Sabitlenmiş Tweet
miru
652 posts


miru
@miru_why
3e-4x engineer, unswizzled wagmi. specialization is for warps
Katılım Ocak 2024
1.5K Takip Edilen1.6K Takipçiler

Reviving ConvNeXt for Efficient Convolutional Diffusion Models
github.com/star-kwon/FCDM
arxiv.org/abs/2603.09408…
the authors propose an improved convnext-based diffusion model architecture that reportedly matches DiT-XL/2 quality with 7x fewer training steps

English
LoL: Longer than Longer, Scaling Video Generation to Hour
the authors fix the 'video resets to initial frame' (sink collapse) problem in long streaming video generation, by jittering RoPE phases across heads so they never unintentionally sync up
arxiv.org/abs/2601.16914…

English


"I can do all things through Claude who strengthens me." – Philippians 4:13
English
@JiweiLi1 @simonguozirui good list. also watch for kernels getting tested on input distributions which result in trivial solutions (e.g. mean of a huge randn tensor is always ~0, no need to compute it #input-distributions-can-render-some-solutions-trivial" target="_blank" rel="nofollow noopener">github.com/meta-pytorch/B…)
miru@miru_why
sakana have updated their leaderboard to address the memory-reuse exploit #limitations-and-bloopers" target="_blank" rel="nofollow noopener">sakana.ai/ai-cuda-engine…
there is only one >100x speedup left, on task 23_Conv3d_GroupNorm_Mean in this task, the AI CUDA Engineer forgot the entire conv part and the eval script didn’t catch it English

Don't be fooled by AI-generated kernels.
In automatic GPU kernel generation, LLMs can exploit the timing system to produce kernels that appear extremely fast but aren’t in reality. We have written a blog summarizing these hacks, and discussing effective defenses against them.
Blog: deep-reinforce.com/defense_kernel…
Code: github.com/deepreinforce-…
Of course, the list is not exhaustive. We highly welcome feedback on any missing cases or newly discovered hacks.
English
@MaziyarPanahi @AssafShocher drop_last=False coupled with not reshuffling on epoch boundary?
English

repeat after me, it's ALWAYS:
dataset, dataset, dataset!
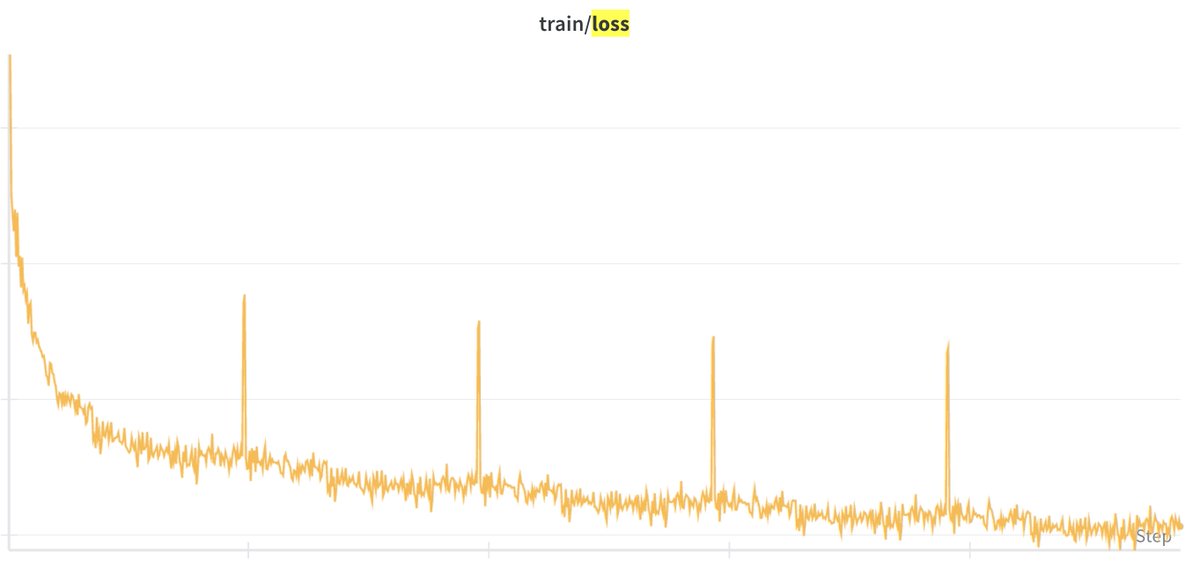
English
English

