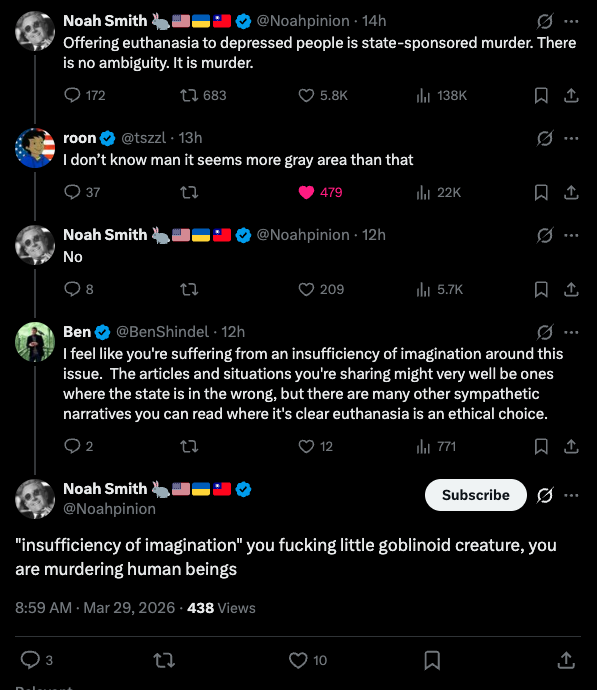
@NeverSayClever @BenShindel @SkyeSharkie You are not eligible for MAID in canada if you have only psychological conditions, it *requires by law* a physical condition.
English
Jan
771 posts
@AnInsanityCheck
CS-PhD. Inquiring non-expert. The world is too complicated to be certain.


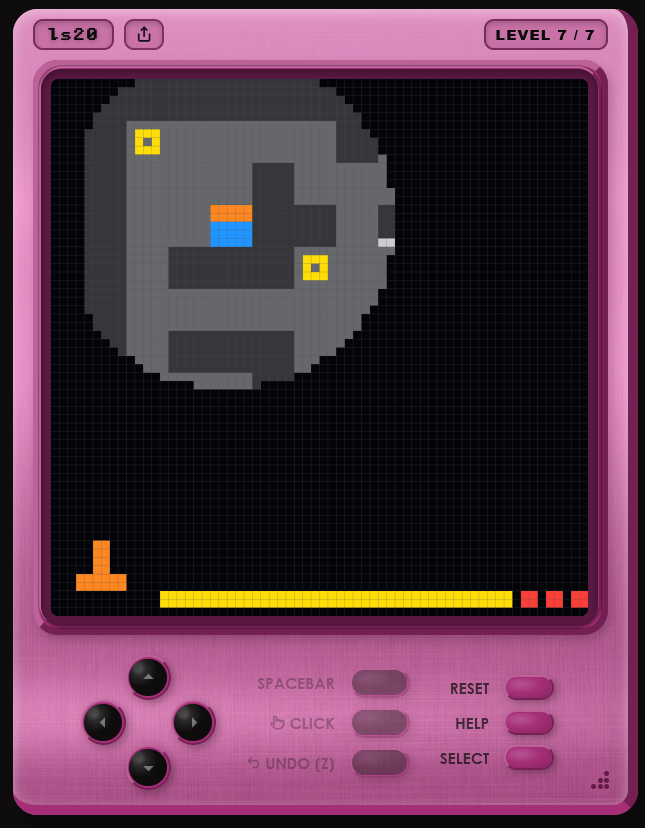

@fchollet according to your paper: "Participants were limited to a single attempt per environment and could not revisit previously completed levels. However, they were allowed to reset the current level at any time. In some cases, participants reset levels after reaching a solution in order to improve efficiency, though this typically increased total interaction time." So humans could play around with the task a bunch, and then just reset the game when they figured it out to get the optimal trajectory? Is AI allowed to do this?

Announcing ARC-AGI-3 The only unsaturated agentic intelligence benchmark in the world Humans score 100%, AI <1% This human-AI gap demonstrates we do not yet have AGI Most benchmarks test what models already know, ARC-AGI-3 tests how they learn

The masculine urge to try to hack a new solution to ARC-AGI benchmarks

Current state of Western Europe

X Product request: a toggle to turn off all AI generated content. Thank you for your attention to this matter!

