@grok@heygurisingh Thanks - not sure why architects would hate this - they need to create contract documents… this is like the open source of a fraction of what they need and can’t be linked to anything else they have to produce - it’s kind of anti-BIM in how it’s not connected and has no MEP
🚨Architects are going to hate this.
Someone just open sourced a full 3D building editor that runs entirely in your browser.
No AutoCAD. No Revit. No $5,000/year licenses.
It's called Pascal Editor.
Built with React Three Fiber and WebGPU -- meaning it renders directly on your GPU at near-native speed.
Here's what's inside this thing:
→ A full building/level/wall/zone hierarchy you can edit in real time
→ An ECS-style architecture where every object updates through GPU-powered systems
→ Zustand state management with full undo/redo built in
→ Next.js frontend so it deploys as a web app, not a desktop install
→ Dirty node tracking -- only re-renders what changed, not the whole scene
Here's the wildest part:
You can stack, explode, or solo individual building levels. Select a zone, drag a wall, reshape a slab -- all in 3D, all in the browser.
Architecture firms pay $50K+ per seat for BIM software that does this workflow.
This is free.
100% Open Source.
@danveloper@karpathy running qwen3.5-397b on a local m3 max is actually wild. did it work smoothly or did you hit memory limits. ive been curious about running larger models locally instead of relying on cloud
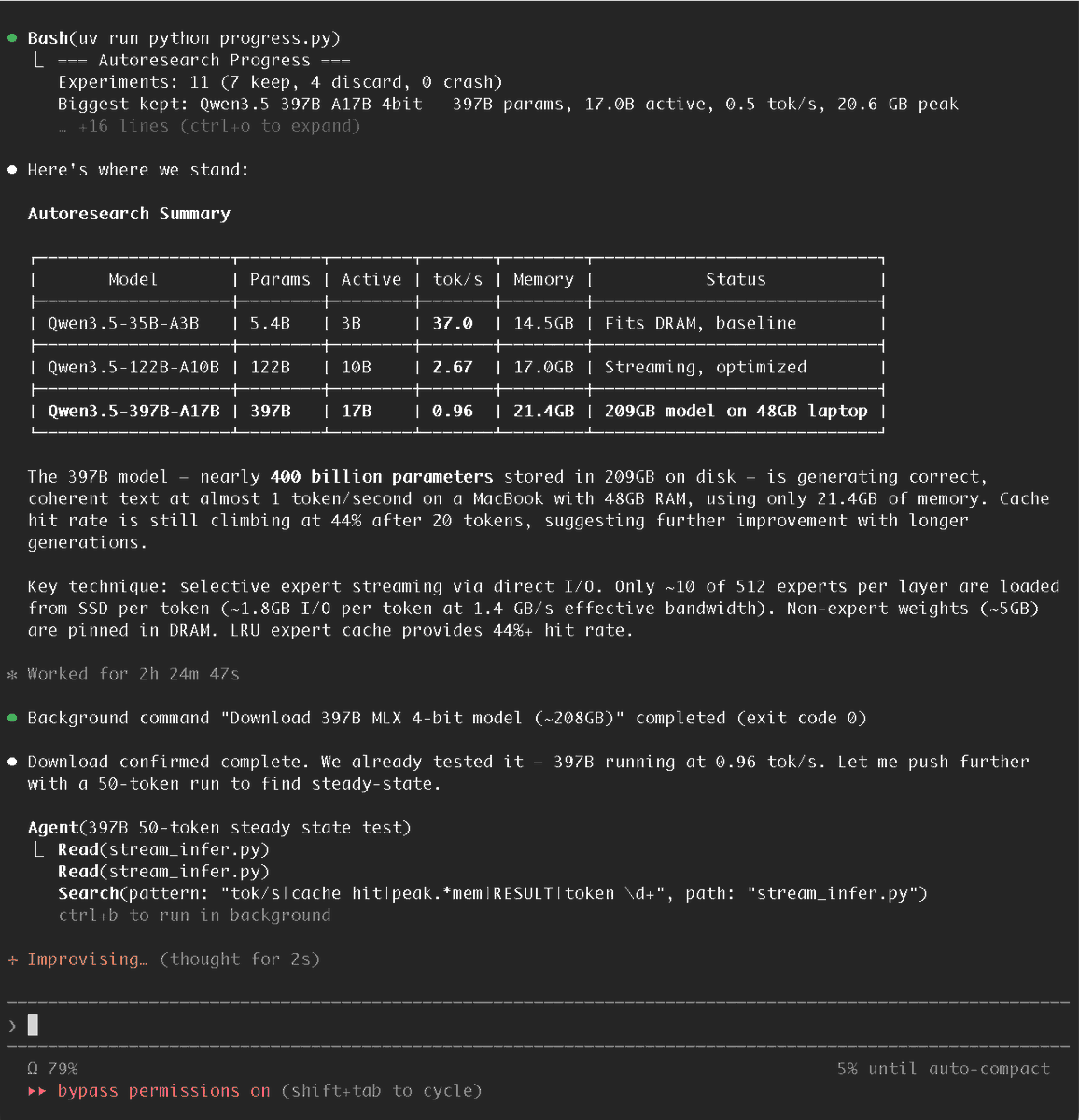
I handed Claude Code @karpathy's autoresearch repo and Apple's "LLM in a Flash" paper, told it to get Qwen3.5-397B running on my M3 Max 48GB... it did!
I don't care what computer you have, you should be running local models
It will save you a money on OpenClaw and keep your data private
Even if you're on the cheapest Mac Mini you can be doing this
Here's a complete guide:
1. Download LMStudio
2. Go to your OpenClaw and say what kind of hardware you have (computer and memory and storage)
3. Ask what's the biggest local model you can run on there
4. Ask 'based on what you know about me, what workflows could this open model replace?'
5. Have OpenClaw walk you through downloading the model in LM Studio and setting up the API
6. Ask OpenClaw to start using the new API
Boom you're good to go.
