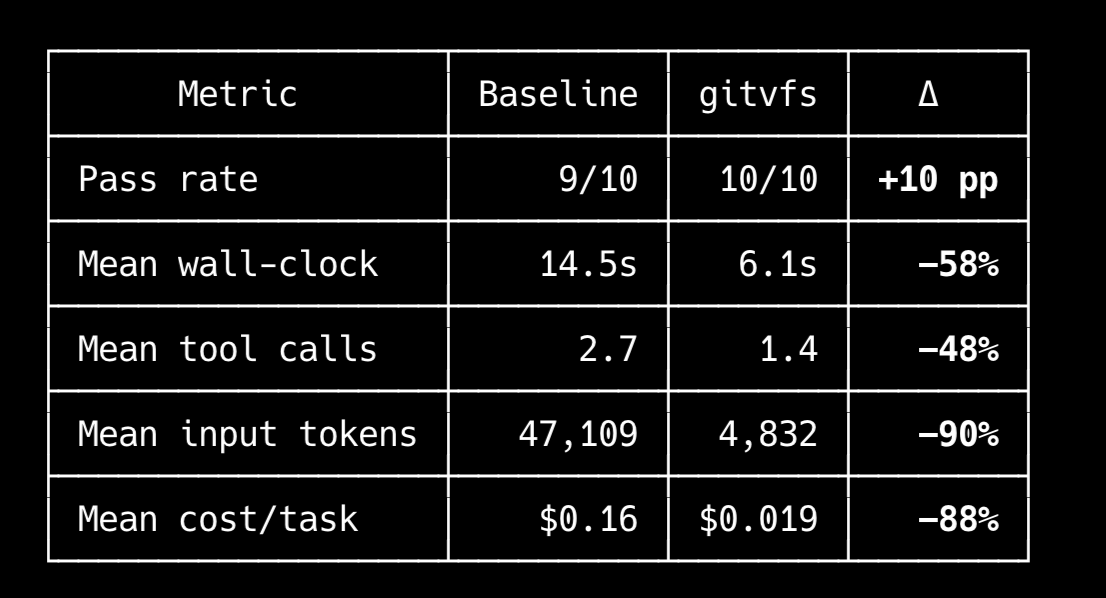
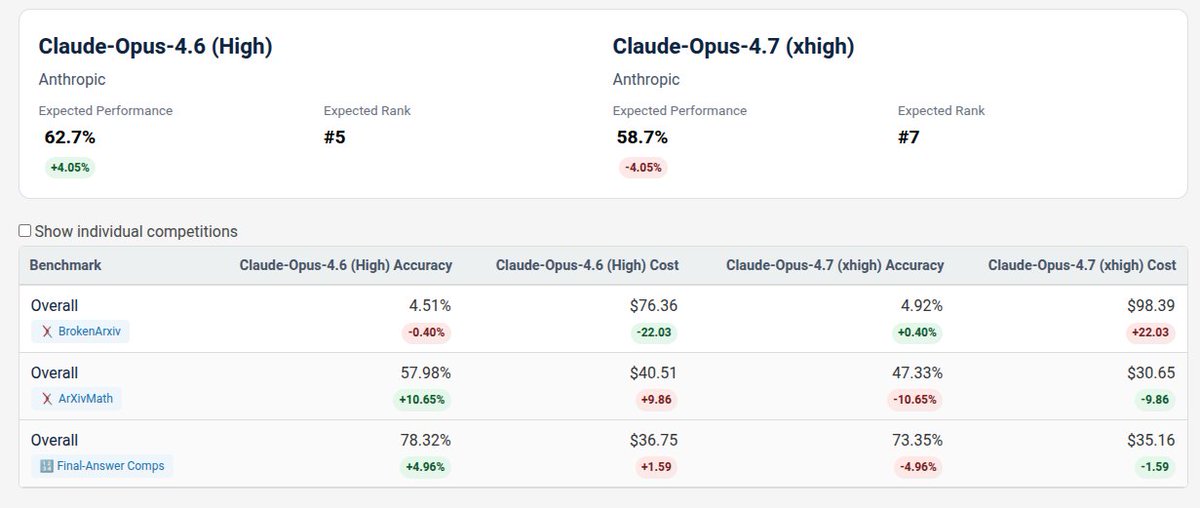
@paulabartabajo_ how did the browser-control eval handle small dom changes?
English
Suresh
6K posts

