Sabitlenmiş Tweet
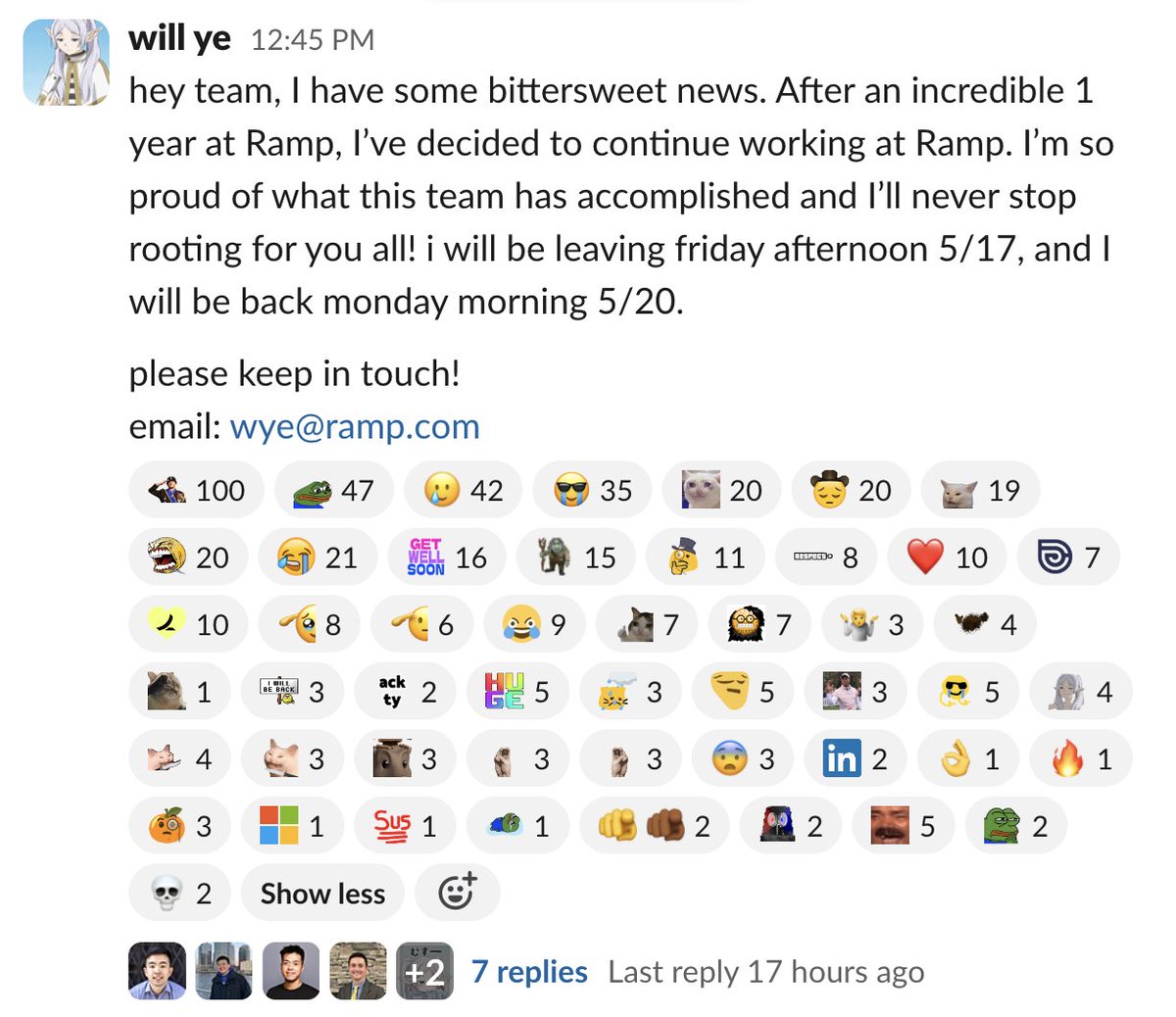
will ye
1.6K posts

will ye
@will__ye
member of whimsical staff, ex-ramp applied ai
SF Katılım Mayıs 2016
501 Takip Edilen5K Takipçiler
@AdamSmielewski @charlietlamb Not true? At least the interviews I gave were not leetcode-style at all.
English



