openai next model being a "new pre-trained base" is the big thing
if spud is trained from scratch on 2 years of new data and has a meaningfully different architecture, that would be a real step change.
the native omnimodal part matters too.
current models added vision later, but native multimodal training is different
🚨 NEW: The AI Big 10's concentration has hit 41%, matching peak levels seen before the Dot Com crash and other historic bubble bursts, per BofA Global Research.
AI. LLMs. Hallucinations.
"More than 110,000 of the 7 million or so scholarly publications from 2025 contain invalid references."
"One analysis of nearly 18,000 papers accepted by three computer-science conferences found a sharp increase in references that cannot be traced to actual scholarly publications."
"Now the problem is not just inaccuracy, it’s about fake citations."
"Johnston, co-lead editor of the Review of International Political Economy (RIPE)... says that she rejected 25% of some 100 submissions in January 'because of fake references'."
Link: nature.com/articles/d4158…
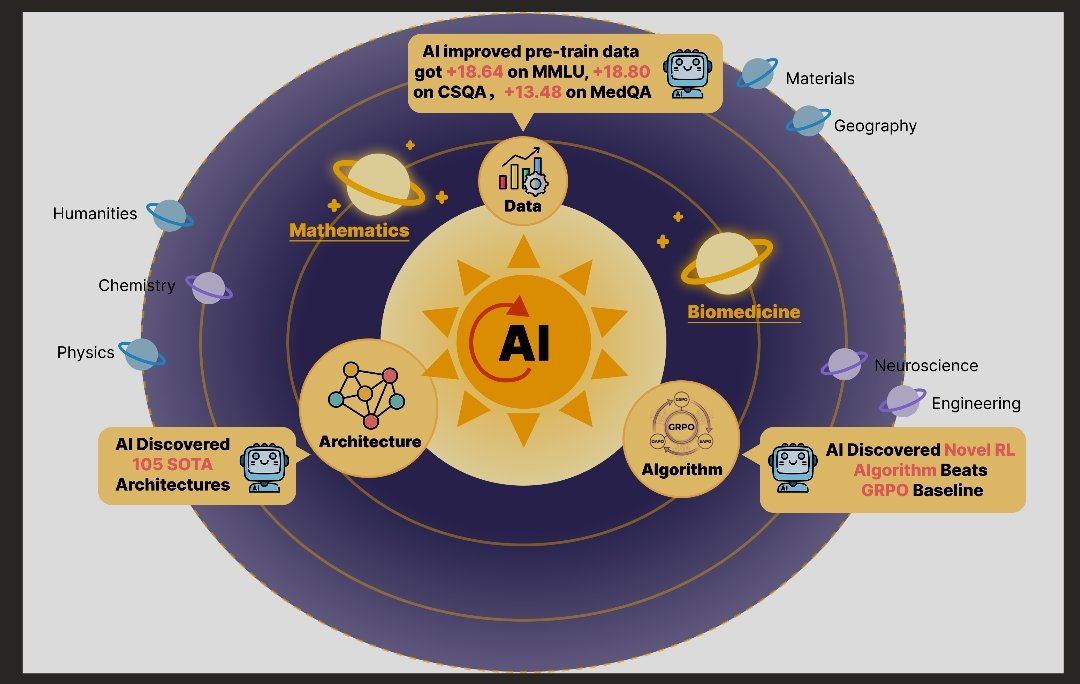
**AI Just Learned to Evolve Itself: Meet ASI-Evolve**
What if AI could design, test, and improve its own successors with minimal human input? That future just got much closer.
On March 31, 2026, a team from Shanghai Jiao Tong University, SII, and GAIR released the paper “ASI-Evolve: AI Accelerates AI.” It introduces an agentic framework that closes the slow research loop by creating a fast, self-improving cycle.
The system adds a cognition base with human knowledge and priors plus a dedicated analyzer that turns experimental results into reusable insights.
Results are striking. In neural architecture search, it discovered 105 new state-of-the-art linear attention models, with the best one nearly tripling recent human improvements. For pre-training data curation, it improved average benchmark performance by 3.96 points, including over 18 points on MMLU. Its reinforcement learning algorithms also beat strong baselines by up to 12.5 points on AMC32, 11.67 on AIME24, and 5.04 on OlympiadBench.
ASI-Evolve is the first unified framework demonstrating AI-driven discovery across data, architectures, and learning algorithms. Early experiments suggest it can accelerate progress even in mathematics and biomedicine.
