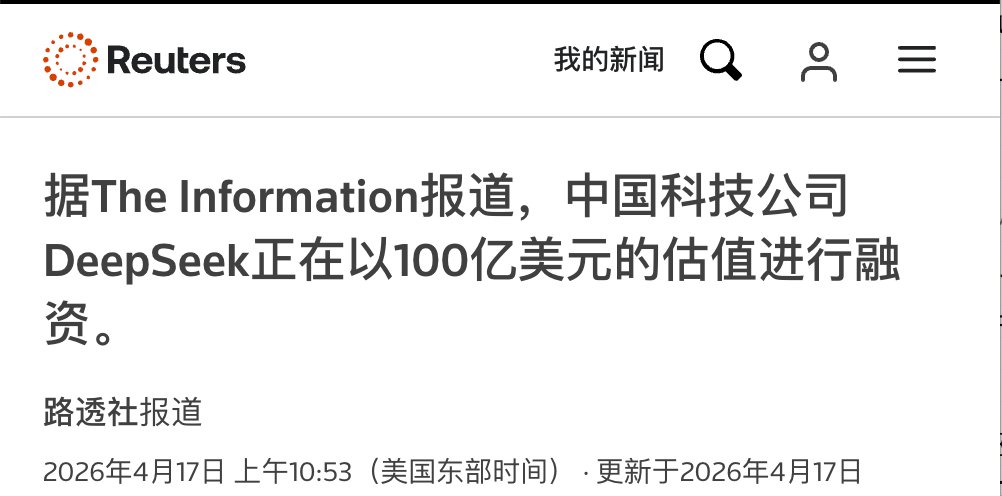
@chenreason zai minimax 这种ipo上市后比京东都高 说实话deepseek 100亿美金都太少了 就推理这块deepseek 比前两者强太多了
中文
WANGRUI
1.8K posts
@wangruipro
大模型交付架构;BG线 参与过鹅厂代码工具工程化开发 能源行业大模型应用落地全流程;


さすが共産主義と独裁国家で鍛えられた人ですね。違法アルコールでも醸造・飲酒してお楽しみください。そして80年間の平和を維持した国である日本の著作物には手をつけないでください。







@wangruipro @Konekoutena お前らが習近平批判を平気で公言できるようになれば認めてやる。 どんなに偉そうな事を言っても現体制を非難出来ない哀れな不自由な民族とは関わり合いたくはない。 それだけだ。 少なくとも日本人は平然と現政権を非難できる自由がある。 悔しかったら「習近平は独裁者!」だと叫んでみろよ。笑


@DMM_zbr @Na75628Com @Konekoutena 普通中国人对高市挑衅的危机感?其实并没有,因为大部分中国人体会不到任何感觉,最多一个觉得这位女首相嘴上把不住门,说话不考虑后果,简直和小孩子一样,完全没有一国领导人该有的样子而已。因为现阶段日本没有能力对中国造成任何实际性的威胁,自然普通民众是体会不到的。当然在日中国人可能例外


The Jensen Huang episode. 0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains? 0:16:25 – Will TPUs break Nvidia’s hold on AI compute? 0:41:06 – Why doesn’t Nvidia become a hyperscaler? 0:57:36 – Should we be selling AI chips to China? 1:35:06 – Why doesn’t Nvidia make multiple different chip architectures? Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!


@ma7foreverlove @jlaw520 早你二十年去過日本 你嫉妒了?
最近在测试某国产算力硬件,单卡64G 显存,8卡一节点。目前来看,核心难点就二:第一是多卡并行通信,比如 stepfun\minimax 这样的模型,tp8 相比 tp4 带来的吞吐提升非常有限。第二是算子适配,比如相同的 10B 激活的模型,推理速度差别奇大,需要为各家模型做定制化优化。 不过相比前年底或去年初,确实已经有明显得提升,至少一两千亿量级模型已经有可用性,也就是能处理一二十并发,每个请求小几十 token 每秒的decode速度。 我感觉今年硬件上能摸到 H200 的屁股,但软件上仍然有巨大的鸿沟。