Yassin
1K posts


Yassin
@yelf_fafa
CTPO @ Idun | Tech Lead GenAI @ LVMH, building distributed agentic infra Builder at heart ❤️ Deadlift up, hallucinations down OSS ↓



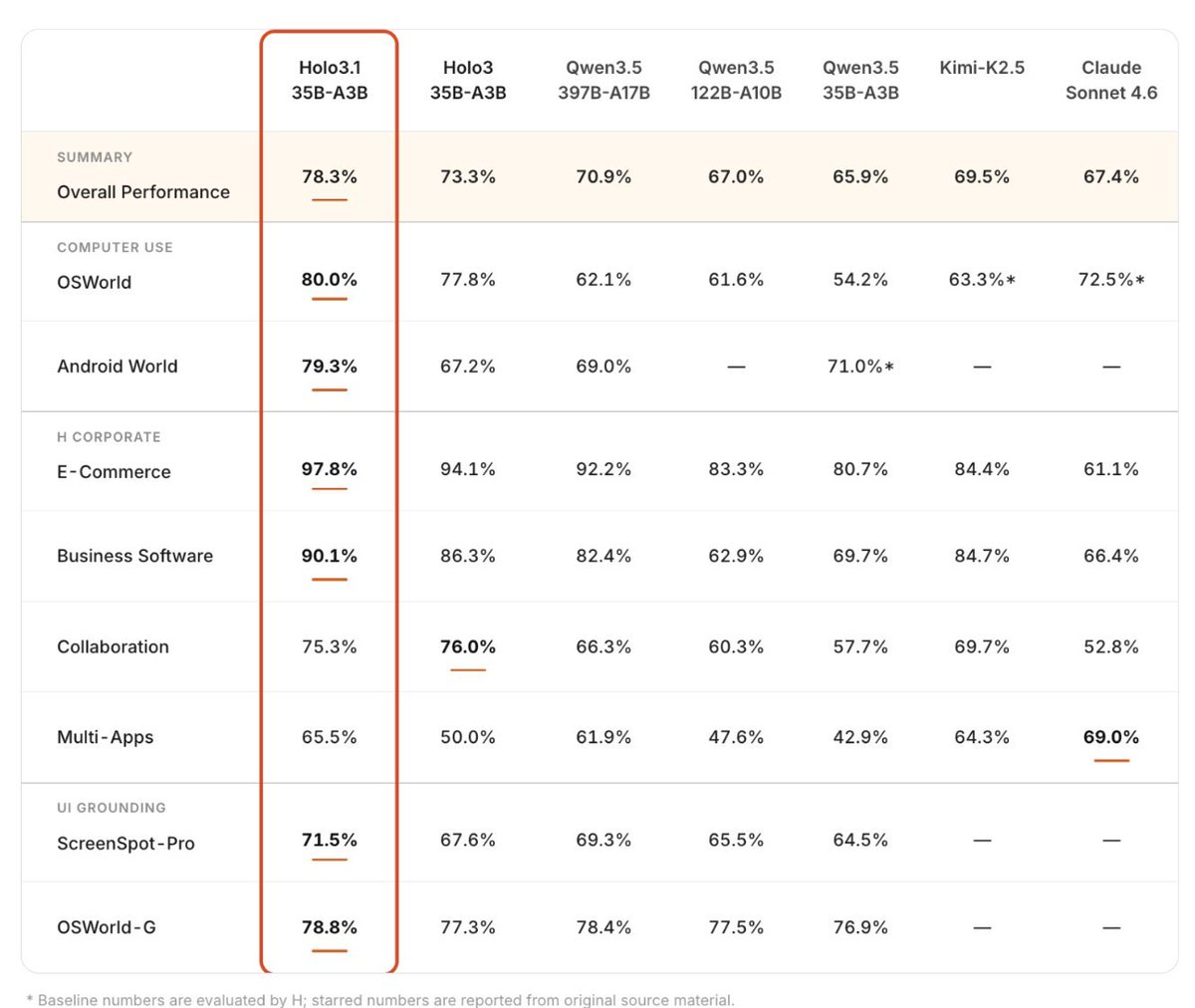
Computer-use agents are moving from the cloud to your local machine. Fast. When we launched Holo3 two months ago, the production feedback was clear: digital agents need to be blazing fast, cost-effective, and versatile. Today, we're dropping Holo 3.1, engineered to run anywhere, instantly. Massive token throughput. Low latency. Ready for your local workflow!











The self-improving AI agent from Nous Research! Hermes Agent is a self-improving AI agent that builds skills from your work, improves them over time, and remembers across sessions. Most AI agents reset every conversation. You teach them your codebase structure, they forget. You show them your deployment workflow, gone. You explain your preferences, erased. This happens because most agents treat memory as an afterthought. They save conversation history but don't actually learn from it. They don't build skills or improve their own behavior. Hermes fixes this with a closed learning loop. After you complete a complex task, it autonomously creates a skill for it. That skill becomes permanent. Next time a similar task comes up, it uses the skill and improves it based on what works. It has a memory system with periodic nudges. It actively prompts itself to persist knowledge. FTS5 session search with LLM summarization recalls past conversations. Honcho dialectic user modeling builds a deepening profile of who you are. What this gives you: an agent that actually gets better at helping you. It works with any model. OpenRouter (200+ models), GLM, Kimi, MiniMax, OpenAI, or your own endpoint. Switch models without changing code. You can talk to Hermes from Telegram, Discord, Slack, WhatsApp, Signal, or CLI. Voice memo transcription works. Conversation continuity across platforms. Built-in cron scheduler for scheduled automations. Delegates and parallelizes work by spawning isolated subagents. It's 100% open source. I've shared the link in the comments!

BREAKING: Anthropic just dropped Opus 4.8—and it is a MONSTER We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good. Here's our vibe check: - Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works. HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results. - Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context. HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high. - Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark. - Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic. THE BAD: These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex + GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude. Anthropic is back baby! Read the rest on @every: every.to/vibe-check/opu…