This is more than an incremental step. It offers compelling early proof that AI can meaningfully accelerate its own development. The next few years are going to be wild.
DeepSeek Sparse Attention gets a hierarchical upgrade
HISA replaces the flat token scan with a two-stage block-then-token filtering pipeline, eliminating the indexing bottleneck at 64K context without any additional training.
Quantum Computing Just Got WAY Easier
We just went from "millions of qubits someday" to practical quantum computers much sooner than expected.
Scientists developed a new quantum computing method that slashes qubit requirements massively, from ~1,000 qubits per logical unit down to just 5.
"The team says a fully functional quantum computer could operate with as few as 10,000 to 20,000 qubits, far below the millions previously believed necessary."
By improving quantum error correction and using neutral atom systems, they make quantum machines far more efficient and scalable, bringing real world quantum computing much closer.
𝗔𝗜 𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝗯𝗶𝗹𝗶𝘁𝘆 is a must have in your tool belt as an AI Engineer. 𝗧𝗿𝗮𝗰𝗶𝗻𝗴 sits at the core of it, why is it important?
Tracing and instrumentation of software have been around for decades now. With AI systems resembling regular software even more, we are now moving the practice here as well (with a few key differences).
Let’s look into the process of tracing from a perspective of a naive RAG system.
𝘍𝘦𝘸 𝘥𝘦𝘧𝘪𝘯𝘪𝘵𝘪𝘰𝘯𝘴:
𝘼) An Orchestrator in the GenAI system application is the central piece of software that orchestrates the end-to-end process. Think of apps using LangChain, LlamaIndex or Haystack.
𝘽) Trace is the end-to-end application flow from the entry point till the answer is produced, it is composed of smaller pieces called spans.
𝘾) Span is a smaller piece of the application flow that represents an atomic action like a function call or a database query. They can be sequential, or run in parallel.
ℹ️ As part of span we capture general metadata like start and end time, inputs and outputs of the span. On top of this metadata we track information specific to the GenAI system elements.
What might a trace look like for a naive RAG system?
𝟭. A query that has been submitted to the chat application.
𝟮. The query is embedded into a vector.
✅ Additional metadata like input token count is persisted with the span so that we can estimate the cost of the procedure.
𝟯. ANN lookup performed against the Vector DB to retrieve the most relevant context.
✅ Additional metadata about the query is persisted as part of the span together with the retrieved pieces of context and their relevance.
𝟰. A prompt is constructed from the system prompt and retrieved context.
𝟱. The prompt is passed to the LLM to construct the answer.
✅ Additional metadata about input and output token count is captured together with the span so that we can estimate the cost of the procedure.
𝘞𝘩𝘺 𝘪𝘴 𝘵𝘳𝘢𝘤𝘪𝘯𝘨 𝘰𝘧 𝘎𝘦𝘯𝘈𝘐 𝘴𝘺𝘴𝘵𝘦𝘮𝘴 𝘪𝘮𝘱𝘰𝘳𝘵𝘢𝘯𝘵?
- These applications are usually complex chains, errors can happen in different steps of your application. E.g. Embedding of query is taking longer than expected or you have reached API limits of LLM provider.
- Cost for calling LLM APIs will be variable depending on the length of inputs and produced outputs. You would usually trace this information and analyze it to help forecast expenses.
- GenAI systems are non-deterministic and will deteriorate over time. They need to be evaluated on span level rather than input/output of the entire system so that you can tune each piece separately.
- …
Are you tracing your Agents? Let me know in the comments 👇
Can AI predict what your next research paper should be about?