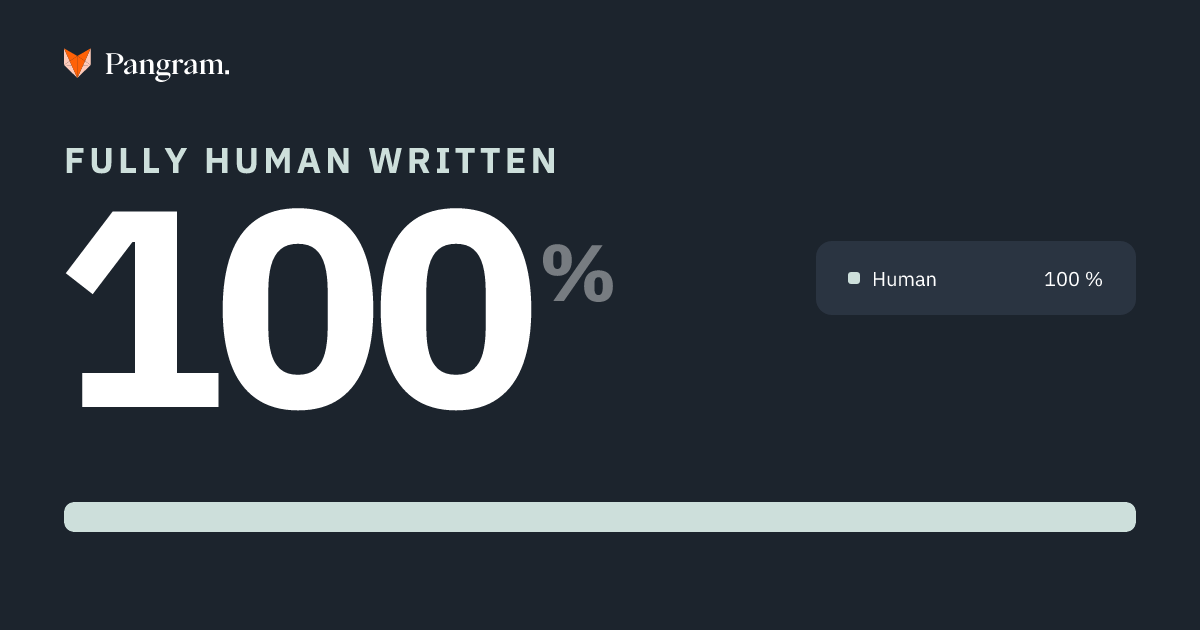
@tenobrus @iruletheworldmo We are confident that this document is primarily human-written, with some AI-generated content detected pangram.com/history/4cecf1…




BREAKING: The ICE agent who fatally shot Renee Good on Jan. 7 in Minneapolis, Jonathan Ross, suffered internal bleeding to the torso following the incident, according to two U.S. officials briefed on his medical condition.

you have access to your optimal policy at all times. you just choose not to follow it. you can literally access it by asking “what should i be doing rn?”

There's definitely a non-zero chance we get "generate your own GTA6 in a few minutes" before GTA6

One of my favorite findings: Positional embeddings are just training wheels. They help convergence but hurt long-context generalization. We found that if you simply delete them after pretraining and recalibrate for < 1% of the original budget, you unlock massive context windows.





The modern left has firmly established themselves as the ideology of violence and terrorism. They don't believe in conversation, reason, or civility; and unfortunately, I don't think they can be dealt with such.


reasonably confident this is a yale demog prof publicly getting a fairly common quant demo problem wrong very publicly i could be wrong, but the probability nerds in the comments and the people like me doing simulations all seem to agree that it's 50/50

Interesting problem. It looks obvious until you actually think about it. Many people gave the wrong answers because they assumed: E[G/(G+B)] = E[G] / (E[G] + E[B]), which is not true. Ratios are sneaky. The denominator moves, and suddenly all our nice intuition falls apart. The quick intuition: once family sizes vary, each family contributes differently to the population ratio, so you can’t just take expectations on the top and bottom and call it a day. And if you try to “just simulate it,” the result depends on how many families you draw. With small N you might get something that looks close to 0.5, but it’s always a bit above 0.5. Simulation will happily mislead you if you let it. If I ever teach PhD formal demography, I’m definitely putting this in the problem set. It’s too good not to. 😄