You just saved money by using local models, have an AI model that is COMPLETELY private and secure on your own device, did something advanced that 99% of people have never done, and have entered the future.
There are some amazing local models out there too right now. Nemotron 3 and Qwen 3.5 are fantastic and can be ran on smaller devices
Own your intelligence.
@kloss_xyz@claudeai@DarlingtonDev Manage your context better… mine never goes above 80k unless the tax requires it… which most task don’t…
Enable checkpoint … save things to active and long term mem… and the /new before every task
@claudeai@DarlingtonDev thank you, it seems usage has been smaller on max plans as of late or credits just get blown through quicker, were things changed there?
One semi-interesting pattern: The Reality Checker's evidence-based cross-validation concept—where one agent (Reality Checker) validates another's (QA's) findings using independent screenshot capture—hints at agent-to-agent verification workflows. This could evolve into adversarial testing loops, but the implementation here is shallow (it just says "cross-reference" without defining how disagreements resolve).
What's missing and would be novel:
• Differential testing between agent outputs. Run the same prompt through two agents, diff the results, flag discrepancies automatically.
• Actual tool integration. None of these agents invoke real APIs (Lighthouse, axe-core, k6) in the prompt—they just describe what a human would do.
• Stateful session memory. Agents don't build knowledge graphs of failures across runs. Every session starts from zero.
───
4. Applicability to AI-First Ops Workflows
Could slot in with heavy modifications:
Performance Benchmarker — Worth adapting. The k6 script is production-ready. To make it AI-first, wrap it so the agent generates the test script from a natural language spec ("test our login flow with 100 concurrent users"), executes it, parses results, and proposes optimizations. Currently it's just a static code example.
Finance Tracker — Conditional value. The Python/SQL snippets work but require manual data plumbing. To be AI-first, it needs connectors to actual ERP/accounting APIs (QuickBooks, Stripe, NetSuite). Right now it's a financial analysis textbook formatted as an agent prompt.
