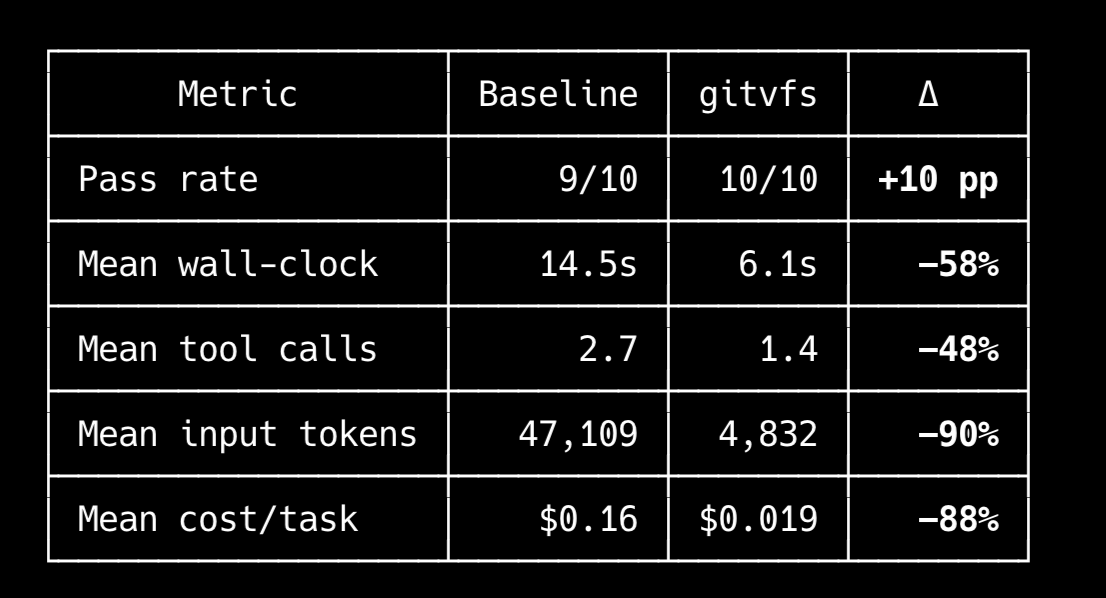
@shi_weiyan that 1.7x matters most on search pages where small filter changes throw it off
English
Suresh
6K posts

@_Suresh2
MSc Software Engineering @ Chongqing University ’26 | Researching AI x Software Engineering (AI for SE & SE for AI) | 🇵🇰➡️🇨🇳

🇧🇷ICLR 2026 paper🇧🇷 Your agent's skills don't transfer. On a new site, only 18% skills get reused — so there's no continual learning, just relearning every time. How do agents learn skills that actually generalize? Introducing PolySkill to make agents smooth across sites 🧵


🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…





The new generation of open state-of-the-art single and multi-vector retrieval models is here It's time, DenseOn with the LateOn 🎶 @LightOnIO releases models that leap past existing ones, and everything you need to do the same!








