
Aarush Sah
2.6K posts

Aarush Sah
@aarush
Superintelligence @Meta. prev @NVIDIA LPU, @GroqInc
Menlo Park, CA เข้าร่วม Eylül 2022
705 กำลังติดตาม8.1K ผู้ติดตาม

@aarush @AnthropicAI I just wanna know where you rank on the token leaderboard
English
Wow. Claude Mythos represents at 20% jump on SWE-bench Pro over the next best model, GPT-5.4
Congrats to the @AnthropicAI team!

Anthropic@AnthropicAI
The Claude Mythos Preview system card is available here: anthropic.com/claude-mythos-…
English
@Nottlespike @AnthropicAI Interesting. Haven’t read the technical report in full yet, will have to do some poking around
English





Very excited for you all to see Muse Spark! It’s a capable model that excels in multimodal and agentic tool use tasks.
Spark is the first (of many) steps towards Personal Superintelligence, and I look forward to seeing how our models evolve as we get closer to that goal :)
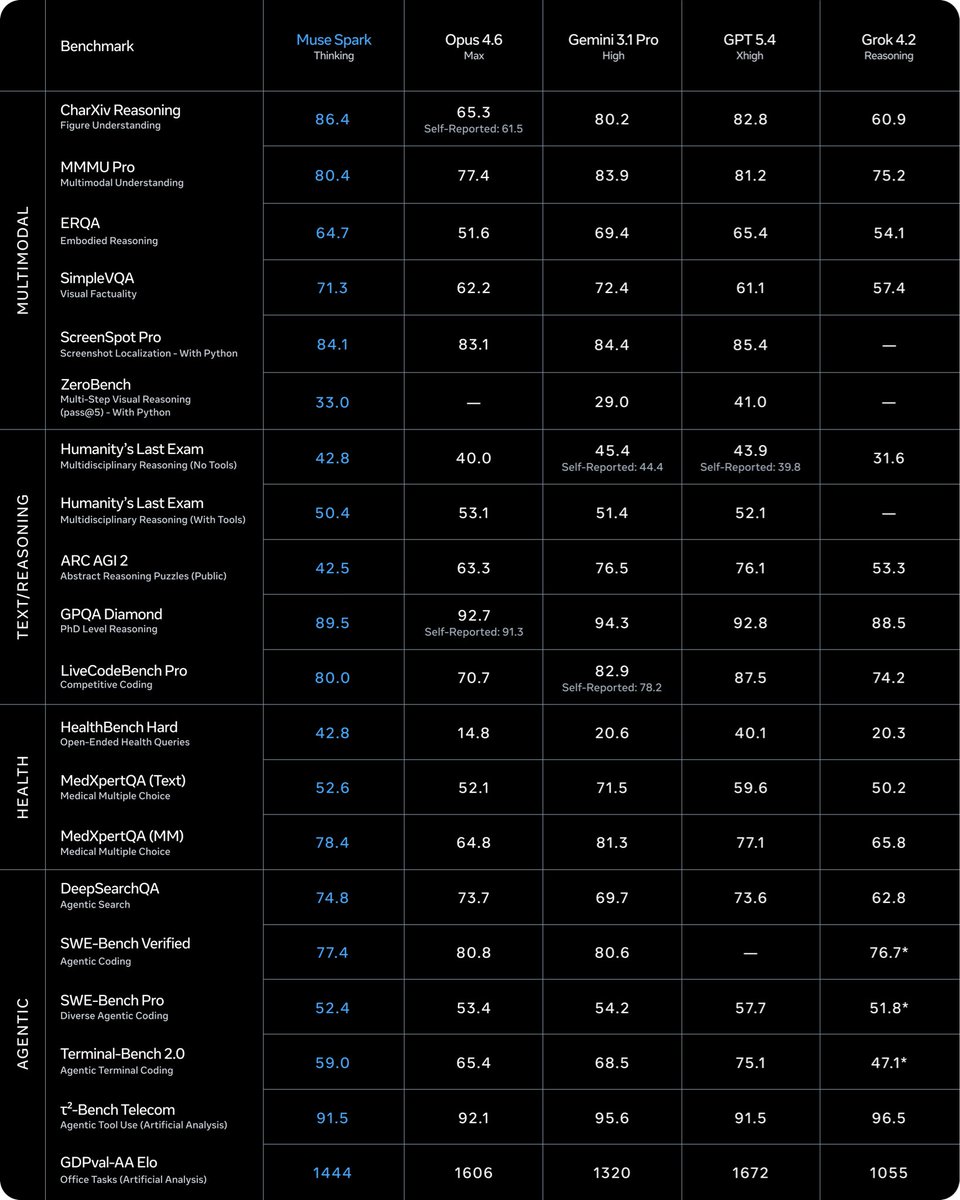
Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English
I would argue that the capabilities of Claude Mythos are much more likely to cause immediate harm if widely released without appropriate safeguards.
And even if not, it’s much harder to put the genie back into the bottle rather than simply release the genie later