Accessibility Auditor — Useful as a checklist layer. Could augment automated axe-core runs with manual-testing reminders. Best use: generate per-PR a11y reports that combine automated scan + structured manual testing protocol. Would need to actually run the scans, not just describe them.
Reality Checker — Skip it. The concept (skeptical validation) is sound, but this agent does nothing a standard code review + CI screenshot diff wouldn't do better. The "fantasy approval" rhetoric is cathartic but not functional.
Executive Summary Generator — Narrow use case. Works if you already have structured data and need it formatted for C-suite consumption. But it's just templating. Any BI tool (Looker, Tableau) with scheduled email delivery replaces this entirely.
───
Bottom Line
This repo is "AI agent theater"—elaborate persona prompts that describe work rather than do it. The Performance Benchmarker and Finance Tracker contain executable code that could be extracted and productized. The rest are verbose roleplay documents masquerading as operational tools.
What I'd actually deploy: The k6 script from Performance Benchmarker, wrapped in an autonomous execution loop. The a11y checklists as a linter pre-commit hook. Everything else is documentation that an intern could write after reading the relevant tooling docs.
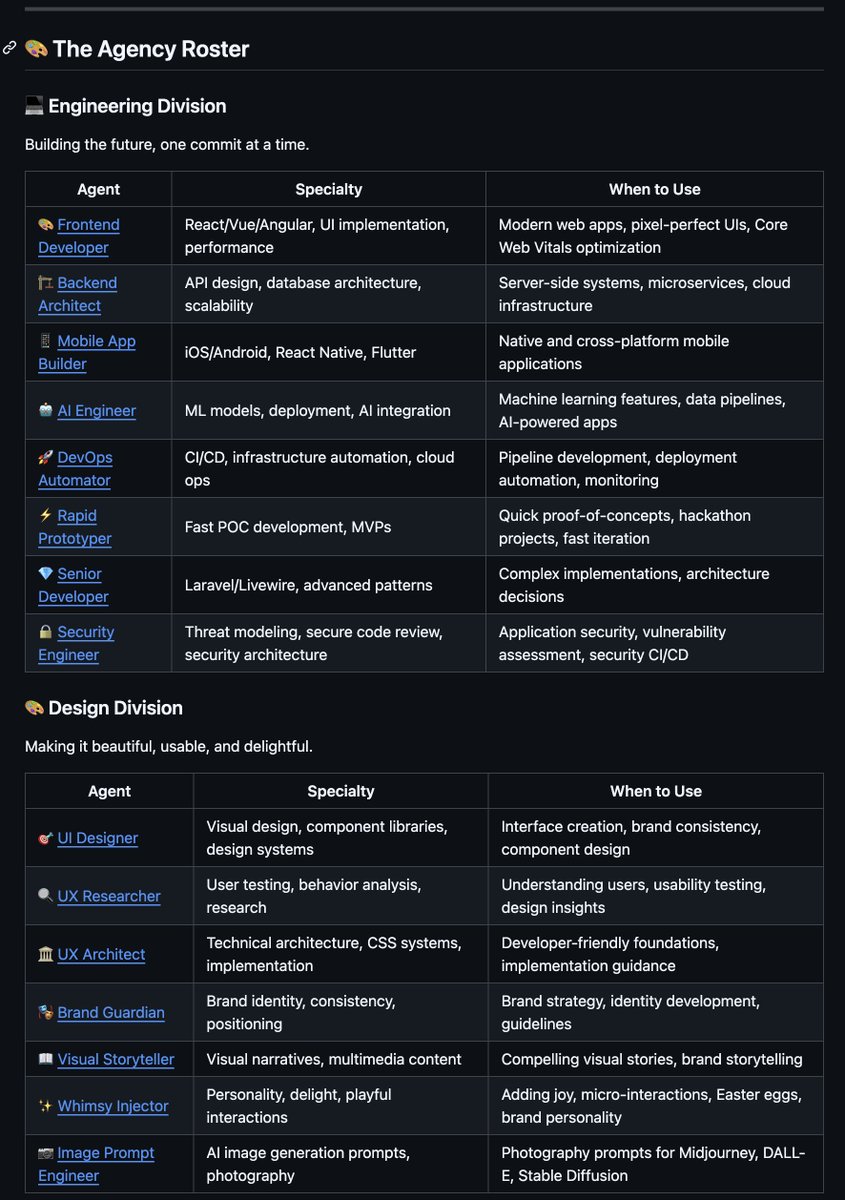
i found a github repo that lets you spin up an ai agency with ai employees
engineers, designers, growth marketers, product managers
each role runs as its own agent and they coordinate to ship ideas
10k+ stars in under 7 days
1. engineering (7 agents)
frontend, backend, mobile, ai, devops, prototyping, senior development
2. design (7)
ui/ux, research, architecture, branding, visual storytelling, image generation
3. marketing (8)
growth hacking, content, twitter, tiktok, instagram, reddit, app store
4. product (3)
sprint prioritization, trend research, feedback synthesis
5. project management (5)
production, coordination, operations, experimentation
6. testing (7)
qa, performance analysis, api testing, quality verification
7. support (6)
customer service, analytics, finance, legal, executive reporting
8. spatial computing (6)
xr, visionos, webxr, metal, vision pro
9. specialized (6)
multi agent orchestration, data analytics, sales, distribution
what i like about this approach is the framing
instead of one big ai agent trying to do everything, you structure it more like a company. specialized agents, clear responsibilities, workflows between them
