Shiyu Ni
51 posts

Shiyu Ni
@Shictyu
Ph.D candidate at the Institute of Computing Technology, Chinese Academy of Sciences | Trustworthy LLMs; Adaptive RAG







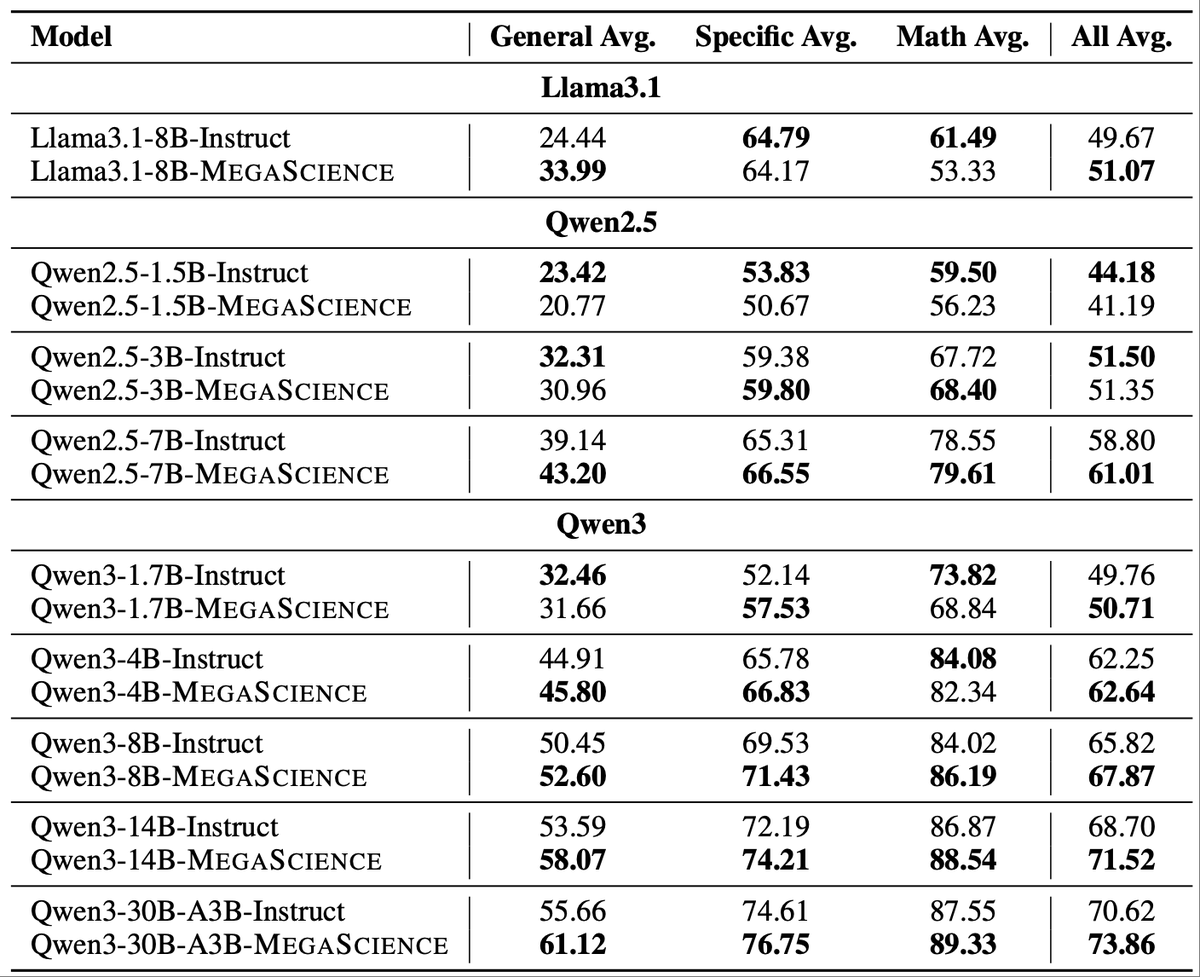

Excited to share that our two papers have been accepted to #ICML2025! @icmlconf However, I can't be there in person due to visa issues. What a pity.🥲 Feel free to check out our poster, neither online nor offline in the Vancouver Convention Center. Programming Every Example: Lifting Pre-training Data Quality Like Experts at Scale accepted by the Main conference (Poster) arxiv.org/abs/2409.17115 OctoThinker: Mid-Training Incentivizes Reinforcement Learning Scaling accepted by the workshop 2nd AI for Math Workshop @ ICML 2025 (poster) arxiv.org/abs/2506.20512

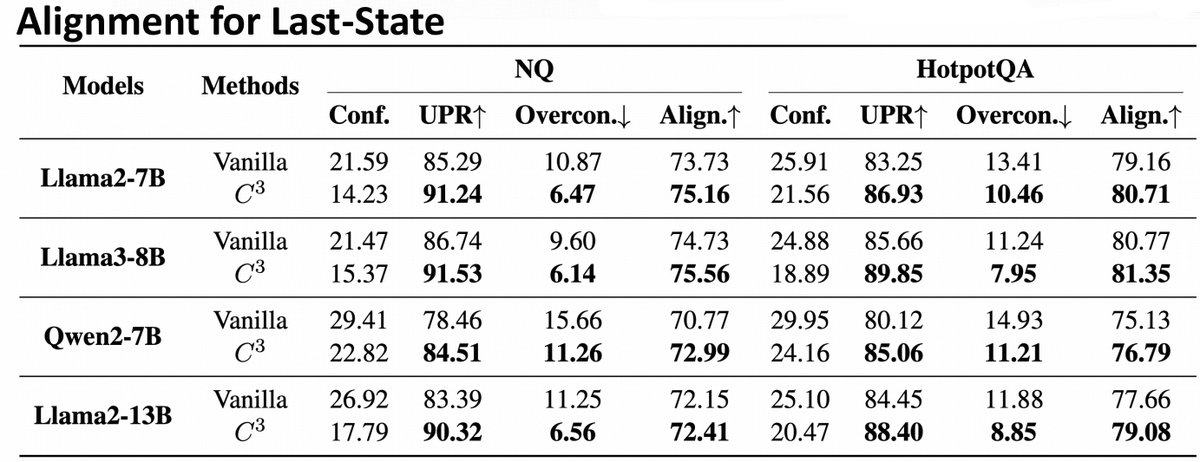
🥳Happy to share that our paper "Towards Fully Exploiting LLM Internal States to Enhance Knowledge Boundary Perception" has been accepted by #ACL2025! We explore leveraging LLMs' internal states to improve their knowledge boundary perception from efficiency and risk perspectives.