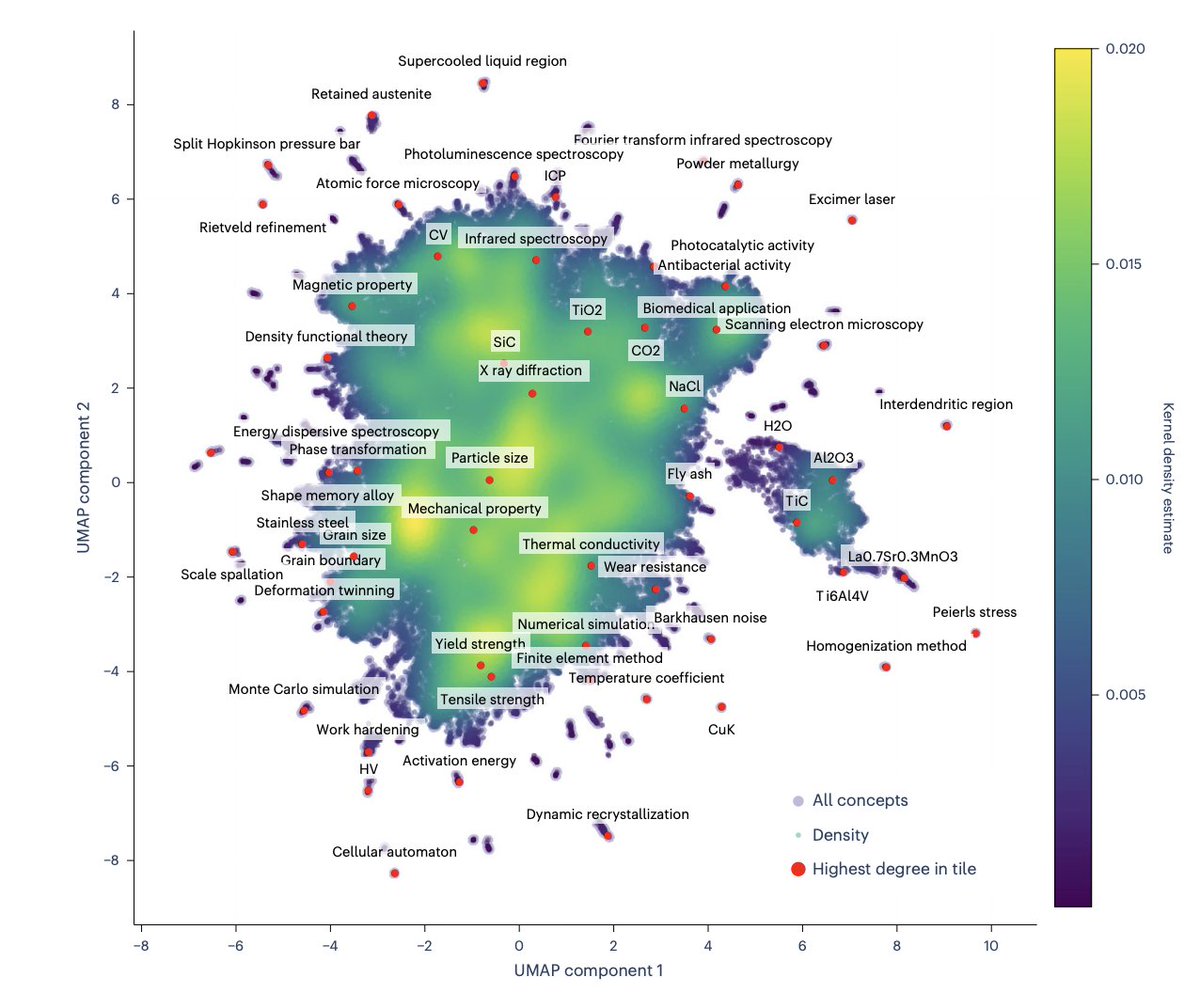
Science grows faster than any single researcher can read. In materials science alone, hundreds of thousands of papers now exist, and the most promising ideas often live at the intersection of concepts no one has yet thought to combine.
Marwitz and coauthors take this challenge head on. Starting from ~221,000 materials science abstracts, they fine-tune a LLaMA-2-13B model to extract key concepts — not just keywords, but normalized, semantically meaningful phrases — and build a concept graph with ~137,000 nodes and 13 million edges, where each edge reflects the co-occurrence of two concepts in a published abstract.
The graph evolves over time, and that temporal signal becomes the basis for link prediction: which pairs of currently unconnected concepts will appear together in a future paper? They test several model families — a graph topology baseline (NN on hand-crafted features), concept embeddings from MatSciBERT, a GraphSAGE GNN, and hybrid mixtures of these. The best single metric goes to the Mixture of GNN + Embeddings, reaching AUC 0.943.
The most interesting finding is about distance. Most concept pairs in the graph are already connected through just one or two intermediate nodes. The baseline model is excellent at predicting nearby connections (dprev = 2, recall 73%) but nearly blind to more distant ones (dprev = 3, recall 5.9%). Adding semantic embeddings raises recall at distance 3 to 35% — and those are exactly the combinations most likely to represent genuinely novel research directions.
To validate this beyond metrics, they ran 30-minute interviews with ten materials scientists, each receiving a personalized report of AI-suggested concept pairs. Of 292 evaluated suggestions, 26% were rated as novel and inspiring — including combinations like "conventional ceramic + graphene oxide" and "in-plane polarization + organic solar cell" — ideas the experts had not previously considered.