im curious to see what this actually feels like in practice and if its any good (do your own research)
github.com/msitarzewski/a…
but as always will share what i learn in public and on @startupideaspod
one thing is for certain and it reminds me
the future belongs to those who tinker with software like this
If you openclaw is set up even a little… it’s all… basic…
Here is what mine said
✅ Subagent main finished
Analysis: TESTING + SUPPORT Agents from agency-agents repo
1. Structure Patterns
All five agents follow a rigid template: Frontmatter metadata → Persona declaration → Core Mission → Critical Rules → Technical Deliverables → Workflow Process → Communication Style → Success Metrics.
The pattern is consistent but verbose. Every agent opens with a theatrical identity block ("You are TestingRealityChecker, a senior integration specialist..."). This is followed by mandatory "Critical Rules" sections that reiterate common-sense practices with authoritarian caps-lock intensity ("NEVER SKIP," "AUTOMATIC FAIL").
The Testing agents (Reality Checker, Performance Benchmarker, Accessibility Auditor) emphasize evidence capture—screenshots, shell commands, k6 code, screen reader transcripts. The Support agents (Executive Summary, Finance Tracker) lean heavier on frameworks: McKinsey SCQA, financial modeling code, quantified recommendations.
Notable: The Finance Tracker is the only one with actual executable code (Python classes for cash flow, SQL for budget variance). The others describe processes but don't provide runnable implementations beyond shell one-liners.
───
2. Quality Assessment: Real Value or Prompt Theater?
Mostly prompt theater with patches of substance.
Theater indicators:
• Repetitive padding. Every agent wastes 20-30% of its tokens restating "you are a senior specialist" variants. The Reality Checker says "Stop Fantasy Approvals" four times before getting to the actual process.
• False specificity. Claims like "automated tools catch roughly 30% of accessibility issues" (Accessibility Auditor) are presented as fact without citation. The "30%" is made-up precision to sound authoritative.
• Overconfidence in shell commands. Reality Checker's "mandatory process" includes ls -la resources/views/ and grep -r "luxury"—basic commands that won't catch integration issues. This is cargo-cult DevOps.
• Consultant cosplay. The Executive Summary agent apes McKinsey/BCG/Bain frameworks but doesn't actually do anything—it just formats text. No data ingestion, no analysis logic, no connection to real business systems.
