
exp_loss
545 posts

@boneGPT 1) 5.4 is strong
2) codex is the best ai product
3) 5.3 chat is best chat model on latency / value / reasoning / cost mix
English

where can I bet that spud will be unpopular? they haven't had an impressive launch since o1
JB@JasonBotterill
HAPPY SPUD WEEK
English
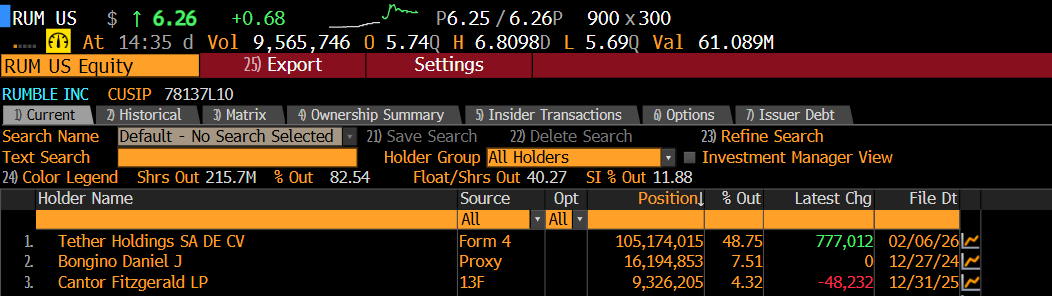

$rum - is someone trying to run this up like $bird?
same data center pivot story and SI
English

Will somebody please buy this so KP has enough money to buy $1 mm of $UAA / $UA stock?
x.com/zerohedge/stat…
zerohedge@zerohedge
Kevin Plank's Unsellable Thoroughbred Race Farm Sees Another Deep Price Cut zerohedge.com/markets/kevin-…
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@karpathy @trainable_nick Do PDFs to ePub handle tabular data in PDFs well? My starting point is PDFs of books with tabular data.
English
@trainable_nick The best epub to txt converter I found is just asking your favorite agent to do it. Epubs can be very diverse, the agent just goes in, figures it out, creates the output markdown and ensures it looks good works great.
English

As I pulled on the thread from Karpathy’s post, I realized the existing EPUB → TXT tools were still too ugly and clunky for turning DRM-free books into clean markdown.
So I made my own.
I’ve only been vibe coding for a few months, and this is my first App Store Connect submission. Feels like a small milestone, but an exciting one.
Grateful for this moment... we get to build better and faster than ever.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@TheLAPurchaser Have fmp on my list to try this weekend. I think its transcript plugin might be helpful since it can give you in txt or json
English

I have not used any of the paid integrations in the exhibit. Octagon, FMP or Finhub. Welcome any thoughts / suggestions.
English
Current Task: SEC filings for Agents. This is pretty easy. Lot of options. Here are the two i used. both free.
Push: sec-filing-watcher. Real-time push.
Pull: edgartools. 2k+ stars on Github.
I think you can pretty easily re-create most of the BAMSEC workflow with this.
Last Task: Sellside research conclusion -- there's no easy way. have to builder a web scraper. will be painful. i'll come back to it later.

TheLAPurchaser@TheLAPurchaser
What is the best way to tap into sellside research for agentic due diligence? I don’t want any more deep research based on seeking alpha and the motley fool. How do I tap into MS, GS, BAML to create a primer, without plugging in via API?
English
@BrandonStraka Bro is stuttering like he personally stole some funds …
English

UN Secretary-General António Guterres warns the organization faces collapse without continued U.S. funding, which contributes roughly $2.2 billion to its core budget.
"the United Nations is on the brink of total collapse" x.com/AmericaRedVoic…
English

exp_loss 已转推

Trump is starting to resemble Yeltsin, but without the ability to blame the vodka
English
@CapitalFang last few days price action been brutal (along with rest of consumer names). term loan also moved down 5 pts.
English

$PLAY - same logic applies (and I still hate it) but stock is now sub $12 after getting booted from S&P SmallCap 600. Will be a very interesting print next week given massive short interest.
EagleFangCapital@CapitalFang
$PLAY - stock is $16. 35m shares. Maintenance CAPEX/Games CAPEX s/b $100M. CFO in a crappy year s/b at least $275M. $7.85/share in maintenance FCF. Instead, full steam ahead on unit growth with negative SSS. I hate this thing, but one sentence on reduced growth and squeeze time.
English

@Talkot Why has cdx gapped out more than cash spreads? Cc @kieranwgoodwin
English

exp_loss 已转推


@FiscalDaddy @tangentstyle to CapIQ? Barely use CapIQ anymore but still have sub and they charge you extra for the MCP. or Daloopa?
English


bullish on cows
- started as a side project while working at rocket lab
- solar powered gps collars for cattle, around 600k have been deployed
- use sound and vibration cues to guide cows (e.g., can schedule cows to show up at the dairy shed at 4:30am)
- proprietary algorithm is called the "cowgorithm"
Bloomberg@business
Peter Thiel’s Founders Fund is backing a company bringing AI to cow herding at a $2 billion valuation bloomberg.com/news/articles/…
English
exp_loss 已转推

@Jaro_rogue wait does CapIQ enterprise terms actually allow commercialization of their data?
English