Rly thoughtful non-slop take on a productivity tool from a friend of mine — like a Spotify wrapped for your day, every day!
Jerry Liu@jerryliu
We've been thinking about the best way to use screen data for a while now. After 500k hours of beta use, we're launching Dayflow: the open source automatic work journal. One of my favorite @rabois-isms: the best predictor of success is how well you allocate your time. But nobody actually knows where it goes. Memory lies, calendars only show the plan. Dayflow shows you the truth about today so you can be intentional about tomorrow.
English
@candyflipline “He’s just a kid! He’s just a lil goofball :3” this is a fully grown man, why are you infantilizing him lol. I’m sure he can handle a screenshot.
English

you are so tuff for posting dms, wow.
you raised 45m (!) for your .mdx aggregator.
you finessed a16z out of money.
but you cant handle a 21yo goofball?
whats next, you are going to sue?
weak men, hard times.
Han Wang@handotdev
@mil000 Then stop asking for a job
English
Fat/xanthan serve diff purposes.
Fat only kind of prevents freezing into a brick, it’s mostly for mouthfeel. Xanthan helps enormously with preventing ice crystals because it’s a stabilizer, you can also use it when making “real” ice cream. Other stabilizers are better (like guar gum, locust bean gum), but they’re mostly used in commercial ice cream bc they’re harder to acquire/use.
English

@DeanTTraining That makes way more sense
So the xanthan’s basically doing what the fat normally does in real ice cream, holding it together so it doesn’t freeze into a brick. Clever.
How much does the almond milk actually matter here?
English

Probably just gonna keep posting this every week until everyone on the internet knows about it…
(You make this using a Ninja Creami Deluxe which, as of today, is still ON SALE at Costco for $150!!!)
Oreo Blizzard High Protein Ice Cream Recipe:
- 240ml Fairlife Skim Milk
- 240ml Almond Milk Unsweetened Vanilla
- 51g True Nutrition Cookies N Cream Egg White Protein
- 30g Oreos Cookies N Creme Instant Pudding Mix
- 4 Oreo Thins
- 2g Xanthan Gum
540 calories / 50g protein

Stockdaddy@Greendaystocks
@DeanTTraining Do you have a post giving the recipe and nutrition facts on this ?
English
@cormachayden_ @jwmares @IBIJBPM the product is still broken misinformation slop so clearly you guys didn't iterate correctly
English

@SaleemUsama @BasedDaedalus This is worthless. If you want to flex, post an offer letter instead. And if you’re actually good, they’d be the ones reaching out to you.
English






let it be known that I brought the winning tinned fish to the tinned fish party, and that I received a fish hat as the prize 😤
aadilpickle@aadilpickle
sf is so weird what do you mean theres a tinned fish party
English
@venturetwins @max_spero_ @a16z are you being willfully ignorant? that's not his point. they (doublespeed) are intentionally misleading consumers by mass-posting undisclosed ads. while AI contributes to the scale, the main issue is deceptive marketing.
English

@max_spero_ @a16z Have you actually looked at this company?
Many folks are building AI influencers that automate content production for social apps. This is not evil dark magic 😂
English
I've watched this ad several times and genuinely can't understand the point.
If you want a condescending VC who believes they're the moral authority on whether or not your product should exist...contact General Catalyst?
If you don't, we're open for business @a16z 🫡
General Catalyst@generalcatalyst
Meet GC
English

@keindata @FluffyNuZzZz @pilateswife Sure, I think that’s fair for transparency’s sake.
I don’t think seed oils are dangerous but preferences are preferences.
English

@will__ye @FluffyNuZzZz @pilateswife I argue that if the consumer must look-up the data sheet for this gelato emulsifier mix & then cross-reference the additive E numbers for chemical name, that the details are a bit hidden. I also prefer my ice cream without seed oils & their by-products.
English
I don’t think this was meant to hide anything, it’s just the name of the commercial mix. And fearmongering over stabilizers and emulsifiers is dumb anyway, they prevent ice cream from freezing hard, add body, and are perfectly safe. Plus most of them are made from natural ingredients anyway
English
@FluffyNuZzZz @pilateswife Interesting way to hide palm oil, mono-/di-glyceride emulsifiers, & thickeners. raderfoods.com/wp-content/upl…
English
@ycombinator @sdianahu "contact switching" "KB caches" how hard is it to do a final pass over the subtitles? really sloppy.
English