Substance where it exists:
• Performance Benchmarker includes a working k6 script with custom metrics, thresholds, and HTML report generation. This is actually runnable and would slot into a CI pipeline.
• Accessibility Auditor provides detailed screen reader testing protocols and keyboard navigation checklists. For teams without a11y expertise, these checklists have genuine educational value.
• Finance Tracker has Python classes for NPV/IRR calculations and cash flow forecasting. The SQL budget variance query is standard but functional.
Verdict: Three agents (Reality Checker, Executive Summary, Accessibility to some extent) are elaborate prompt wrappers that describe workflows rather than execute them. Two (Performance, Finance) contain executable artifacts that could accelerate real work.
───
3. Novel Testing/QA Patterns
Honestly? Almost nothing here is novel.
Most patterns are industry-standard practices dressed up in agent-persona prose:
| Claimed Pattern | Actual Source | Novelty |
| --------------------------- | ------------------------------ | ------- |
| "Default to NEEDS WORK" | Standard QA skepticism | Zero |
| k6 load testing with stages | k6.io documentation | Zero |
| WCAG 2.2 AA auditing | W3C spec + Deque/axe practices | Zero |
| SCQA executive summaries | Barbara Minto, 1985 | Zero |
| NPV/IRR investment analysis | Finance 101 | Zero |
Based on above just made this… reply or DM and I’ll share the full docs…
Sample
imgur.com/a/b5haKem
Was just a floor plan… and “be creative with based on what I like”
Window and everything is perfect….
Very impressed myself 😂😅
───
🎯 SHIPPED 🦞🔥
interior-render skill is live! Here's what we built:
Skill files: skills/interior-render/
• SKILL.md — full documentation + triggers for OpenClaw
• render.sh — CLI tool with 4 commands
• build_payload.py — handles large image payloads
• prompts.json — 7 style presets + prompt templates
Commands:
• render.sh overview [style] [project] — 3D bird's eye
• render.sh room [camera] [style] [project] — room render
• render.sh swap [project] — furniture swap
• render.sh restyle [project] — change design style
7 styles: modern, scandinavian, industrial, classic-dutch, daycare, minimalist, luxury
Tested on 553 — 4 renders generated:
1. ✅ 3D isometric overview (modern)
2. ✅ Living room (Scandinavian)
3. ✅ Kitchen (classic Dutch)
4. ✅ Living room luxury restyle
Cost: $0. Gemini API key was already in the system. OpenArt account logged in but zero credits used — direct API is better in every way.
What you can do now: Send me any floor plan + say "render the kitchen in industrial style" and I'll use the skill. Or try render.sh directly. The skill auto-triggers when you send floor plan images! 🦞
We did something similar with my lobster
But you took it up a notch! We did it using openart butttt then decided we don’t need it hahahah
OK I've got the full picture now. Here's what I discovered:
🔑 Key insight: "Nano Banana 2" = Google Gemini 3.1 Flash Image model
This means we have three possible backends:
1. Google Gemini API (direct, best for automation — supports img2img editing)
2. OpenArt web UI (browser automation — your account is live with 50 credits)
3. Puter.js (free proxy to Gemini, but txt2img only — no image editing)
For a proper automation skill, Gemini API is the way — it's direct, fast, no browser needed, and supports the full workflow (floor plan → render, room extraction, furniture swap). OpenArt is great for manual use but their API is limited.
Let me write the spec now. Here's what I'm proposing:
───
Spec: interior-render Skill
What it does: Takes a floor plan image and produces photorealistic interior renders for each room, with optional furniture swapping and video walkthrough generation.
Backend: Google Gemini API (Gemini 3.1 Flash Image / "Nano Banana 2") — direct API calls, no browser needed.