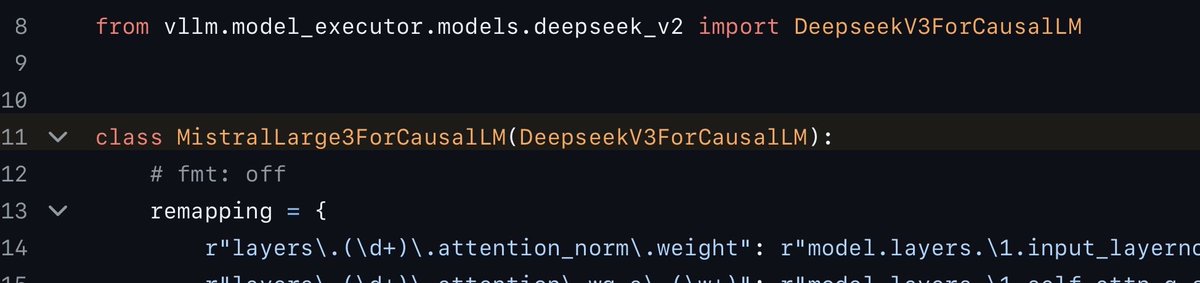
@rasbt @moskstraum21745 I remember seeing it too, and had thought I saw some straight up import from deepseek v3 in the mistral code. Can't remember exactly where though...
English

Hold on a sec, Mistral 3 Large uses the DeepSeek V3 architecture, including MLA?
Just went through the config files; the only difference I could see is that Mistral 3 Large used 2x fewer experts but made each expert 2x large.

English

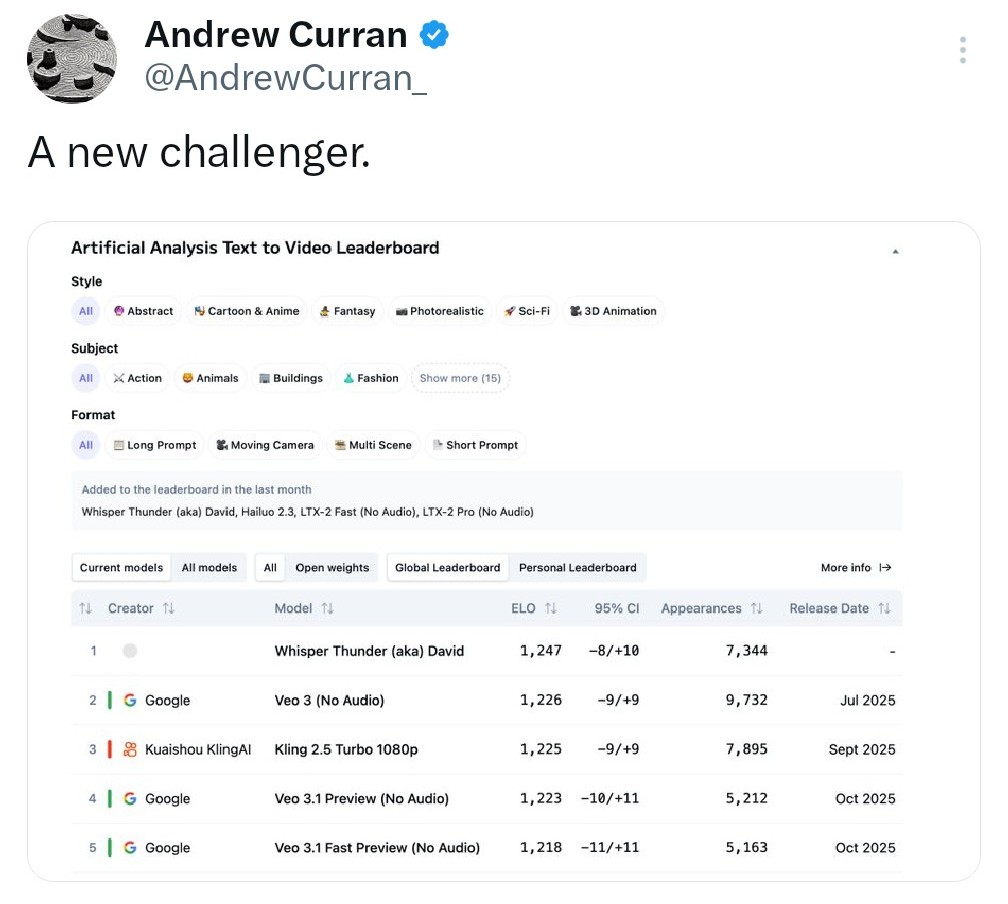
@miru_why @AndrewCurran_ @andrewb10687674 @runwayml Josh Wolfe who I’ve never seen tweet about media models tweeted about it and he’s an investor in runway so I’m almost certain it’s: them:
Josh Wolfe@wolfejosh
OK I am Google fanboy BUT!…🤯🎥 Holy shit. Veo3 just got dethroned by big margin. First time ever. Google no longer #1 on video arena leaderboard. NOW…who the heck is Whisper Thunder (David)?
English

