
Venkat Raman — inference/acc
2.6K posts
Venkat Raman — inference/acc
@venkat_systems
distributed systems, low latency, inference | 🦀 | hobbies: ⛷️ 🏊🏽♂️ 📷
µs, ns, 80% speed-of-light Katılım Ocak 2013
1.9K Takip Edilen546 Takipçiler


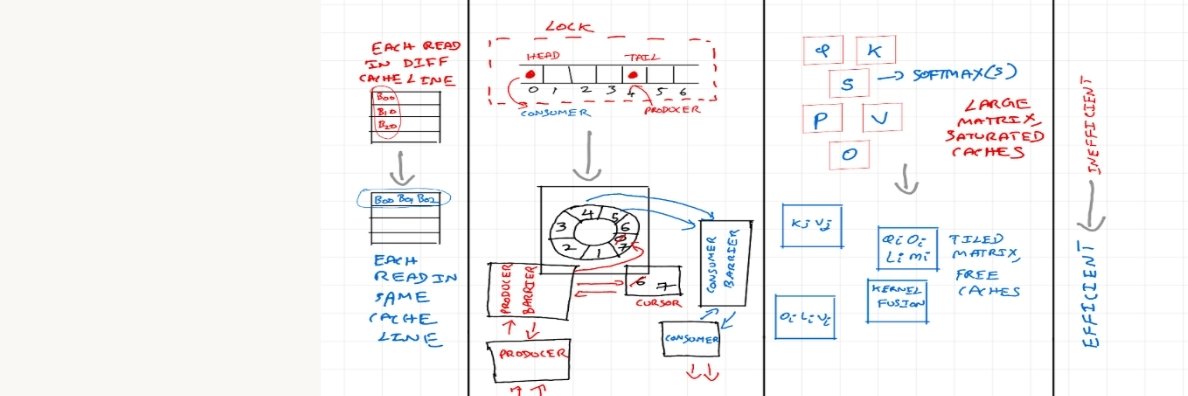
@venkat_systems @camillenvargas If I had a billion dollar position?
Absolutely
English

@camillenvargas If you have a billion dollar position in a startup you can take some embarrassment
English
@himanshustwts @SkyLi0n are they eligible for claude-code oss credits?
English

last commit btw
LMFAO
OpenAI Newsroom@OpenAINewsroom
We've reached an agreement to acquire Astral. After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive. openai.com/index/openai-t…
English
@kochyhere @jorandirkgreef @TigerBeetleDB whoa ! don’t tell me TigerBeetle is also puffn w/ object storage now ! @Sirupsen should share cool puffer swag tips for beetle 😉
English

.@TigerBeetleDB's contribution to my growth as an engineer is understated. what a gem of a video - youtube.com/watch?v=y2_Bqk…

YouTube
English
@jarredsumner how hard did u guys try to get them ? 😉
English

i never understood the hype behind gemini 3 n code-red at openai bcos of it
gemini does coherent image gen well, that’s all
coding using their agent, n reliable web search w/o outrageous hallucination is an absolute shit show.
youtube transaction used to be good but that is also restricted
total 🤡 show
English


English

LETS GOOOO! So so psyched for this!! OpenAI really securing the future of Open Source! 🔥

OpenAI Newsroom@OpenAINewsroom
We've reached an agreement to acquire Astral. After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive. openai.com/index/openai-t…
English
@OpenAINewsroom @youyuxi @astral_sh Congrats @charliermarsh & @astral_sh team ! was expecting this 🚀🚀
English

We've reached an agreement to acquire Astral.
After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive.
openai.com/index/openai-t…
English
@arpit_bhayani Congrats Arpit ! I was hoping you’ll get into early stage startups again. Pls check DM :)
English

Joined Razorpay as Principal Engineer II :)
From being a long-time customer to now building parts of the system - it's a full circle. Fintech is a new territory for me - time to get under the hood of how money actually moves.
New domain, same guarantees - availability, correctness, performance - just with real money on the line.

English
@sundeep - is groq static scheduling going to be part of oss dynamo ?
- is there going to be groq-cuda libs n sdk
would love to make some oss contributions
i’ve been grinding thread-per-core, share nothing, message passing libs for extreme low latency & high throughput systems
English

Today you need access to an AI factory:
7 chips
5 distinct purpose built rack scale systems.

