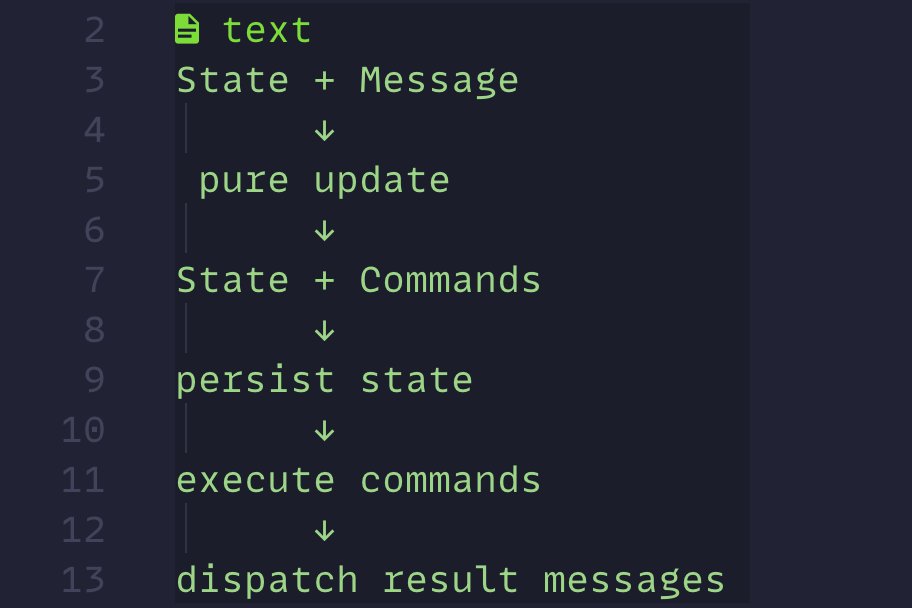
@haipingfu thanks for sharing, this is a very important area. how would you compare it against Aider Repomap? similar/different/better/worse?
English
zlumer.eth
1.4K posts
@zlumer
now: stablecoin payments. ex: CTO @slise_xyz (acquired, @alliance ALL9, @binance MVB S6), CEO @LocalPayAsia (backed by @colosseum)





Do you ever hit flow state with AI coding?



agentOS SDK got a glow up More coming later this week agentos-sdk.dev


Reactivity is overrated. Love this banger from Fable: > ... view updates when I say handle.update() — I have said it 281 times in this codebase and it has surprised me zero times. I do not miss guessing when React would re-render.