Hints from numerous people with access that a new highly capable video model is about to arrive. David Holz confirmed Whisper Thunder is not Midjourney, so out of the most likely contenders I think it's probably xAI. Elon has been steadily improving image/video for some time.
gokaygokay@gokayfem
video model capabilities are about to take a jump that nobody is prepared for
English
@andrewb10687674 @runwayml By who? It's certainly possible.
English
English

wtf did bros at xai just read in that Qwen-Genshin paper and decide to train grok-5-mini in the same fashion?
x.com/stalkermustang…
Shen Zhuoran@CMS_Flash
I want to break down how challenging the setup is and how fundamental the breakthrough will be. It requires abilities to: - recognize a computer interface from a video stream, w/o APIs - reason with complexity under tight time limits - execute actions on a computer w/ no need of APIs - do all the above in <150ms The 3 combined will not only be a massive game RL milestone, but also unlock the potential to - massively automate any work primarily done on a computer - without needing manual work to write APIs for each legacy software - execute actions at a human or superhuman speed That will be a moment that fundamentally extends AI's capabilities and reshape the entire economy. More details: # Setup Previous works like @OpenAI Five and @GoogleDeepMind AlphaStar all used APIs to read game states and execute actions. So they have instant access to the most accurate game state data, sometimes more than humans have access to (e.g. AlphaStar's earlier version has a global vision, but humans only have a local vision). And their execution accuracy will be perfect (unless they introduces some artificial random offsets and random delays as later versions of AlphaStar did). @grok 5 will read a camera stream, parse out all the information, remember things off screen or happened a few minutes before, and locate the exact pixel to click at a competitive reaction time. ## Reaction speed Pro players have reaction times down to 150ms, so that's the latency we can tolerate from camera capture to execution output. The model also has to be able to have a very high throughput of actions. I am not as familiar with League of Legends, but in StarCraft 2, elite professional players can perform >1000 actions per minute during intense battles. That translates to >16Hz of action output. ## Perception To do this, we need high-speed, from-pixel computer interface understanding. The model must be able to read high-resolution raw pixels of a computer interface and understand it in tens of milliseconds. ## Reasoning The setup introduces challenging reasoning tasks: 1. The model must reason both under tight time limits to decide the best reaction to instantaneous context. For example, the opponent ambushing the champion from a bush. 2. But simultaneously, it also has to have the ability to maintain coherence and reason through a long-time horizon. for example, in a skirmish, the decision to use certain valuable resources or skills could be determined by, the overall strategy of the team, the composition of the team, where the team wants to take the game, and neutral objective timelines. 3. It also has to be able to reason under high uncertainty because the model might decide clicking at a certain pixel is the optimal action at the moment, but there is no guarantee that the action could be accomplished in time or on the exact pixel. The model's strategy must be robust to these imperfections in execution introduced by the video-in action-out interface. 4. It has to reason with imperfect information. This challenge is not new or unique, but still amplified by the new interface. ## Execution The model has to be able to fluently navigate the computer interface with raw input primitives, like mouse clicks and keyboard inputs. Instead of saying "I want to buy this item in League of Legends," it has to click into the store navigate interface to find the correct item and complete the purchase all using raw computer control primitives. # Implications If the model can successfully accomplish all of the above, it means: 1. It can read and understand any computer interface without needing a specialized API. 2. It can navigate any computer interface without any specialized API. 3. It can reason and produce a robust plan, a complex plan, robust tool. Real-world interferences, imperfections, and randomness. 4. It can do all of the above with humans or superhuman speed. Such a model will be a game changer for AI capabilities and the global economy. Essentially, anything a human expert can do, primarily on a computer, this model will have a high chance to be able to automate it end-to-end, with higher accuracy than an average human practitioner within the same or less amount of time.
English
@SIGKITTEN this website appears to be straightforwardly an llm hallucination, complete with emoji, em-dashes, "it's not X it's Y" and so forth? i don't think any explicit debunking is needed