Julien Chaumond@julien_c
“gpt2-large is too powerful to be publicly released” vibes
English

Can’t wait to join the team at @openai building codex. Would love to hear what you love about it or want changed. We’re moving fast. DMs open.
English

I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: devtechjr.github.io/turboquant_cut…
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep @GavinSherry
English

Hey twitter/x, one of my goals this year is to share more things that excite me with the world. I’m starting here so let me introduce myself:
My name is Angelina, I’m 22, and I currently live in SF! For the past six months, I’ve been working at Meta Superintelligence Labs on model training infra and data strategy👩🏻💻
Before that I was at UCLA studying CS and Econ and spent a lot of my time in college building in fintech and investing in early stage companies (General Catalyst Venture Fellows, NEA, Mantis VC).
I love food, traveling to new places, a good story, snowboarding, and hosting dinners and game nights🕺🏻
I also love meeting new people, feel free to say hi :)

English
The scale of a frontier lab's operations is humbling to experience firsthand
English

We've entered into an agreement to join OpenAI as part of the Codex team.
I'm incredibly proud of the work we've done so far, incredibly grateful to everyone that's supported us, and incredibly excited to keep building tools that make programming feel different.
English
Sometimes it’s easy to forget that LLMs are marvels of engineering.
Like what do you mean we have a machine that can actually understand the meaning behind a bunch of characters, the same way a human can?!
English
Amazing work from @JonathanRoss321, @sundeep, @GavinSherry and the team. Very excited to see this work come to fruition 💚🤝🧡
Ryan Shrout@ryanshrout
On the right: Vera Rubin. Middle: NVLink 6th Gen Left: The brand new Groq system
English


Aarush Sah รีทวีตแล้ว

LPU in Ian Buck's hand, sitting in the audience at GTC

English



Went to an Apple store yesterday and they're still sold out of mac minis 💀
English
Aarush Sah รีทวีตแล้ว
GPU ♥ LPU: Everything You Wanted to Know
I’m joining David Senra (@FoundersPodcast) at @NVIDIAGTC for a conversation about the reality of modern inference. This is your opportunity to learn why Nvidia and Groq partnered together, and what it means for the future of inference.
English
English

Some updates: I've always been bullish on TML, and I actually joined TML this Monday
Looking back, I am feeling so lucky that I have the privilege to work closely with the best optimization experts on the Muon optimizer ( @Jianlin_S from Kimi and @clu_cheng from Meta). Now I am so excited to be able to work with @jxbz and build new cool things!
(On the other hand, there have always been some bad rumors about Meta TBD's potential failure. That's not true! From my personal experiences, it really has the best talents in the field, and I really enjoyed learning from the lab. The avocado model will for sure be great!)
JingyuanLiu@JingyuanLiu123
hmm I sort of disagree and I am bullish for TML. I think they really really have the top talents that I admire in the field, e.g. Jeremy and Sam for optimization, Songlin for Attn, Lia for MoE, Andrew for FSDPv2, and a bunch more folks it's just natural that it takes a while to publish good models: - dpsk starts to publish papers in 2023, even piblished dspkv2 (which I think is already amazing) in mid 2024 and nobody cares, until dpskv3 and r1 - msh took 10+ month to deliver a first not bad long ctx model in 2023 and be silent for the whole 2024 year, and starts to catch up gradually in 2025 - qwen starts to be a much better model than llama until qwen2.5, mid or late 2024, while the lab has been there forever it takes time to get infra and data done, but as long as you have good folks, and principled ways of doing science and experiments, some time or later, scaling laws will pay back
English