For R&D teams in industry, this is a concrete step toward AI-assisted hypothesis generation. In sectors like battery materials, catalysis, or specialty coatings, where the literature is vast and cross-domain insight is rare, a system that surfaces non-obvious concept bridges could meaningfully compress the time between literature review and experimental design.
Paper: Marwitz et al., Nature Machine Intelligence (2026) — CC BY 4.0 | nature.com/articles/s4225…
Demis Hassabis assembled a secret team of ~20 researchers inside DeepMind to train high-frequency trading algorithms, reportedly aiming to rival Renaissance Technologies. Google disapproved, and the project was quietly disbanded.
Marc Andreessen says AI is the "silver bullet excuse" for companies laying people off, but most layoffs are actually due to higher interest rates and overstaffing during COVID:
"This entire labor displacement thing is 100% incorrect. It's completely wrong. It's classic zero-sum economics."
"It was the combination of the two—interest rates going to zero during COVID, and then the complete loss of discipline at all these companies when they went virtual and when employees just became an icon on a screen."
"What you have happening right now is that essentially every large company is overstaffed. We could debate how much—it's at least overstaffed by 25%. I think most large companies are overstaffed by 50%. A lot of them are overstaffed by 75%."
"And now they all have the silver bullet excuse—it's AI."
@pmarca with @HarryStebbings
Google proves the math for cracking Bitcoin's encryption in 9 minutes now exists — the only missing piece is the hardware. 🤯
With precomputation, an attacker could derive a private key from a public key in roughly 9 minutes.
Bitcoin's average block time is 10 minutes.
The core finding is precise and unsettling: Shor's algorithm can now be compiled to solve the 256-bit elliptic curve discrete logarithm problem with roughly 1,200 logical qubits and 90 million Toffoli gates.
Translated to hardware, that means fewer than half a million physical superconducting qubits, nearly a 20-fold reduction over the best prior estimates from Litinski's 2023 work.
It means "on-spend" attacks, where a transaction is intercepted in the mempool and forged before confirmation, become plausible for fast-clock quantum machines.
The paper introduces a critical architectural distinction. Superconducting and photonic platforms, with microsecond-scale error correction cycles, can threaten active transactions. Neutral atom and ion trap systems, two to three orders of magnitude slower, can only threaten static holdings with long-exposed keys.
Approximately 6.9 million BTC sit in addresses with exposed public keys today. Around 1.7 million of those are locked in early P2PK scripts from the Satoshi era, almost certainly with lost private keys, forming a permanent multibillion-dollar quantum target.
Ethereum faces distinct risks: its account model, BLS-based validator signatures, and KZG commitment scheme in data availability sampling each present separate at-rest attack surfaces.
