verl project retweetledi

Mind Lab, together with our community partners NVIDIA @Nvidia @NVIDIAAIDev, VeRL @verl_project, and vLLM @vllm_project, is making LoRA RL practical at trillion-parameter scale. We mapped the failure modes of LoRA RL on trillion-parameter MoE reasoning models and built a hybrid-parallel engine—VeRL for RL orchestration + NVIDIA NeMo’s Megatron-Bridge for MoE parallelism + vLLM for efficient rollouts/inference—that enables stable, cost-efficient RL at ~10% GPU usage.
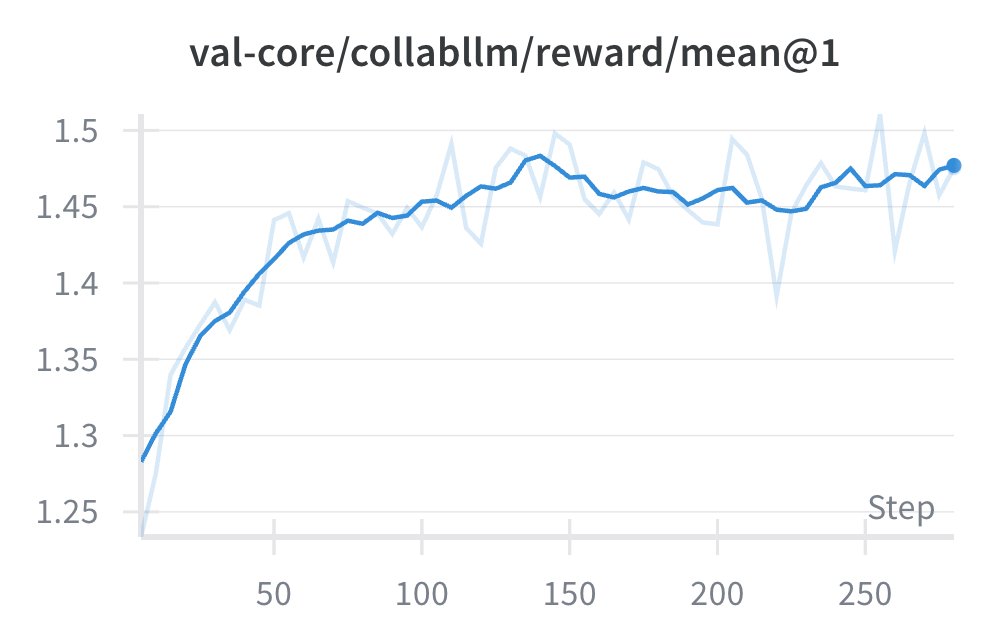
With comparable RL compute, trillion-parameter LoRA RL beats full-parameter RL on smaller models—underscoring that strong priors are crucial for reasoning-level RL.
Read the full post: macaron.im/mindlab/resear…
English