Sabitlenmiş Tweet

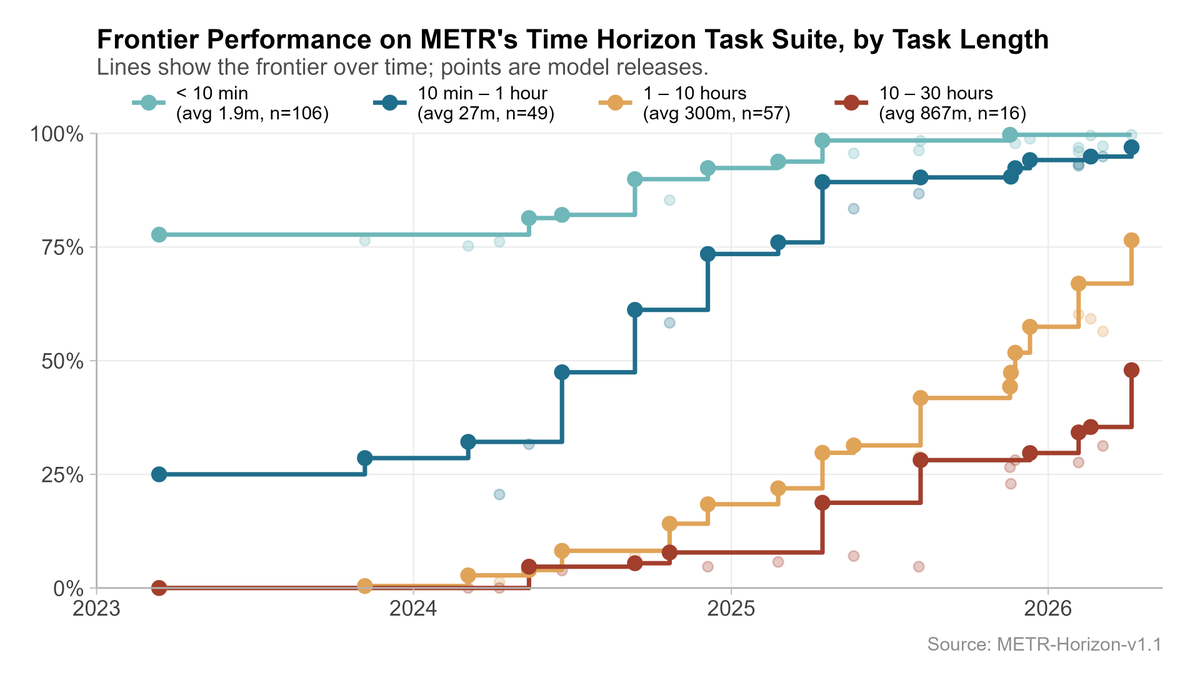
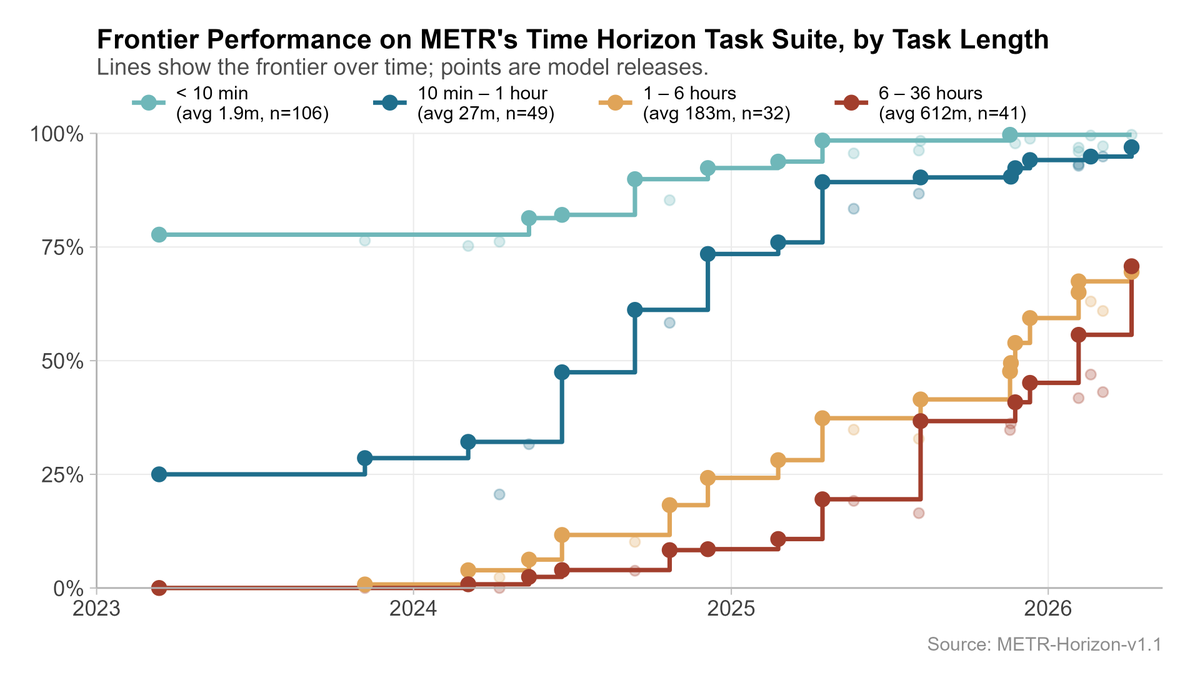
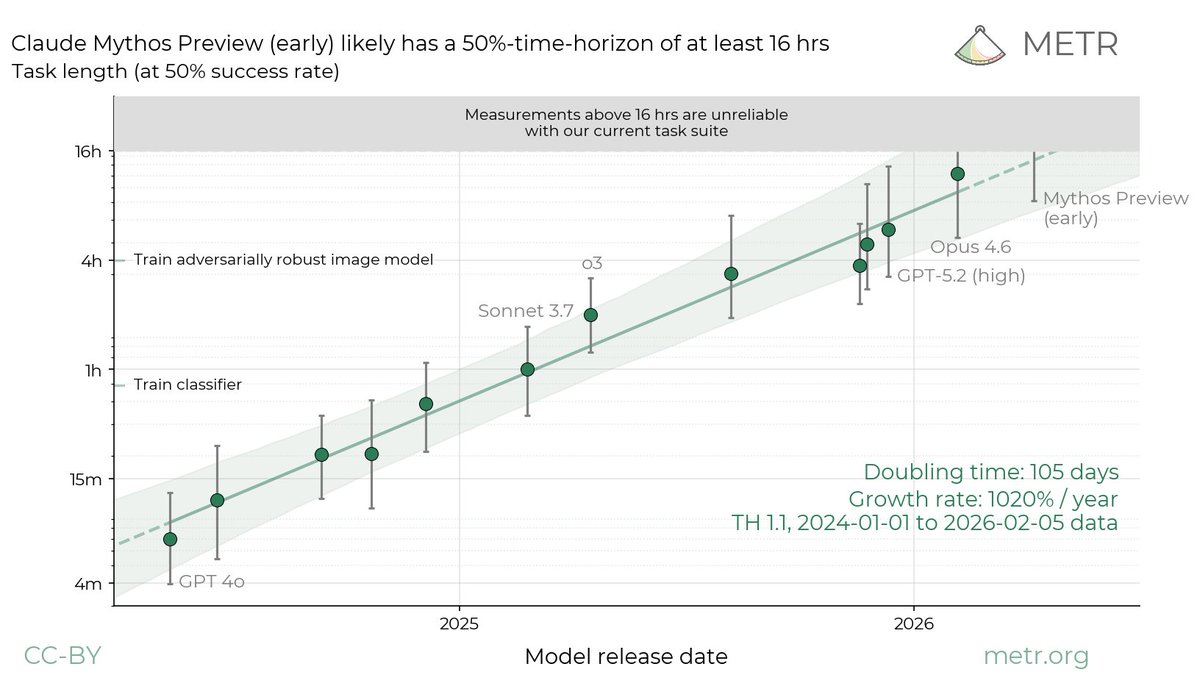
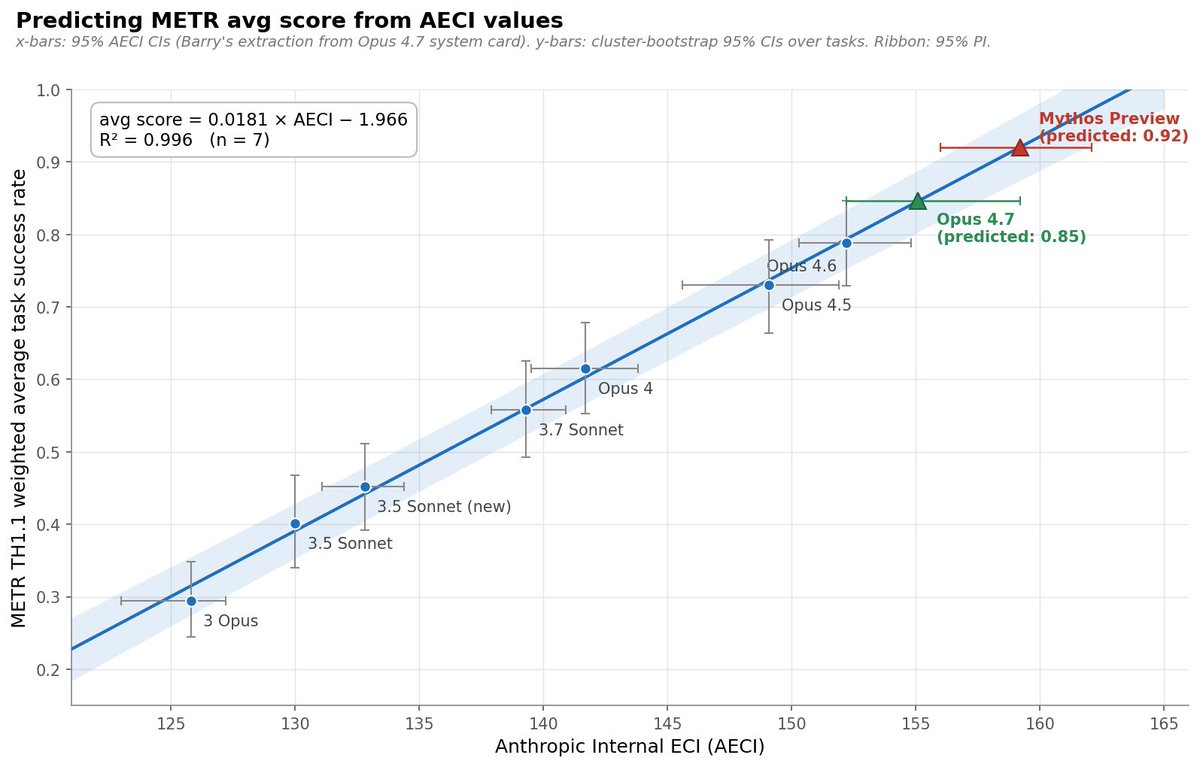
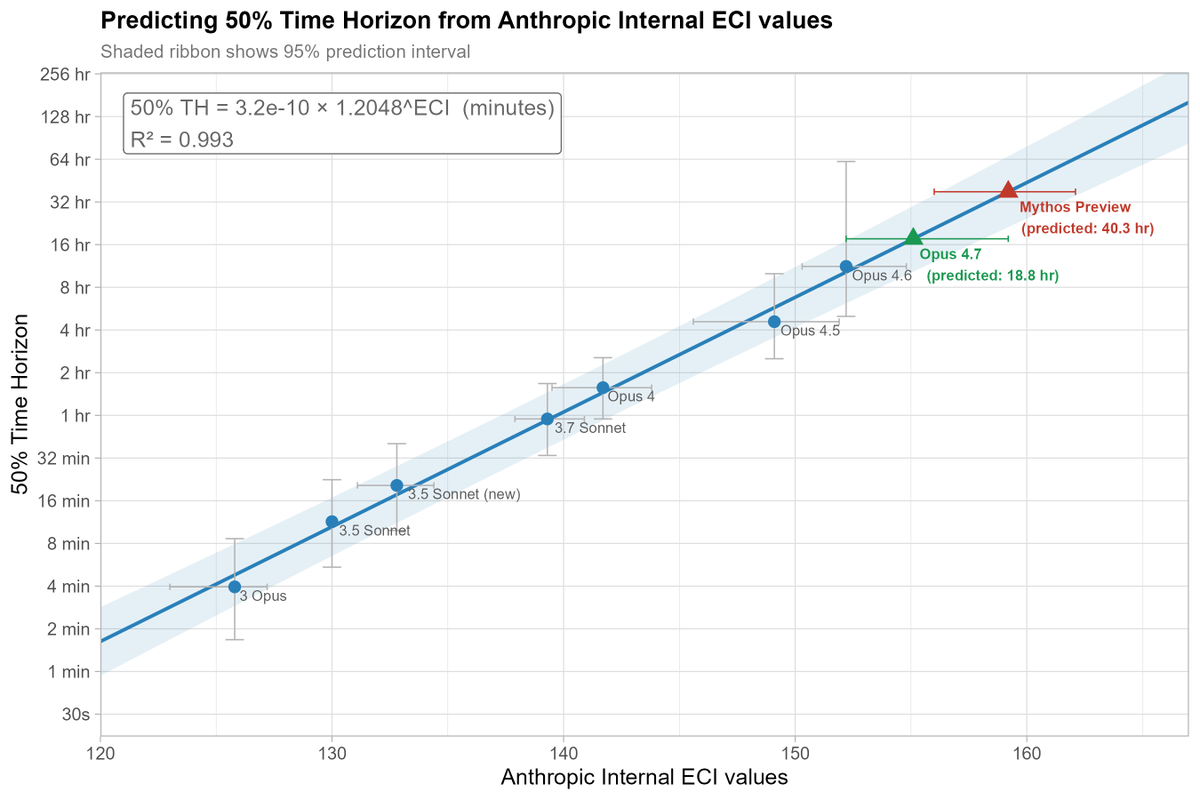
Interesting to work on this report with Epoch. We found that AI progress speeds have been accelerating since ~mid 2024 (on 3/4 of the metrics we considered).
Treating reasoning models as a trendbreak made the best predictions, but not enough data to be very confident.
Epoch AI@EpochAIResearch
Have AI capabilities accelerated? On 3 out of the 4 AI capability metrics we investigated, we found strong evidence of acceleration, around when reasoning models emerged.
English