
Nikitha Suryadevara
369 posts

Nikitha Suryadevara
@__nikitha
lead product for inference @togethercompute. invest in ai/ml, infra, dev tools. ex @temporalio, @google
San Francisco, CA شامل ہوئے Temmuz 2011
317 فالونگ1.8K فالوورز

Nikitha Suryadevara ری ٹویٹ کیا

me explaining my intolerance of the heat - “like a flower i wilt in the sun”
English
Nikitha Suryadevara ری ٹویٹ کیا

How about a Fetch API that works on all websites?
Introducing the Browserbase Fetch API, the fastest and cheapest way to extract content from the entire web.

English
Nikitha Suryadevara ری ٹویٹ کیا

Together GPU Clusters now includes autoscaling, RBAC, full-stack observability, and self-healing operations built in.
Move from experimental GPU infrastructure to production-ready AI platforms with elastic capacity, multi-team governance, and automated failure recovery.

English
Nikitha Suryadevara ری ٹویٹ کیا

Introducing Hedra Agent, the unified intelligence for visual understanding and creation.
Go from idea to content with extraordinary efficiency.
Describe the outcome you want, and the agent handles the formatting, platform adaptation, and style. Whether it is a social post, a product ad, or a launch video, Hedra Agent orchestrates it start to finish.
Drop in your product page, get back a full campaign with hero shots, social formats, and copy. Share a trending format you like. Agent recreates it in your voice and visual style.
Describe the video you've been picturing, Agent builds it from scratch.
A self-improving partner for your visual content.
The era of vibe creation is here.
English

every single person i know who joined an AI startup in the last 12 months has gained weight
it’s true i don’t make the rules, ask me how i know
English
Nikitha Suryadevara ری ٹویٹ کیا

The FA4 paper is finally out after a year of work. On Blackwell GPUs, attention now goes about as fast as matmul even though the bottlenecks are so different! Tensor cores are now crazy fast that attn fwd is bottlenecked by exponential, and attn bwd is bottlenecked by shared memory bandwidth.
Some fun stuff in the redesigned algorithm to overcome these bottlenecks: exponential emulation with polynomials, new online softmax to avoid 90% of softmax rescaling, 2CTA MMA instructions that allow two thread blocks to share operands to reduce smem traffic.
Ted Zadouri@tedzadouri
Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed! joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao) 1/
English
our first AI native conference @togethercompute let’s goooo!
fitting to kick off with grant lee from @GammaApp, could not survive without it

English
English


about once a quarter when i stop to take a breath, i realize how much FUN i’m having working with and building AI. work feels like play again
English
Nikitha Suryadevara ری ٹویٹ کیا

We just open sourced a dataset that cost us $130k to generate!
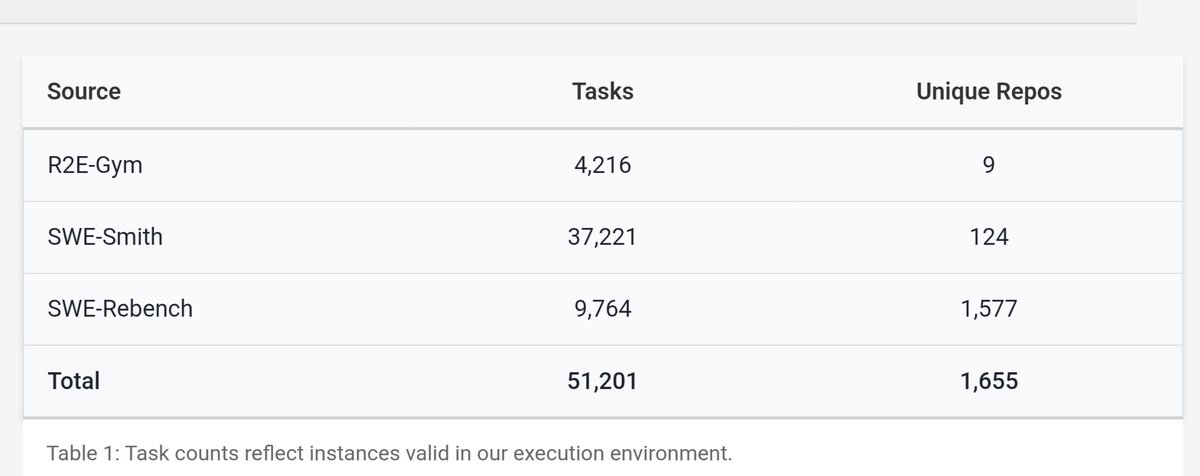
It's 6.7B tokens of agentic coding traces of 51k tasks across 1.6k unique repos.
You can SFT on it to make your models better coding agents!
Together AI@togethercompute
We’re open-sourcing CoderForge-Preview — 258K test-verified coding-agent trajectories (155K pass | 103K fail). Fine-tuning Qwen3-32B on the passing subset boosts SWE-bench Verified: 23.0% → 59.4% pass@1, and it ranks #1 among open-data models ≤32B parameters. Thread on the data generation pipeline 🧵
English
Nikitha Suryadevara ری ٹویٹ کیا

The S2 cloud service is now GA. We also raised a $3.85M seed round led by @Accel with participation from @ycombinator, other funds and angels like @theo!
English

Grateful and energized: @render has raised $100M at a $1.5B valuation.
This funding milestone is validation of where cloud infra for AI-native applications is headed and the trust our developer community places in us.
Onward!
English
when people ask why i’m not much of a skier. 30s are too old for broken bones
no context memes@nocontextmemes
English