@_Suresh2
MSc Software Engineering @ Chongqing University ’26 | Researching AI x Software Engineering (AI for SE & SE for AI) | 🇵🇰➡️🇨🇳


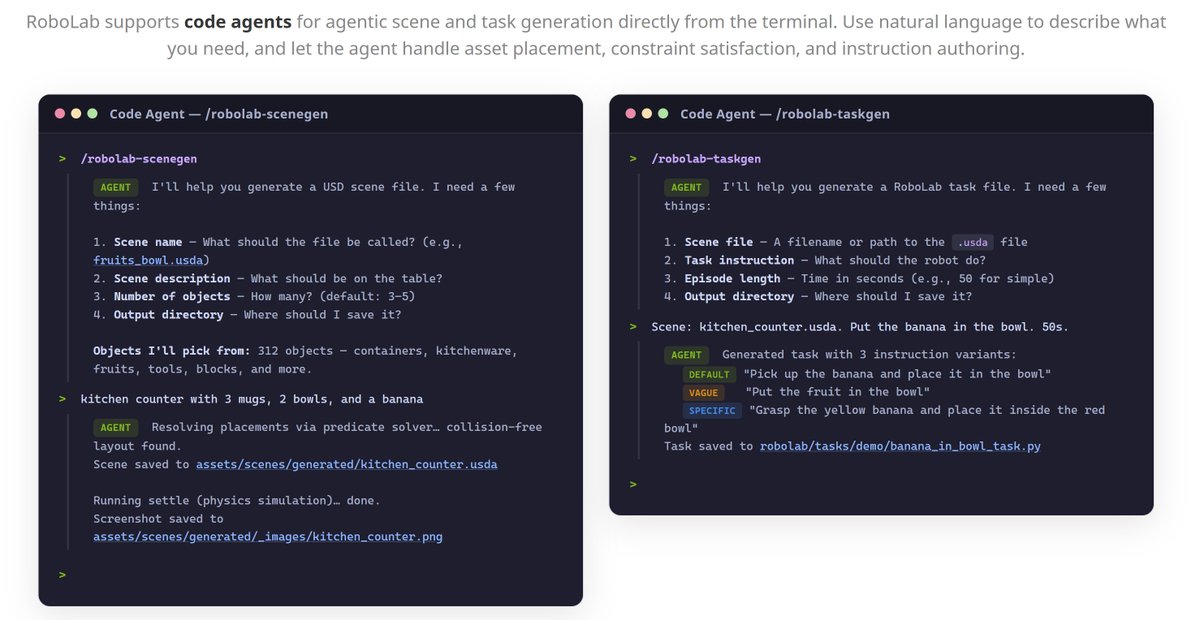
Generalist robot policies need a benchmark that works across any robot and any policy. 🦾 Introducing RoboLab, a high‑fidelity simulation benchmark built on NVIDIA Isaac and Omniverse to evaluate generalist robot policies in diverse, photoreal, physics‑based environments. Coming soon to the NVIDIA Isaac Lab‑Arena roadmap for large‑scale, robotic policy evaluation. 📖 nvda.ws/47RbOgX #NationalRoboticsWeek


Modern LLMs are getting more capable, but not necessarily more calibrated. This work starts from a simple observation: scaling capability does not automatically resolve overconfidence. To study this, we propose CaOPD, a calibration-aware on-policy distillation framework


🚨Breaking Spud (GPT 5.5) leaked ( for a few minutes ) As well as - Oai 2.1

There's been a lot of excitement about pluralistic value alignment 🌈 — AI that reflects the full range of human perspectives But no formal way to benchmark whether we're actually making progress. 🤔 Introducing 𝐎𝐕𝐄𝐑𝐓𝐎𝐍𝐁𝐄𝐍𝐂𝐇. 🎉Accepted to #ICLR2026 1/n 🧵

🇧🇷ICLR 2026 paper🇧🇷 Your agent's skills don't transfer. On a new site, only 18% skills get reused — so there's no continual learning, just relearning every time. How do agents learn skills that actually generalize? Introducing PolySkill to make agents smooth across sites 🧵


🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…





The new generation of open state-of-the-art single and multi-vector retrieval models is here It's time, DenseOn with the LateOn 🎶 @LightOnIO releases models that leap past existing ones, and everything you need to do the same!