English
@dylan522p is it okay to say out loud - i felt secondhand pride for you n the team 🚀
English

Jensen name-dropped me in the keynote and posed with our belt.
He has a physical belt too but they just showed the pic
Intially I made fun of the 35X perf improvement being bogus, I thought it was an exaggeration of performance
Turns out he was sandbagging, and perf is 50x
English
@garrytan workday is just a glorified database n excalidraw charts
English

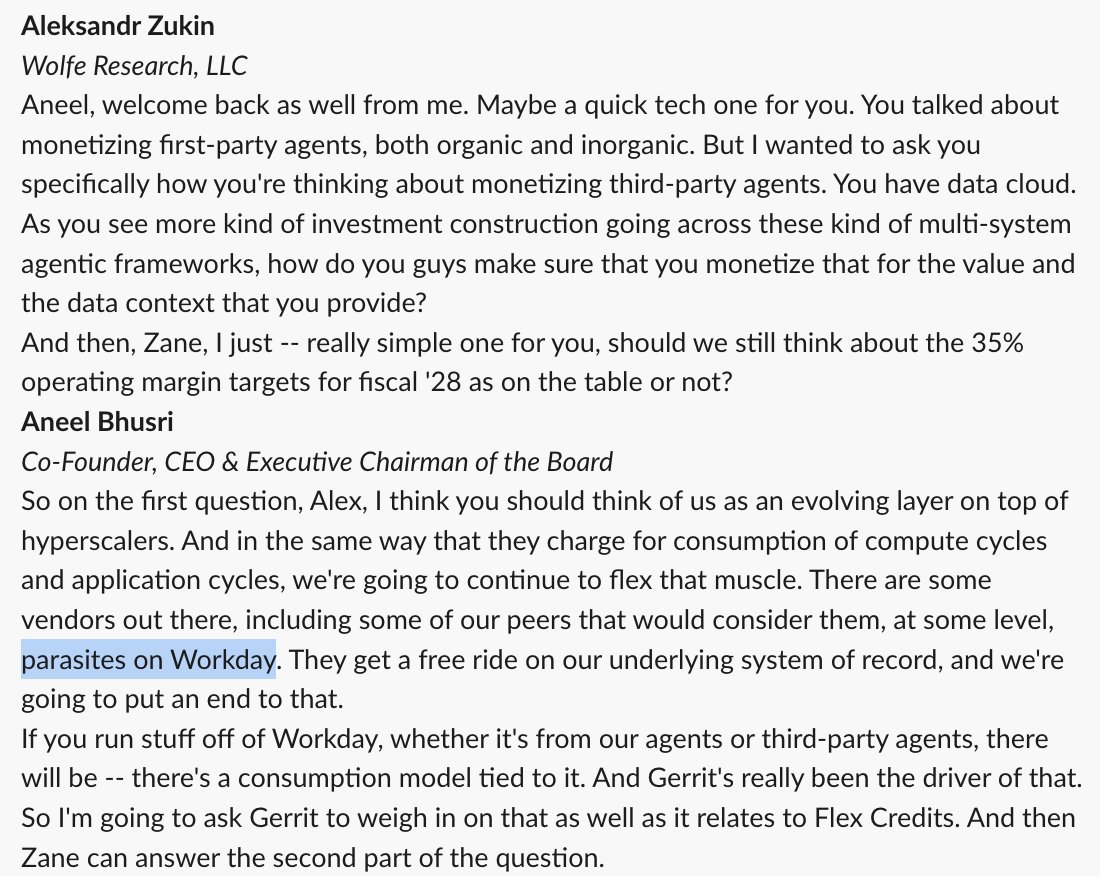
Recent earnings call, Aneel Bhusri of Workday says startups with AI agents are "parasites"
This is what system of record incumbents really think of startups.
The war is just beginning. The facts: the user data belongs to the users, not the incumbent software vendor.
English
@levelsio if they never sold, there might not be a tsmc as we know today
English

The biggest fumble in business ever might be Philips spinning off ASML, TSMC and NXP
Philips co-founded ASML in 1984, then co-founded TSMC in 1987, then they founded NXP
They sold each of them for short term profits in the 2000s
ASML is now worth $545B
TSMC is worth $1.76T
NXP is worth $50B
Philips today is worth just $27B
If they'd never sold, Philips would be the largest company in the EU today, worth $650B
Philips CEO Cor Boonstra called it "making money with the success of the past"
🤡
English
Venkat Raman — inference/acc retweetledi

