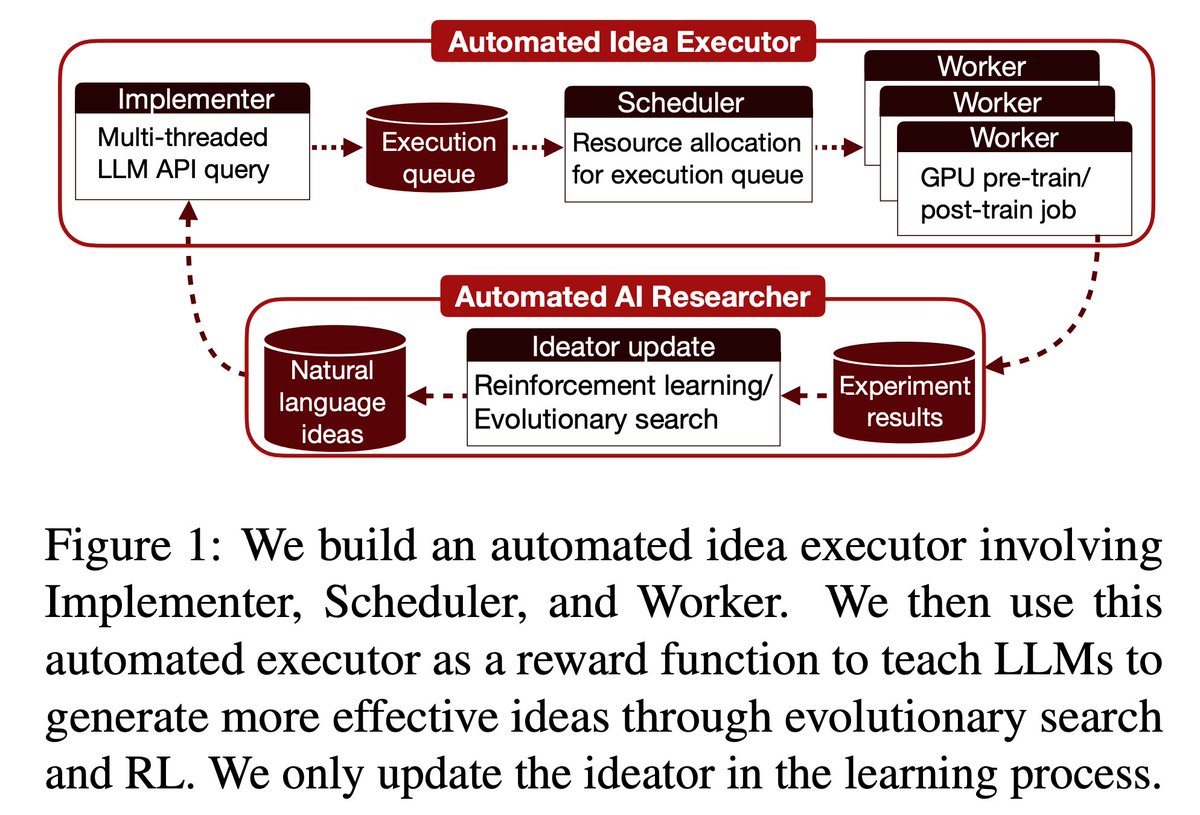
@karpathy Our AI system from @IntologyAI recently discovered an automated world record!
x.com/classiclarryd/…
Larry Dial@classiclarryd
New NanoGPT Speedrun WR at 105.9s (-1.0s) from @soren_dunn_ , with a triton kernel to fuse the logit softcap and multi-token prediction cross entropy calc. Interestingly, Soren mentioned that their autonomous system Locus at Intology discovered and implemented the improvement. github.com/KellerJordan/m…
English