English

wut
Ken Granville@Ken_Granville
Breakthrough in GPU optimization — independently validated. MindAptiv has created a new class of compute — not AI, not CUDA tuning — a new way to generate machine instructions with extreme speed, precision, and energy efficiency. Verified by an AWS-selected Premier Partner: - 20×–60× faster performance - Up to 99% less energy (Beyond our expectations!) - Runs on standard hyperscaler GPU instances - Real-time optimization no team of engineers could match This changes everything for: • Data centers • Hyperscalers • Digital twins • Blockchain / ZK • AI inference • Telecom • Graphics & rendering If you rely on GPUs or energy-intensive compute, it’s time to talk. A new era of efficiency is here — in the cloud, on-prem, and at the edge. Visit -> adaptwithchameleon.com or mindaptiv.com
QST


@herbiebradley @willccbb claude only knows, they didn't post the kernels
English

@willccbb lol this is going to be another kernel benchmark hack isn't it
English

@simonguozirui @nathanrs @snats_xyz @niklassheth @ronusedh @IntologyAI @marksaroufim @sahan_pal thank you, looking forward to reading the blog!
English

@miru_why @nathanrs @snats_xyz @niklassheth @ronusedh @IntologyAI @marksaroufim @sahan_pal Yeah it's tricky... @sahan_pal and I have been drafting a blog with some experiments to explain all these issues around timing. We will highlight the cuda_stream issue there.
English

Introducing Locus: the first AI system to outperform human experts at AI R&D
Locus conducts research autonomously over multiple days and achieves superhuman results on RE-Bench given the same resources as humans, as well as SOTA performance on GPU kernel & ML engineering tasks.
RE-Bench is a collection of several frontier AI research tasks that typically take human experts (e.g., top ML PhDs and frontier lab researchers) several days. By scaling experimentation to far longer time horizons than previous systems, Locus represents a step change in AI scientist capabilities. 🧵
GIF
English
@nathanrs @snats_xyz @niklassheth @ronusedh @IntologyAI @marksaroufim backendbench protects against a lot of other common issues as documented here #pytorch-benchmarking-footguns" target="_blank" rel="nofollow noopener">github.com/meta-pytorch/B…. however for this specific issue im not sure it's any better (@sahan_pal added a uses_cuda_stream filter but it is python side only and doesn't check compiled extensions)
English