@dantelex No, it's again crypto folks spamming and hurting the project.
English
@levelsio u mean like foundations n NGOs.. most of the money is spent on operations, expenses n ppls salaries than the actual beneficiaries ?
English
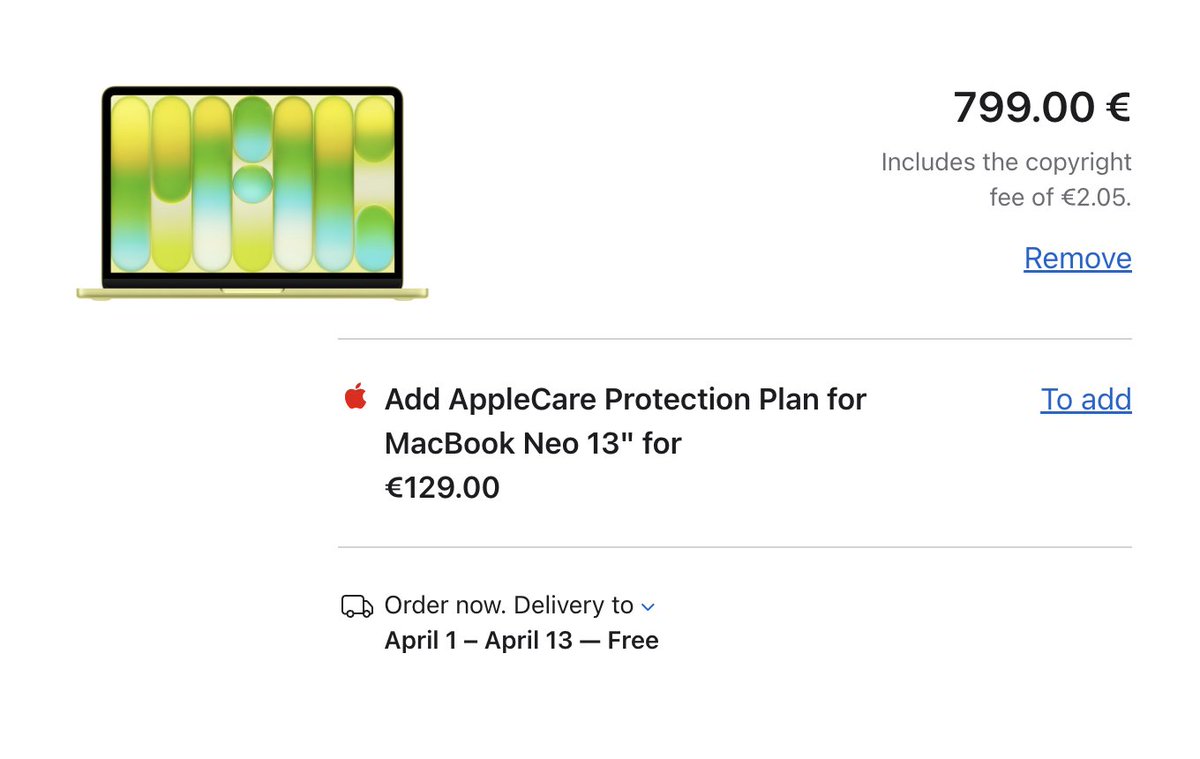
/r/mildlyinteresting
In Portugal you pay up to €7.50 when you buy a laptop called a "copyright levy"
You pay €4/TB of storage in the computer, so for a MacBook Neo 13" with 512GB that's €2.05
It's regulation made in 1998 to compensate artists for you illegally sharing MP3 files which nowadays of course doesn't make sense anymore since we have Spotify and YouTube
Much of the money doesn't even arrive with artists btw, 30% is taken by the organization collecting the tax and lot of it remains unclaimed and some of that goes again to the organization collecting the tax as "operational costs"
🤡
English
@HotAisle @ssskryl @thegeomaster @insane_analyst i’ve too tried and failed to find TCO of Groq, Cerebras n SambaNova
very difficult to calculate tokens/watt & sustained goodput per tco for a given model serving config
English

@ssskryl @thegeomaster @insane_analyst You're trying to polish two turds. Once no longer exists in its current form and the other is a dead man walking. This will be the fate of many ASIC's over the years.
English
This guy is a master manipulator.
20 wafers is $3m*20… or more… at what concurrency?
For $60m… I can buy a cluster of approximately 768 mi355x and have 288GB*768 amount of memory and also use less DC space and power and serve who knows how many users… too lazy to do the math.
He is clearly afraid and disappointed at not getting the $20b deal from N.
Andrew Feldman@andrewdfeldman
NVIDIA's biggest GTC announcement was a $20 billion bet on the same problem we solved 6 years ago. Their next-gen inference chip - not available yet - has 140x less memory bandwidth than @cerebras. To run a single 2 trillion parameter model, you need 2,000+ Groq chips. On Cerebras, that's just over 20 wafers. Even paired with GPUs, Groq maxes out at ~1,000 tokens per second. We run at thousands of tokens per second today. And every day. In production now. Why? When you connect 2,000 chips together, every interconnect has latency. Every cable has overhead. It doesn't matter what your memory bandwidth is on paper if you're bottlenecked by the wiring between thousands of tiny chips. We solved this with wafer scale. One integrated system. Little interconnect tax. Jensen told the world that fast inference is where the value is. He’s right - it’s why the world’s leading AI companies and hyperscalers are choosing Cerebras.
English
@msharmavikram @marksaroufim @GPU_MODE @NVIDIAGTC the legend in the flesh, Stephen Jones ! Vikram u should get him on twitter :)
i binged all his gtc sessions in 2024, truly life changing
English

@marksaroufim @GPU_MODE @NVIDIAGTC
Award ceremony for the nvfp4 kernels.
Come hang out at GuildHouse!

English
@thsottiaux @jxnlco i read it as pre-jensen & post-jensen codex 😂
English