Someone is a cheap Capital IQ API equivalent away from becoming a multi-millionaire. Everyone will be able to make their own dashboards in a day. Only thing that keeps koyfin and tikr in business is their access to enterprise Capital IQ where they can spread cost across users.
English


Now I am curious: which well-known people (currently alive) you think are close to 0.
Nassim Nicholas Taleb@nntaleb
On a bullshit scale of 0-10, where 0 is maximally rigorous and 10 is maximally bullshitter, Sam Harris stands close to 10.
English

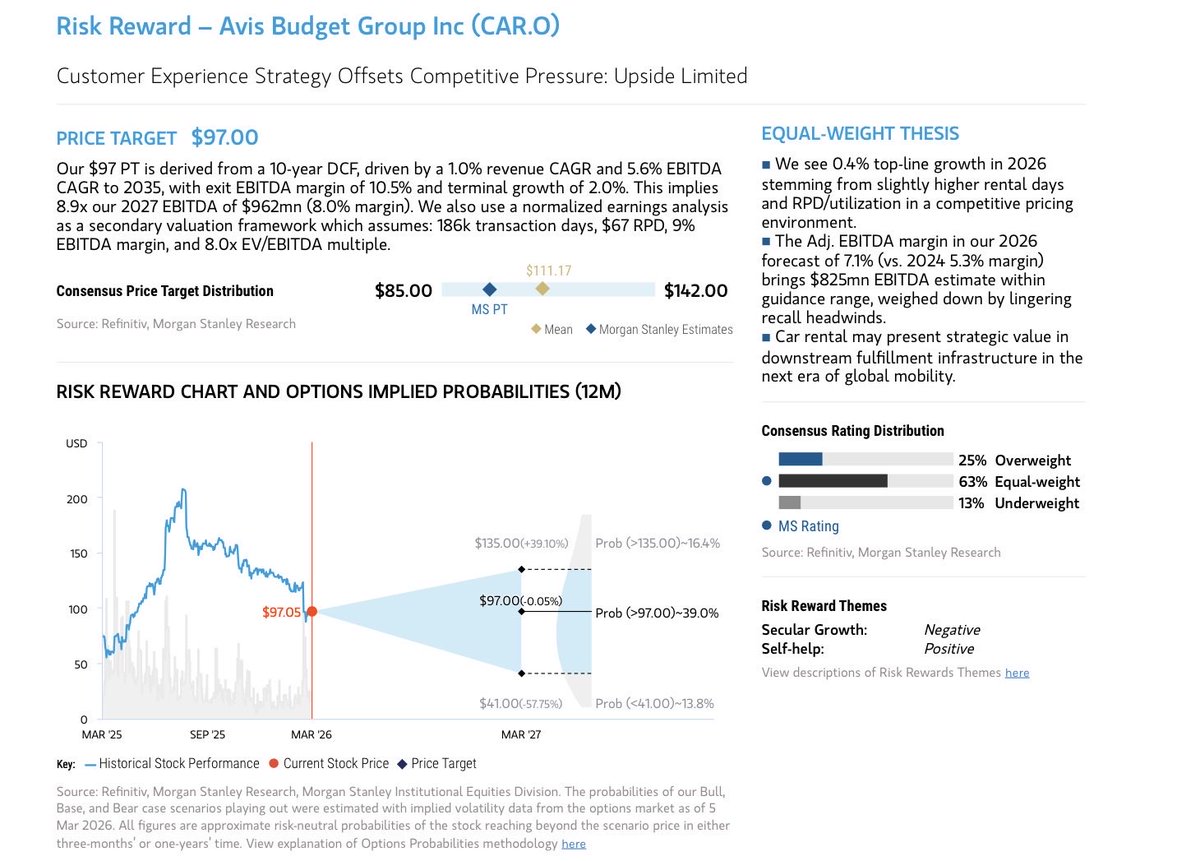
Can someone explain $CAR (Avis Budget) to me? Ultra competitive, commoditised business. Underperforming, poor guide. 7x corp leverage. These things used to be 6x EBITDA pre-pandemic, why does it trade at 10x ‘26 EBITDA?
English
@__paleologo @sagorika_s You are just getting caught by the Wendy Doniger haters… feel free to ignore and progress. The BJP trolls are just onto your post
English

@sagorika_s Does Carole Satyamurti hate India? Or passages in this book show an anti-Indian attitude? Genuinely curious.
English

If wanting to learn about the Roman Empire, I’ve never seen people choose a book by those who hated the empire. And yet when it comes to India, books are popular only if someone who hates the civilisation writes about it.
Just goes to show that knowledge has never been the point; it is about an insular people wish to learn the framing that allows them to feel superior in their little bubbles.
Gappy (Giuseppe Paleologo)@__paleologo
Just got this and I am reading. It’s excellent. The 10 books of the integral edition are too much for me. $16. Still, 900pp. If you don’t want to read it, the “Mahabarata” by Peter Brook (a movie) is free on the Internet Archive. Great. Still, 5hrs of a movie. Ok: read the Bhagavad-Gita. Be Oppenheimer a bit… In sum: get some Mahabarata. Top Ten in universal literature ever, everywhere. Dramatically underrated by non-Indians.
English