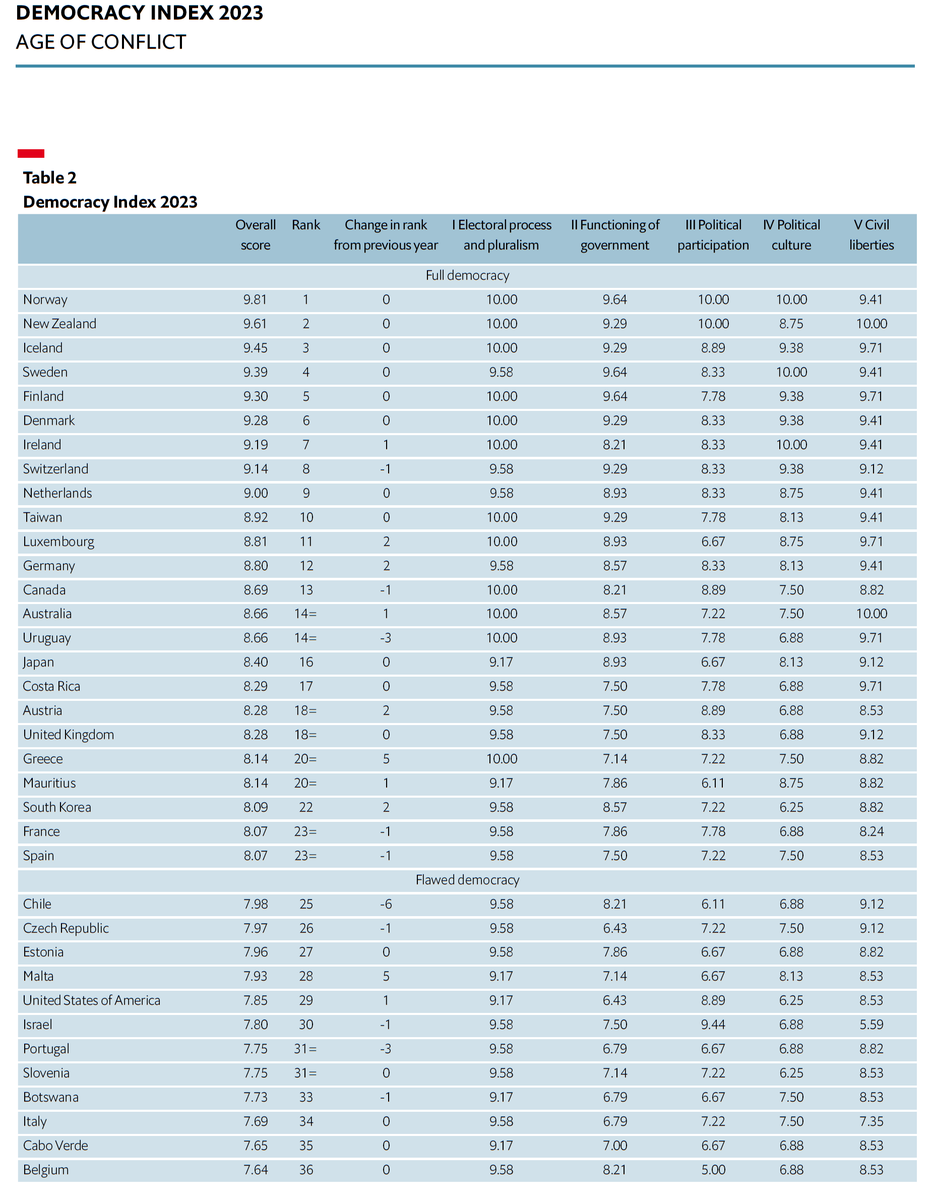
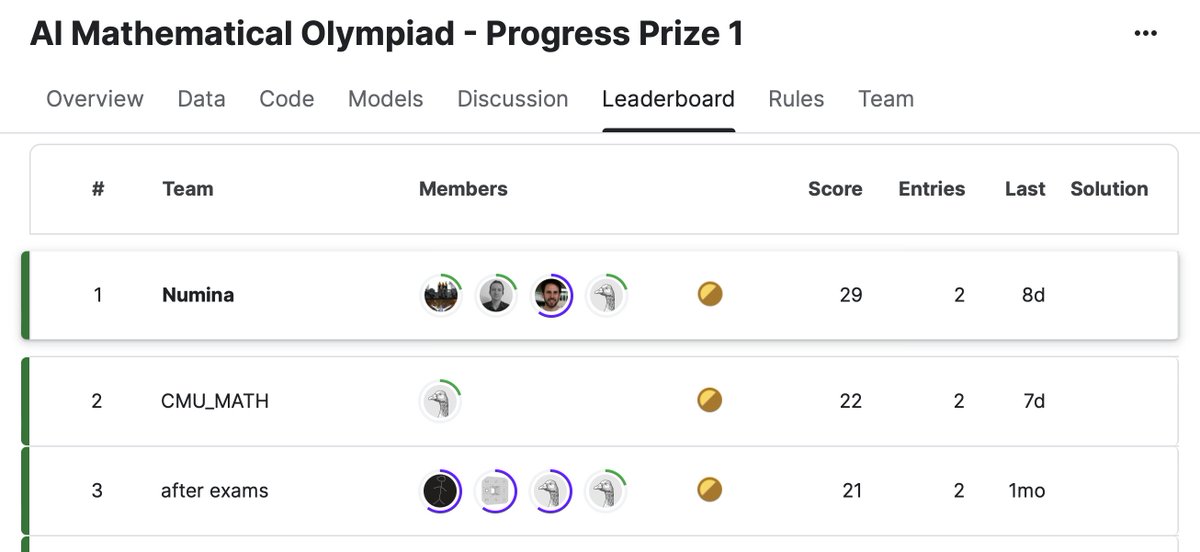
Sabitlenmiş Tweet

DiffPaSS: Differentiable Pairing using Soft Scores
Optimize pairings and graph alignments using gradients and smooth scores
📜 @gembioworkshop @iclr_conf paper: tinyurl.com/2p98cvrr
🖥️ #PyTorch library: bitbol-lab.github.io/DiffPaSS/
Specialised to interacting #protein sequences
English