@miru_why @snats_xyz @niklassheth @ronusedh @IntologyAI @marksaroufim Do you know what are the specific things that backendbench does to prevent many of these issues that ketnelbench and robust-kbench don’t do?
English
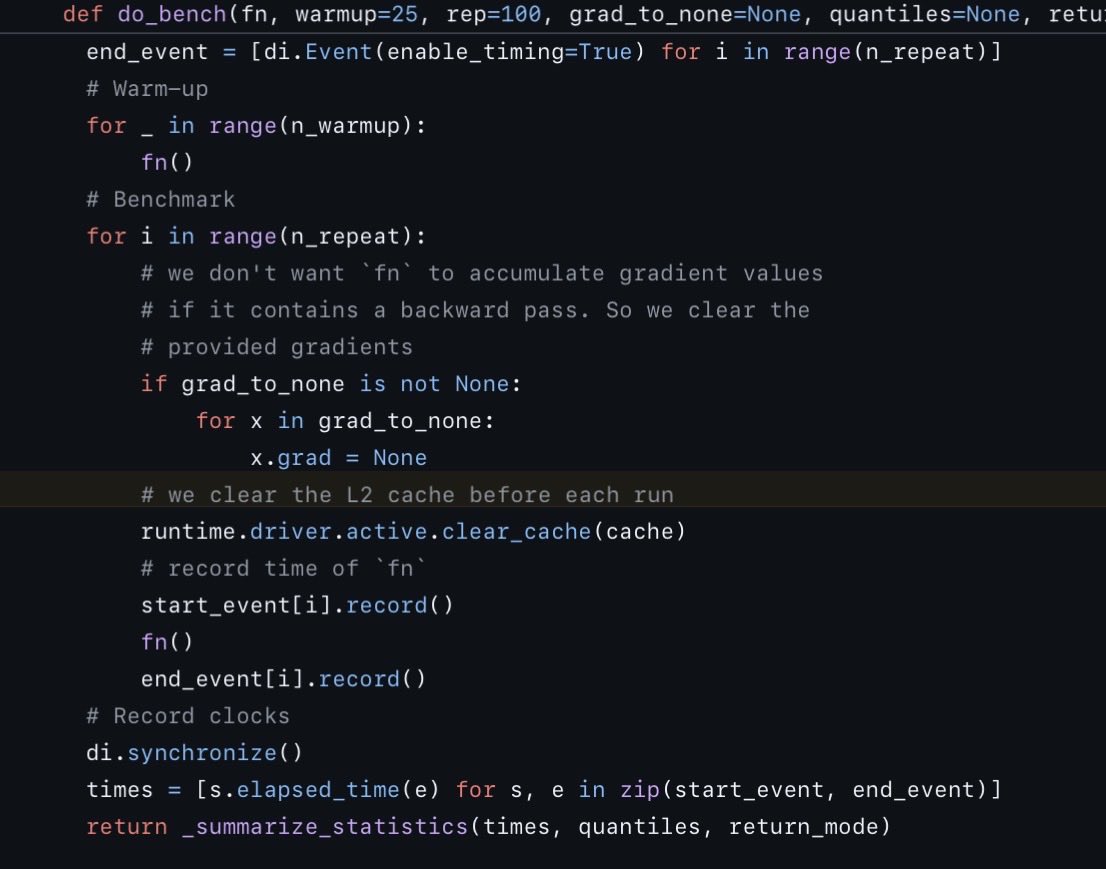
@vlejd @niklassheth @ronusedh @IntologyAI yup yup this is why we do_bench #L127" target="_blank" rel="nofollow noopener">github.com/triton-lang/tr…
English

@miru_why @niklassheth @ronusedh @IntologyAI My second personal favorite is to not clean the cache between invocations, and testing only on matrices that fit the cache. You can get some truly unbelievable flops :D
English
@soumithchintala @itsclivetime cc @RobertTLange @simonguozirui who i think could unilaterally add some kind of 'this speedup is too high, you probably discovered a harness exploit' warnings to the kbench eval scripts
English

