
grammarly cloned julia angwin's editing voice without asking and sold it as an ai feature — she's suing under plain old right of publicity law, no new ai regulation needed
nytimes.com/2026/03/13/opi…
English
ejae dev
3.4K posts

@ejae_dev
AI Agents / Agentic Coding / eAcc Contributor to https://t.co/BWeaftUbLL 🦞 YouTube: https://t.co/N6TFEHcl1j ▶️


BREAKING: Meta, $META, is planning sweeping layoffs that could affect 20% or more of the company, per Reuters




BREAKING: Meta, $META, is planning sweeping layoffs that could affect 20% or more of the company, per Reuters




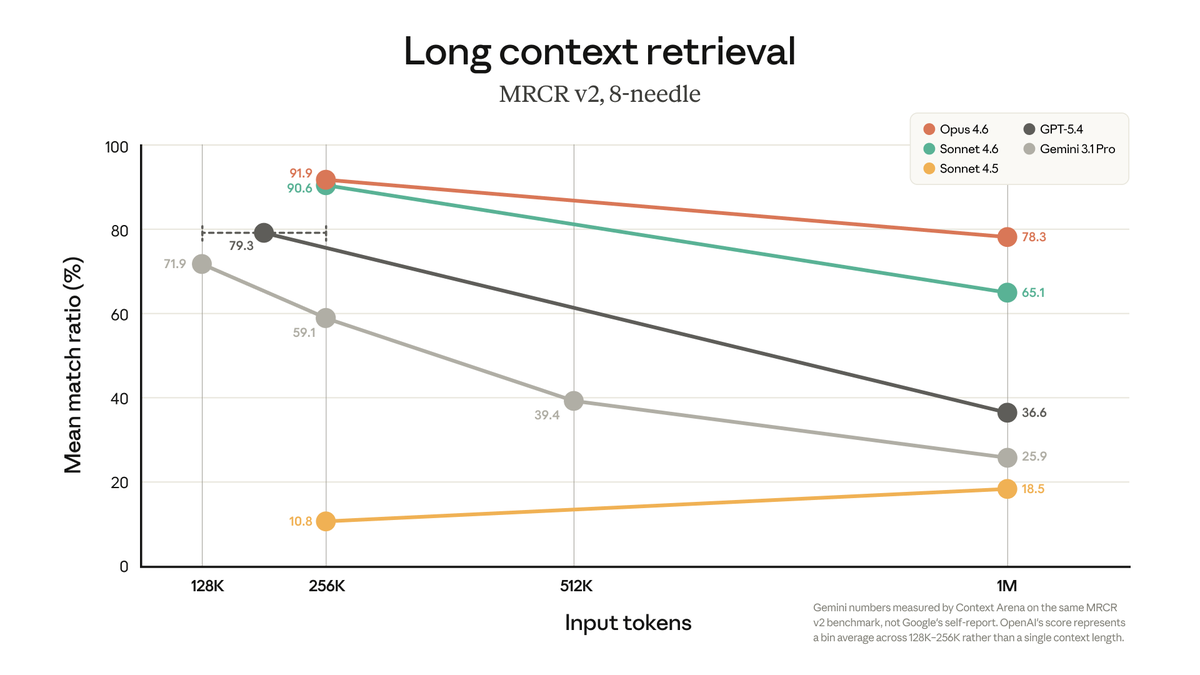
1 million context window: Now generally available for Claude Opus 4.6 and Claude Sonnet 4.6.

Ex-NFLer Darron Lee used ChatGPT for advice after allegedly killing his girlfriend, prosecutors say. Details: tmz.me/GaDHUn8