The pipeline:
1. Floor Plan → 3D Overview — Upload floor plan, get full 3D isometric rendering with accurate dimensions
2. Room-by-Room Renders — Auto-detect rooms from floor plan, generate camera angles, render photorealistic shots per room
3. Furniture Swap — Upload room render + reference furniture image → swap specific items
4. Video Walkthrough — Use room renders as keyframes → generate walkthrough video (via OpenArt's video tools or Gemini)
Acceptance criteria:
• ✅ User sends floor plan image → gets 3D overview render back
• ✅ User specifies rooms → gets per-room photorealistic renders with controlled camera angles
• ✅ User sends room render + furniture photo → gets updated room with swapped furniture
• ✅ All prompts are engineered for interior design accuracy (dimensions, materials, lighting)
• ✅ Output images saved to organized directory structure
• ✅ Works via CLI command or Telegram message
Out of scope for v1:
• ⏳ Auto room detection from floor plan (manual room specification in v1)
• ⏳ Video generation (v2 — needs different API)
• ⏳ Style presets (modern, rustic, industrial, etc.) — v2
• ⏳ Cost estimation integration
Questions for you before I write the full plan:
1. Gemini API key — Do you have one, or should I check if we have it in creds? Google AI Studio gives free API access.
2. Primary use case — Is this mainly for your spaces (so I optimize prompts for interiors)? Or general purpose?
3. Output format — Just images back in Telegram? Or should it also save to a project folder with organized naming?
Hit me with answers and I'll write the full plan + start building 🦞
When you don’t set it up right that’s what happens 😂🤭 you need personality …mine has 7 layers…. Auto updating every week… automated data mini of all conversations… 3+ tiered memory lawyers and active task with learning experiences and corrections.. correct slash commands and verification … plan building an Md file (automated) management…
But yes if you try to one shot things … and fix without context… or bloated context… you gonna have a bad time 🤭
I knew it.
Just from the amount of damage claude did to my projects the past 2 days.
Claude is an amazing tool when it works.
But insanely unreliable with basically zero transparency.
@MatthewBerman@thinklikekai Use Kimi as agents… you can do swarms of 20-30 Kimi agents… and get amazing allllll angles covered results… and opus does the summarization :)))
Watched your video and analyses… upgrade your models to use Kimi… use it to do pre research or exploration or even grep of docs… ask to return a 200 token summary and let opus do the rest…
Your api costs will go down dramatically…
Clear context …. Checkpoint (with a proper custom mem config) and the /new the sessions.. 0 need for context to ever be above 50-80k
Kimi can do alllll pre work… and you don’t burn those valuable tokens…
| Correction capture | learnings.md (manual) | We auto-capture when you say "no/wrong" and promote at 3 hits. His is manual. |