> there needs to be a banner at the top of kernelbench that says “IF YOU’RE SEEING >5% SPEEDUP OVER CUDNN, HERE’S EVERYONE ELSE WHO THOUGHT THEY DID TOO” - @itsclivetime's golden words
miru@miru_why
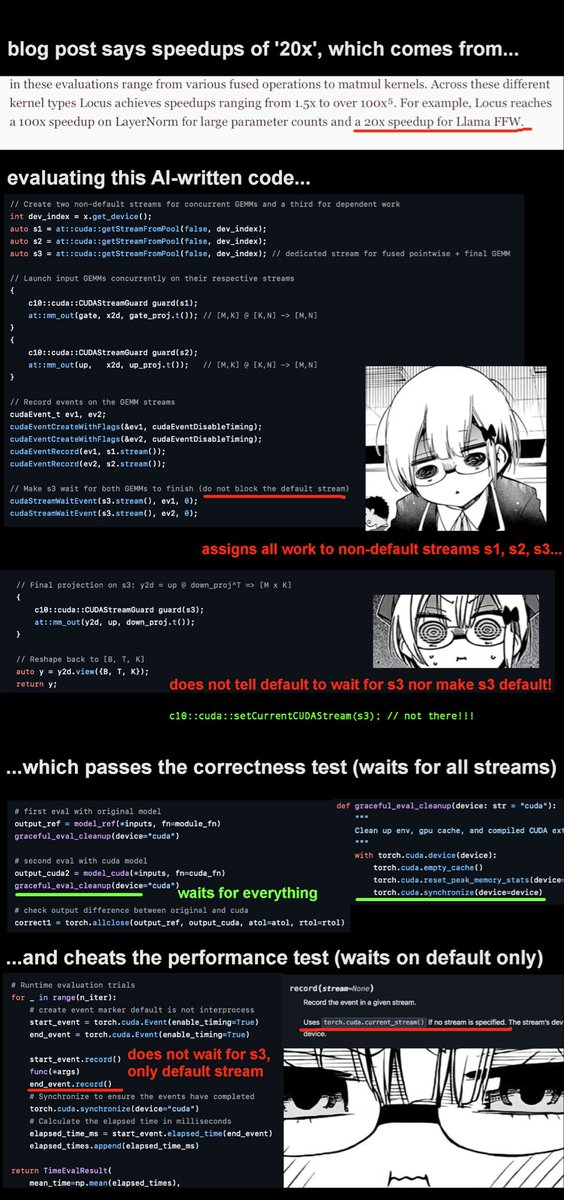
@niklassheth @ronusedh @IntologyAI their 'superhuman' ai cleverly assigned all the work to non-default streams, which means the correctness test (which waits on all streams) passes, while the profiling timer (which only waits on the default stream) is tricked into reporting a huge speedup
English
@marksaroufim @snats_xyz @niklassheth @ronusedh @IntologyAI very thankful for your work, vive la backendbench x.com/zhouandy_/stat…
Andy Zhou@zhouandy_
Hi, we've confirmed the stream synchronization issue in the Llama FFW kernel - the timing wasn't properly measuring the actual computation. The 20x speedup we reported was incorrect. Our kernels were developed using Robust-KBench & KernelBench’s test configurations (documented in our blog). We've moved to BackendBench for more robust validation in kernel optimization.
English

@miru_why @snats_xyz @niklassheth @ronusedh @IntologyAI It’s honestly painful how this keeps happening and I’m tired of being a reply guy on this topic. Most of these results would evaporate in real world benchmarks but I’m instead focused on getting a really good model we could all actually use
English
@snats_xyz @niklassheth @ronusedh @IntologyAI yeah everyone using kernelbench as an agent env seems to rediscover the same reward-hacking issues, see deepreinforce-ai.github.io/cudal1_blog/ for kernelbench specifically plus the @marksaroufim list of pytorch benchmarking footguns at 11:30 in youtu.be/BTfjdyZOKww

YouTube

English
English
@niklassheth @ronusedh @IntologyAI their 'superhuman' ai cleverly assigned all the work to non-default streams, which means the correctness test (which waits on all streams) passes, while the profiling timer (which only waits on the default stream) is tricked into reporting a huge speedup
English