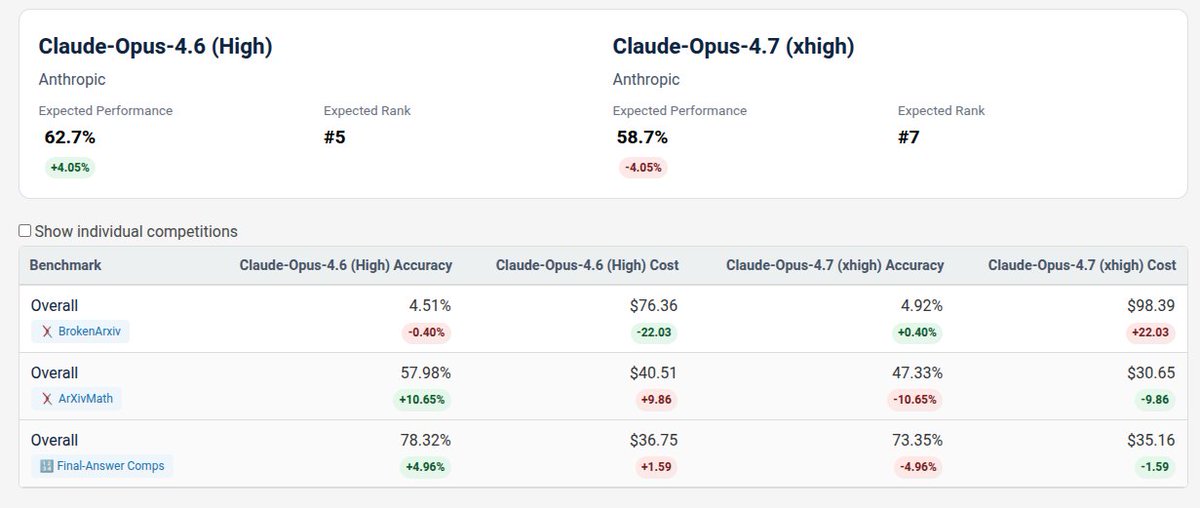




🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…


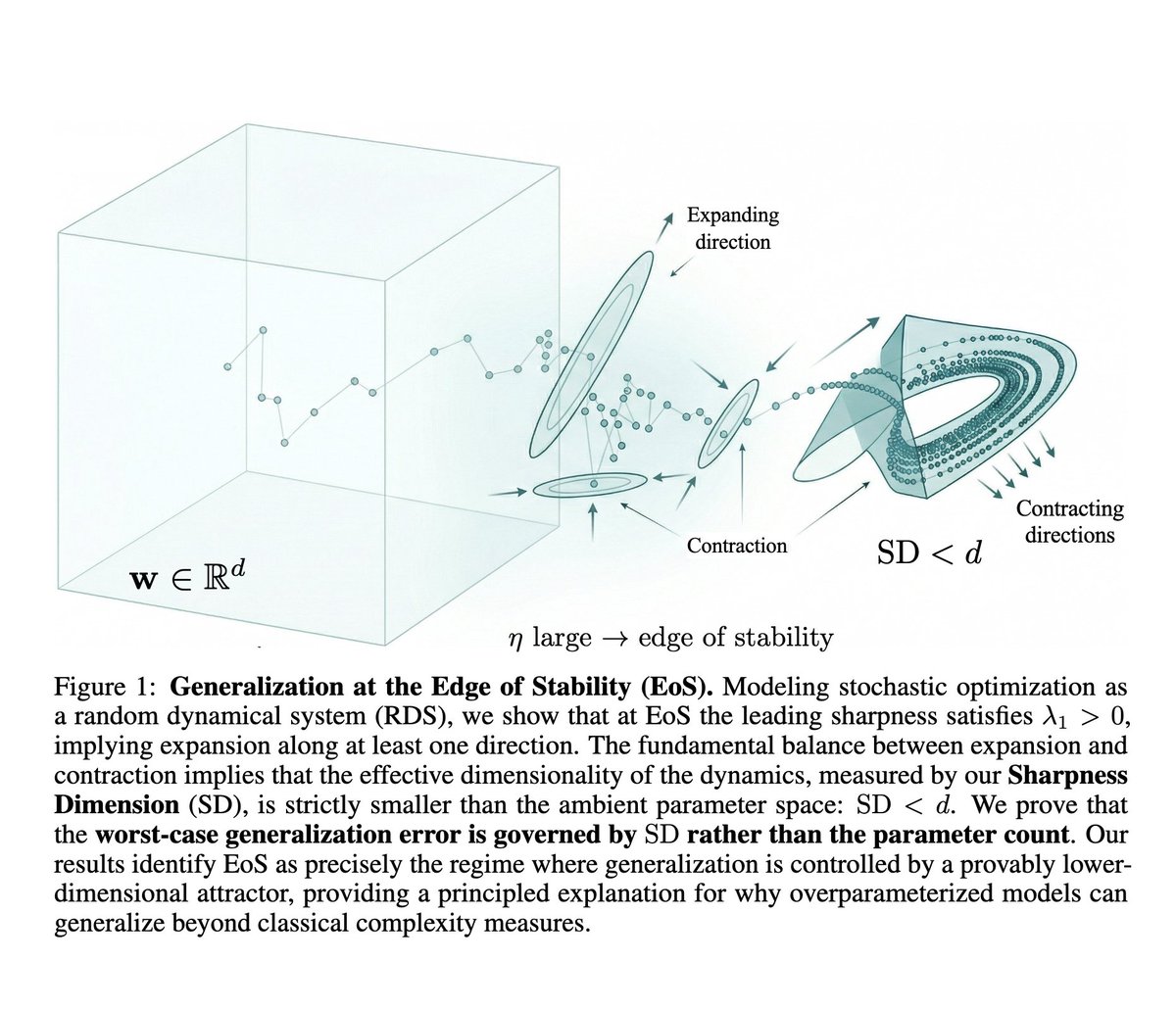

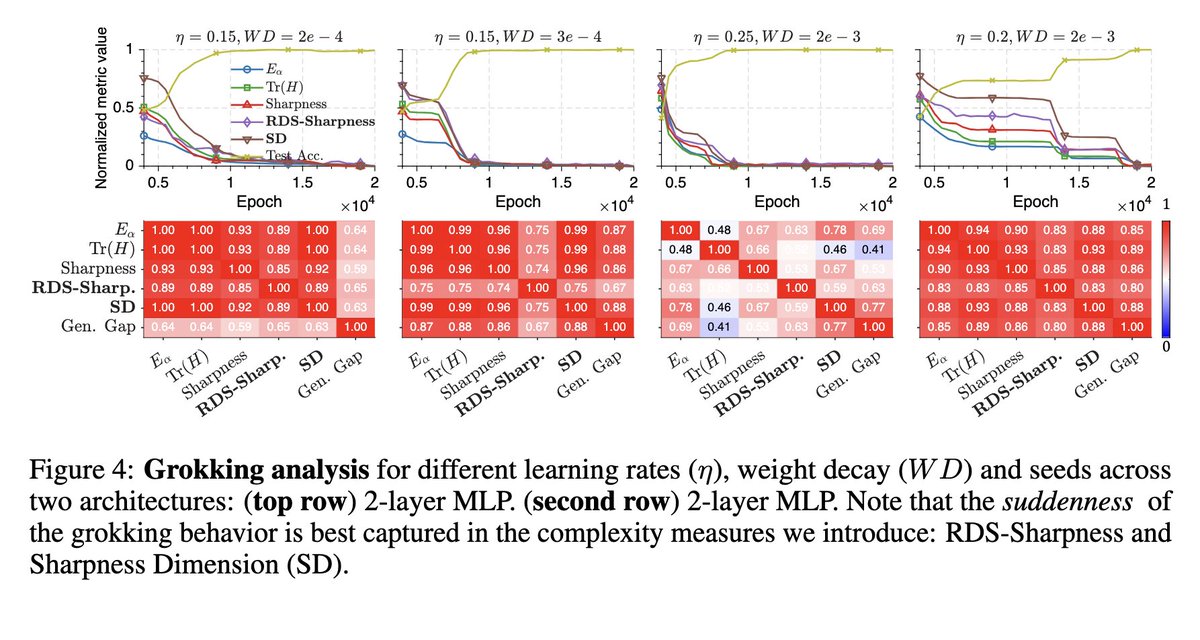

Despite being in the toughest spot (decontamination built from our data), LateOn and DenseOn don't flinch LateOn keeps #1, DenseOn stays top-4, only behind ColBERT-Zero (our other strong multi-vector model) and pplx-embed That shows direct evidence of generalization and not overfitting