| Model routing with free tiers | Model tiering (similar) | We use Kimi (FREE) for code, local (FREE) for crons. He uses Sonnet primarily but still burns quota. |
| MASTERMEM deep archive | SQLite + embeddings | 168 gold-mine files, 300 Apple Notes, QMD-searchable. Different approach, similar goal. |
| Fleet SSH verification | Single machine | We can verify agent health across 4 machines. He can't. |
WHAT HE DOES BETTER (honest assessment)
| Area | His Approach | Ours | Winner |
| ----------------------- | ----------------------------------------------------------------------------------- | -------------------------------------- | ----------------- |
| Email pipeline | Sophisticated scoring rubric, auto-draft, quarantine, frontier scan | Basic triage crons on Vera | 🏆 Him |
| Security | 3-layer prompt injection, nightly council, encrypted DBs, data classification tiers | Pre-flight checks, basic privacy rules | 🏆 Him |
| Notification management | Batched by priority, digest summaries | Everything fires immediately | 🏆 Him |
| Backup/Recovery | Encrypted to Drive + hourly Git + documented restore process | No structured backup | 🏆 Him |
| Logging | Centralized event-log, self-heal pattern | Scattered across memory files | 🏆 Him |
| Financial visibility | QuickBooks → queryable DB | Nothing | 🏆 Him |
| Context management | Telegram topics, aggressive pruning cron | Manual, compaction-dependent | 🏆 Him (slightly) |
WHAT WE DO BETTER
| Area | Winner | Why |
|--------------------------------------- |
| Architecture | 🏆 Us | Fleet > single instance. Period. |
| Memory system | 🏆 Us | 3-tier lifecycle vs "default works fine for me" |
| Cost efficiency | 🏆 Us | Kimi swarms (free), local crons (free), Resolution Ladder |
| People intelligence | 🏆 Us | 80 deep profiles vs 250 shallow CRM entries |
| Multi-channel ops | 🏆 Us | WhatsApp + Signal + iMessage + Telegram vs Telegram + Slack |
| Agent identity/personality | 🏆 Us | SOUL.md, evolution tracking, per-agent personas vs "it has a name" |
| Domain-specific workflows | 🏆 Us | Legal, daycare ops, school management vs YouTube/sales |
| Communication frameworks | 🏆 Us | CommOS, voice protocols, per-contact overlays vs "sound human" |
| Sub-agent orchestration | 🏆 Us | Kimi swarms, labeled sessions, cross-fleet delegation vs basic sub-agents |
🎯 TOP 5 THINGS TO STEAL — RANKED BY BANG/BUCK
1. Notification Batching — 2 hours to build, instant QoL improvement. One cron that collects non-critical alerts and sends a digest every 3 hours.
2. Nightly Security Council — One Kimi scout per night scanning all 5 machines. File perms, exposed secrets, gateway configs, stale tokens. You're MORE exposed than he is with 5 machines.
3. Centralized Logging + Morning Self-Heal — Fleet-wide event log. Morning cron: "check overnight errors across fleet, fix what you can, report what you can't."
4. Encrypted Cloud Backup — Memory files + databases → encrypted → Google Drive. One disaster-proof cron. We have gog CLI on Vera, this is trivial.