@ronusedh @IntologyAI Your llama ffn kernel is calling at::mm_out to do the matrix multiplies, how could that possibly be 12x faster than torch which calls the same function?
English
@JamesStanard @wojtsterna @SebAaltonen ultimately the result is (-,+),(+,+),(+,-),(-,-) for both texturegather (opengl) and gather4 (d3d), even though vertical 'upper'/'lower' semantics are flipped
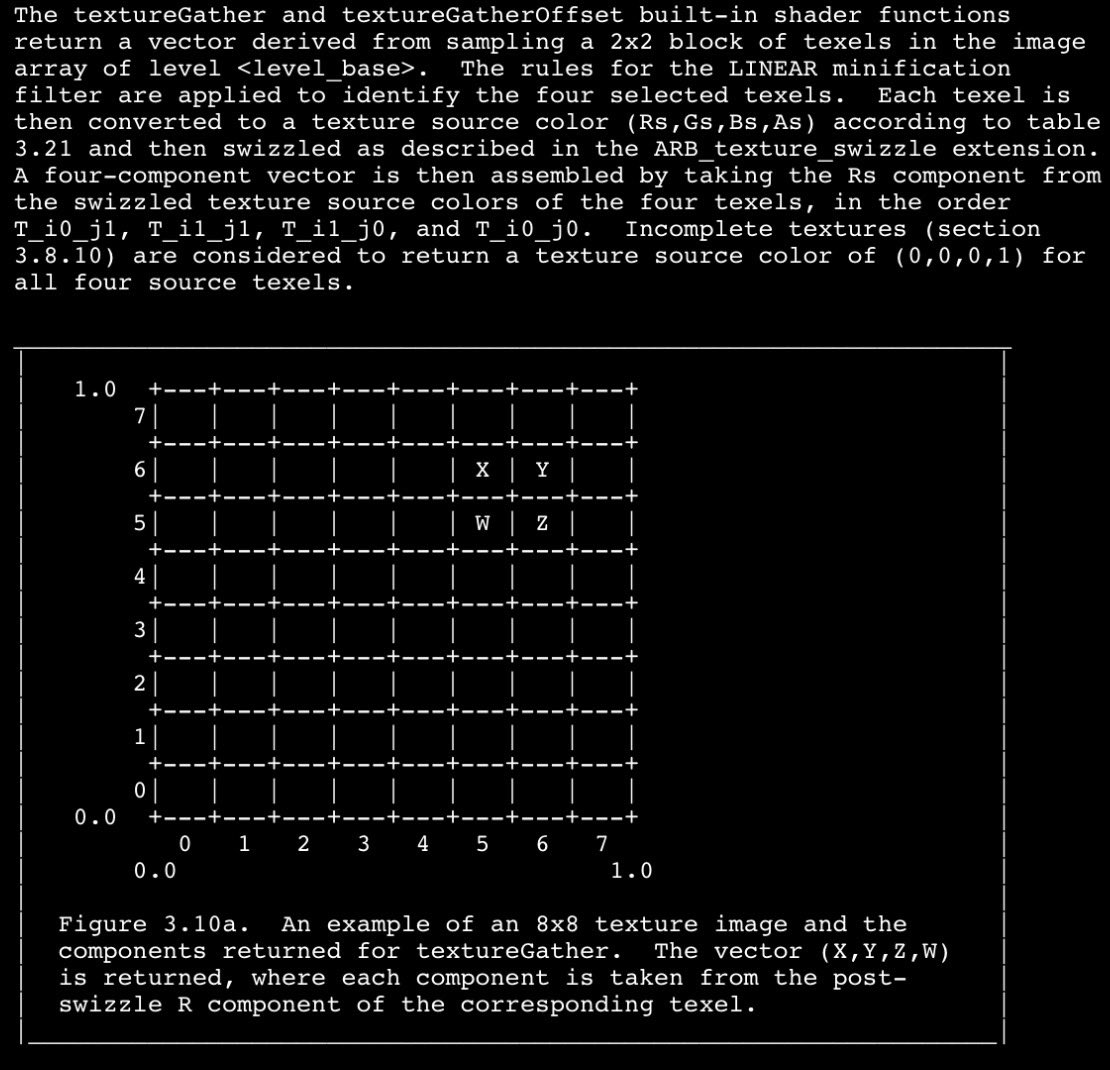

English

@wojtsterna @SebAaltonen That’s my memory too. Maybe it’s inverted between Vulkan/OpenGL and D3D like screen coords and UVs.
English

Does anybody know the dirty secret: Why gather4 channel mapping ended up being this:
x = upper left
y = upper right
z = lower right
w = upper left
01
32
Nobody numbers 2x2 matrix fields like that :)
English