Inference Chips for Agent Workflows
@sdianahu
Most AI chips are designed for "prompt in, response out." Agents don't work that way. They loop, branch, and hold context across dozens of steps, and current GPUs hit 30–40% utilization as a result.
That gap is where purpose-built silicon wins.
English
AI has stopped being a feature and started being the foundation.
We're excited about a new wave of startups rebuilding software, services, and silicon— and pushing AI into the physical world.
ycombinator.com/rfs

English
@m1guelpf i did something similar 10 years ago, where you and a friend strap your phones to your wrists and high five each other to see who wins: github.com/williamyeny/hi…
English

i'm working on an app that uses the accelerometer in your phone to measure how hard you can throw it against the ground and compete with others
this video is part of an elaborate campaign to convince you to download the app & get to the top of the leaderboard
please enjoy
English

I just saw Ben Pasternak’s video. I wasn’t planning to speak publicly, but hearing experiences that felt familiar made staying silent feel wrong.
I was in a relationship with Evelyn years before Ben. During that relationship, I experienced things that were consistent with parts of what Ben described. Including physical violence.
When our relationship ended, a version of events was shared publicly that did not fully reflect my experience. At the time, I chose not to respond. I made that decision for several reasons: I wanted to protect her, I didn’t want to turn a private situation into something public, and I was young and didn’t fully know how to handle the situation.
I’m not here to revisit the past in detail or to speak for anyone else. I’m only sharing this to clarify that my experience and truth did not fully align with the narrative that had been presented.
I stayed quiet for a long time for my own reasons. Speaking now is simply about being honest about what I experienced. Some of what was shared in the video was new information to me, and I’d like to process privately. I’m also sorry for what Ben went through. I hope he has the support he needs.
English
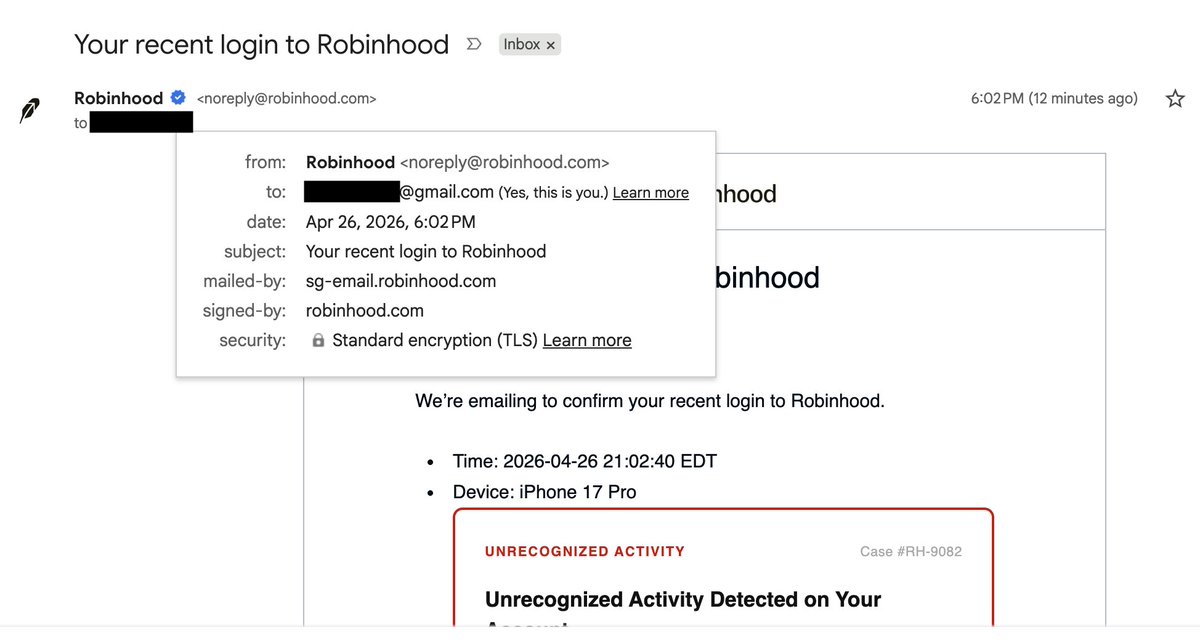