The authors validated their resource estimates using a zero-knowledge proof, a first for quantum cryptanalysis, allowing verification without revealing the attack circuit itself.
The margin between quantum capability and cryptographic failure is narrowing faster than most migration timelines assume.
----
quantumai. google/static/site-assets/downloads/cryptocurrency-whitepaper.pdf
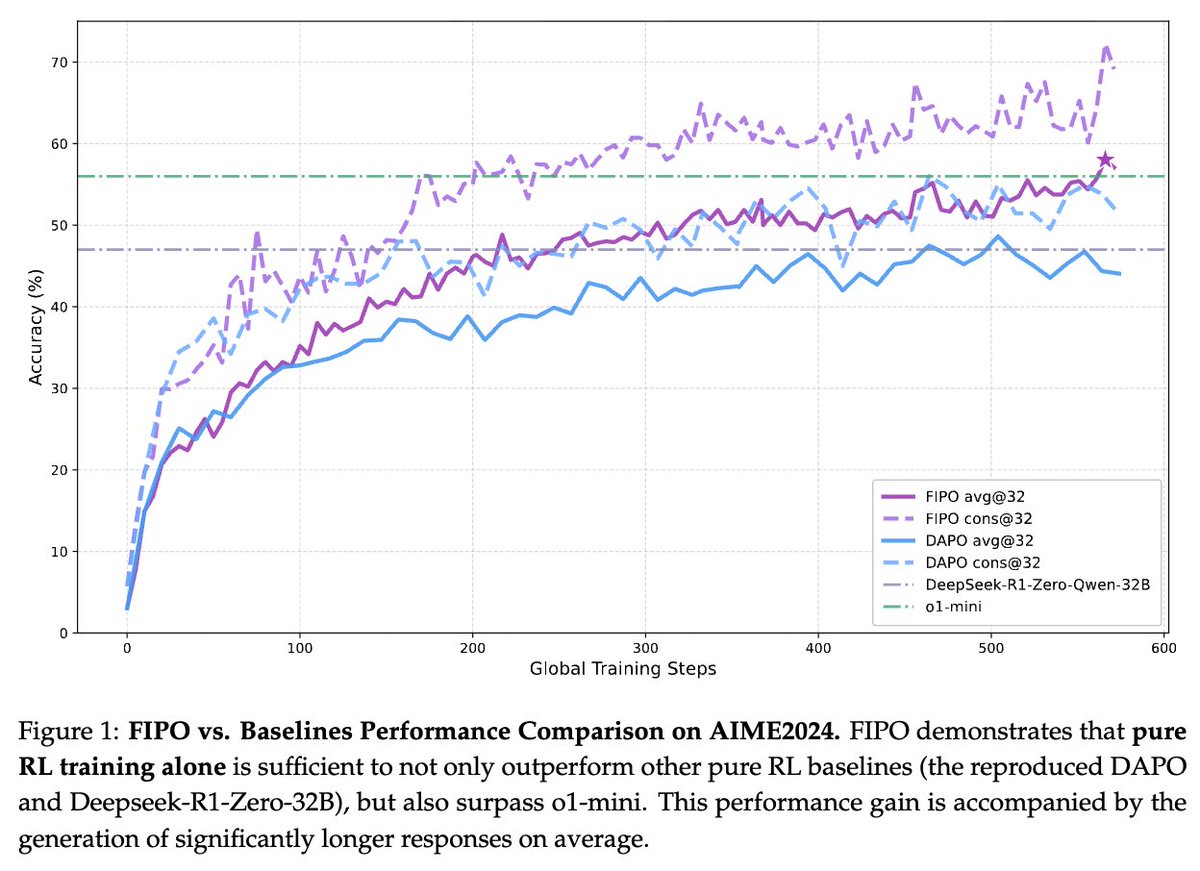
FIPO: eliciting deep reasoning with future-aware credit assignment
Alibaba's Qwen Pilot team replaces outcome rewards with Future-KL, tracking each token's influence on future reasoning. Qwen2.5-32B scales from 4k to 10k+ tokens, hitting 58% on AIME 2024, outpacing o1-mini and DeepSeek-R1-Zero.
❓How can we build AI agents that do what scientists actually do? Is scientific discovery merely a search problem?
🚀 Meet SAGA: Scientific Autonomous Goal-evolving Agents. Five discovery tasks across chemistry, biology & materials science, with wet-lab validation.
🚨BREAKING: Stanford and Microsoft just built an AI scientist that writes medical research papers that actually pass peer review.
Not summaries. Not drafts. Full papers reviewed and accepted by real scientists.
This is not a demo and this is not a prototype. A peer-reviewed conference just accepted a paper that no human wrote, and most people have absolutely no idea it happened.
The system is called Medical AI Scientist and it works in three stages that run completely on their own.
First, it reads medical literature, identifies real clinical gaps, and generates a research hypothesis grounded in actual disease evidence, not a hallucination and not a generic idea pulled from thin air. Then it writes the code, runs the experiment inside a secure environment, catches its own errors, and fixes them without any human stepping in. Then it writes the full paper, including the introduction, methods, results, figures, ethics statement, citations, and LaTeX formatting, from start to finish, autonomously.
They tested it against GPT-5 and Gemini 2.5 Pro across 171 real medical research cases covering 19 clinical tasks, and the results were not close. Medical AI Scientist successfully completed experiments 91 to 93 percent of the time. GPT-5 managed 60 to 75 percent. Gemini 2.5 Pro collapsed somewhere between 40 and 53 percent.
Then they ran the part that genuinely broke my brain. Ten independent medical experts with over five years of first-author publishing experience reviewed the AI-generated papers side by side with real human papers from MICCAI, ISBI, and BIBM, the top conferences in medical imaging, and nobody knew which was which.
The AI papers scored competitively on novelty, clarity, coherence, and reproducibility across the board, and one paper was accepted at a peer-reviewed conference after a full review process.
Here is what nobody is saying out loud.
Medical research has a brutal bottleneck where ideas pile up, experiments take months, papers take even longer, and patients wait the entire time. That problem just got a serious solution, and the implications for healthcare are enormous.