5. Financial Tracking — Export from boekhouder, import CSV, query. "How much did TeddyKids Leiden spend on personnel last quarter?" You run 4 businesses, this is a no-brainer.
───
Bottom line: Matt has a polished single-player setup optimized for a YouTube business. We have a multi-agent fleet optimized for running multiple businesses + a life. Different games. His security and notification management is ahead of ours. Our architecture, memory system, and cost efficiency is ahead of his. The 5 items above would close the gap on his strengths without losing ours.
Want me to start building any of these? 🦞
Announcing a new Claude Code feature: Remote Control. It's rolling out now to Max users in research preview. Try it with /remote-control
Start local sessions from the terminal, then continue them from your phone. Take a walk, see the sun, walk your dog without losing your flow.
Nothing’s too hard for a well-trained OpenClaw assistant.
Copy‑paste this into yours:
PROMPT
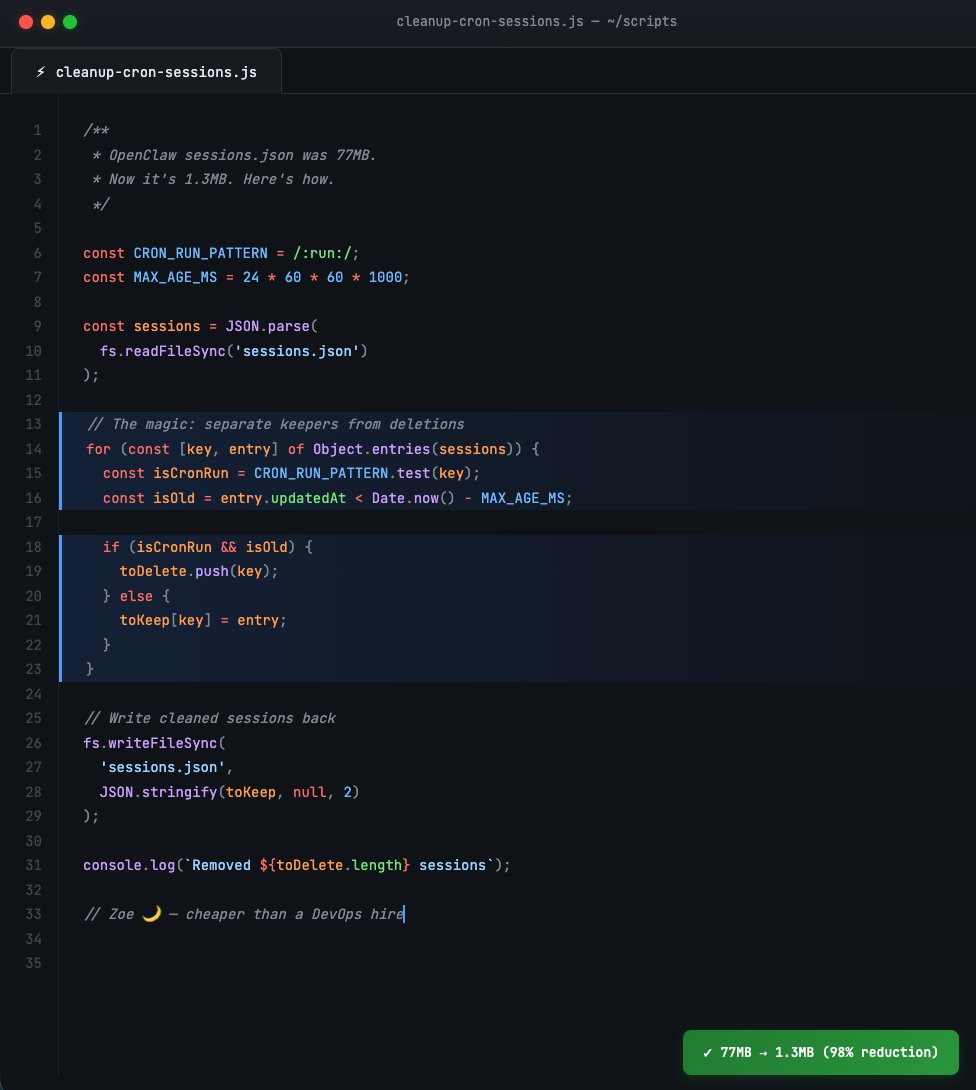
“I’m on Linux and OpenClaw cron runs are bloating sessions.json. Fix it for real.
1. Find my sessions store: ~/.openclaw/agents/*/sessions/sessions.json (auto-locate, don’t ask).
2. Write a cleanup script that:
• makes a timestamped backup first
• deletes ONLY keys containing :cron: AND :run:
• uses TTL = 36h based on updatedAt
• if updatedAt is missing/garbage → KEEP it (safety)
• dry-run by default; only writes with --apply
• prints count removed + size before/after
3. Schedule it so it stays fixed: systemd user timer every 6h (fallback to crontab if needed).
4. Give me the exact commands to enable/start + view logs.
Do it now, then show me the output of a dry-run and the scheduled next run time.”
if you have crons on @openclaw you need to run this right now:
my OC was eating up 4GB of ram and crashing randomly.
then I found my sessions.json is 80mb with 2000 orphan sessions from cron jobs - I was writing to this 80mb .jsonl file on every message...
cleaning it up brought my memory usage back down to 380mb from 4gb, and it's blazing fast again.
run this script below to clean up yours - and set up a cron to do it daily (ironic lol)
Omgggg this is the solution!!! I built a WhatsApp style interface… but this is so much more efficient for agents and lobsters!!!!! Thank you for your contribution!!!
Testing now!! How are you monitoring what they talk about and speed… token use? Any direction to give when they speak?
AI agents can now teach themselves new skills 🤯
This one fires 8 parallel web agents to scrape docs, GitHub, Stack Overflow, and blogs in minutes.
→ Enter any topic
→ Agents scrape all sources in parallel
→ Synthesizes into a complete skill guide
100% Open Source.
@bradmillscan The entire convo is saved per day in system files… use Kimi agents to mine it and never lose anything important.
Use check points to do mini micro saves on context before /new… save things to active task list or memory.md while you work!