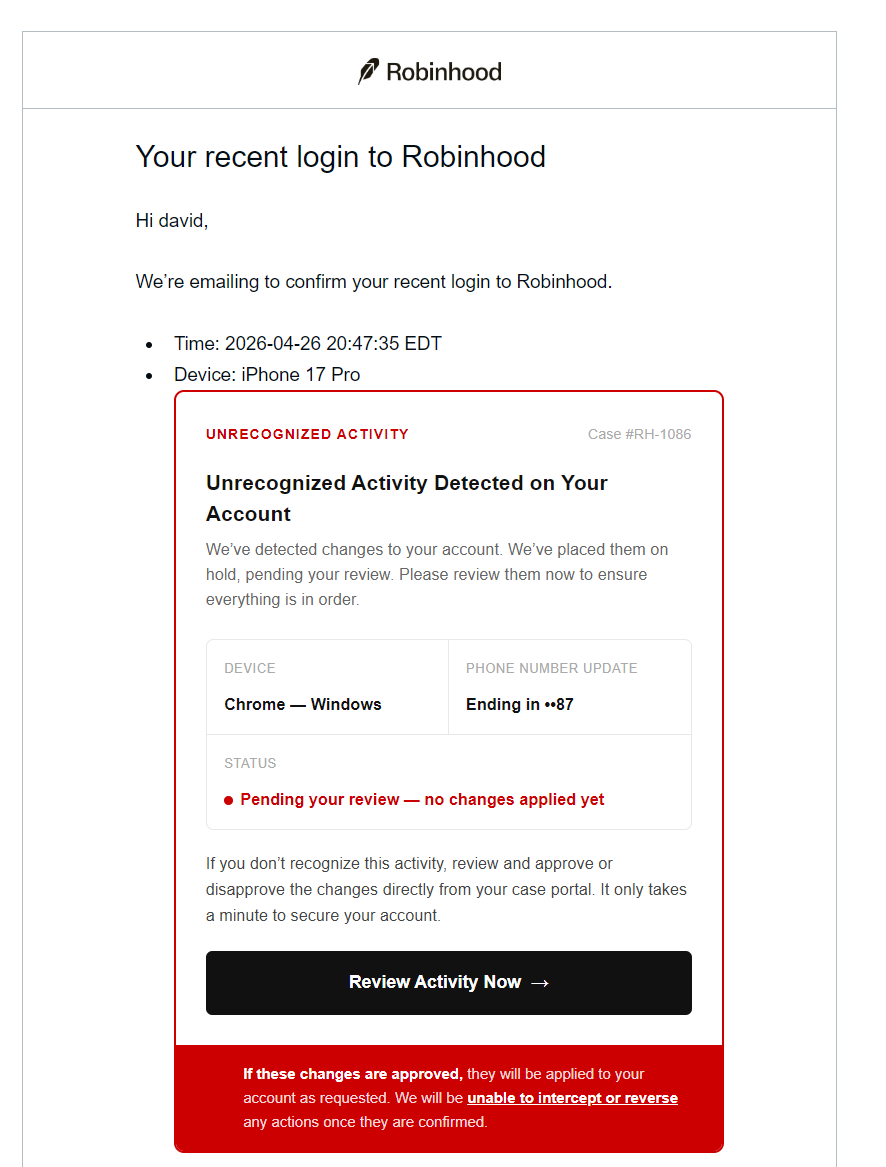
WARNING: Any emails you get that appear to be from Robinhood (and may actually be from their email system) are phishing attempts.
Example:
English
@Batience_ @EliaFranzini1 @theannasarchive this domain is an impersonator. look up anna's archive on wikipedia to find the legitimate domains.

English

@EliaFranzini1 @theannasarchive Did the problem be solved? I encountered the same problem.
English
I love this, this is so cute! Spent an hour this morning wandering around and enjoying the art :)
I wish the descriptions would load faster… could you optimistically fetch the descriptions and/or cache them across users? Would be cool if the people looking at art were bumped to the top, I’m more interested in what art ppl are looking at vs. ppl who r just browsing. And ppl could be encouraged to chat more if the chat input is always visible vs. having to hit a button first!
English

@MeghanBobrowsky what does the groupchat think about this: peepeepoopoostreet.com
English

shockingly my pitch to our WSJ tech bureau to buy the naming rights to this street is not taking off whatsoever in our slack groupchat
Riley Walz@rtwlz
Ever wanted to NAME A STREET? We’re auctioning off the naming rights to an actual alley in San Francisco. Highest bidder can name it whatever they want. Ends Tuesday at 1pm PT
English