🎱 BitcoinBananaBY retweetledi

🎱 BitcoinBananaBY
4.2K posts


@BitcoinBananaBY
GME x BBBY x CYDY x HOC to Uranus DD for stuff Tweets, Likes or Reweets are only personal opinions, not financial advice nor am I a financial advisor.

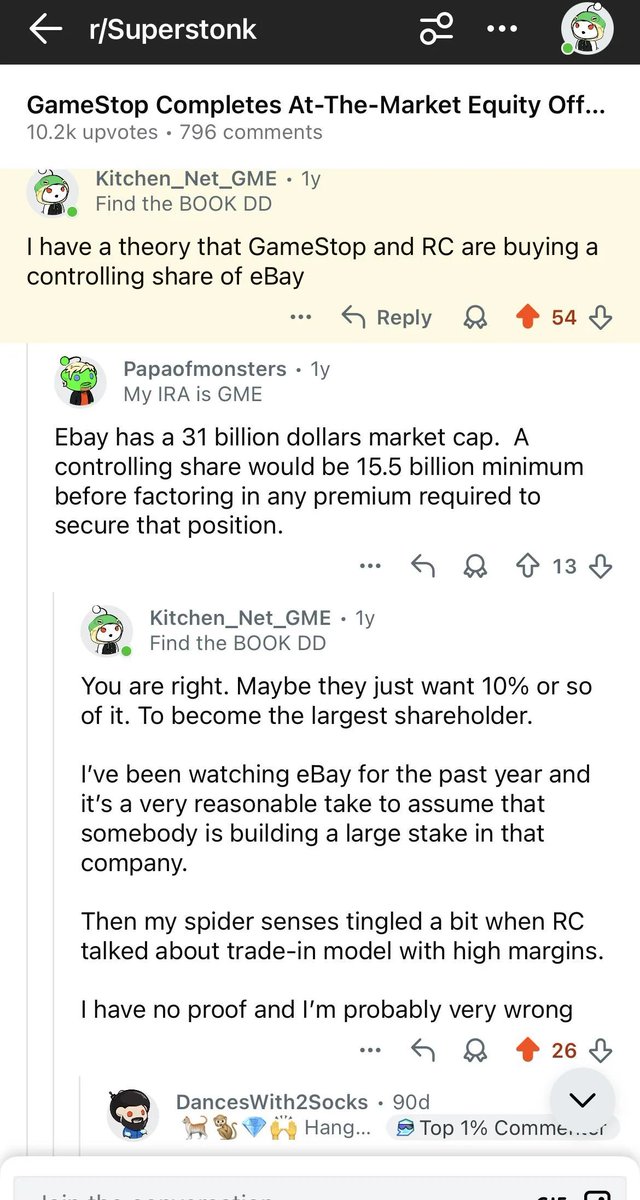









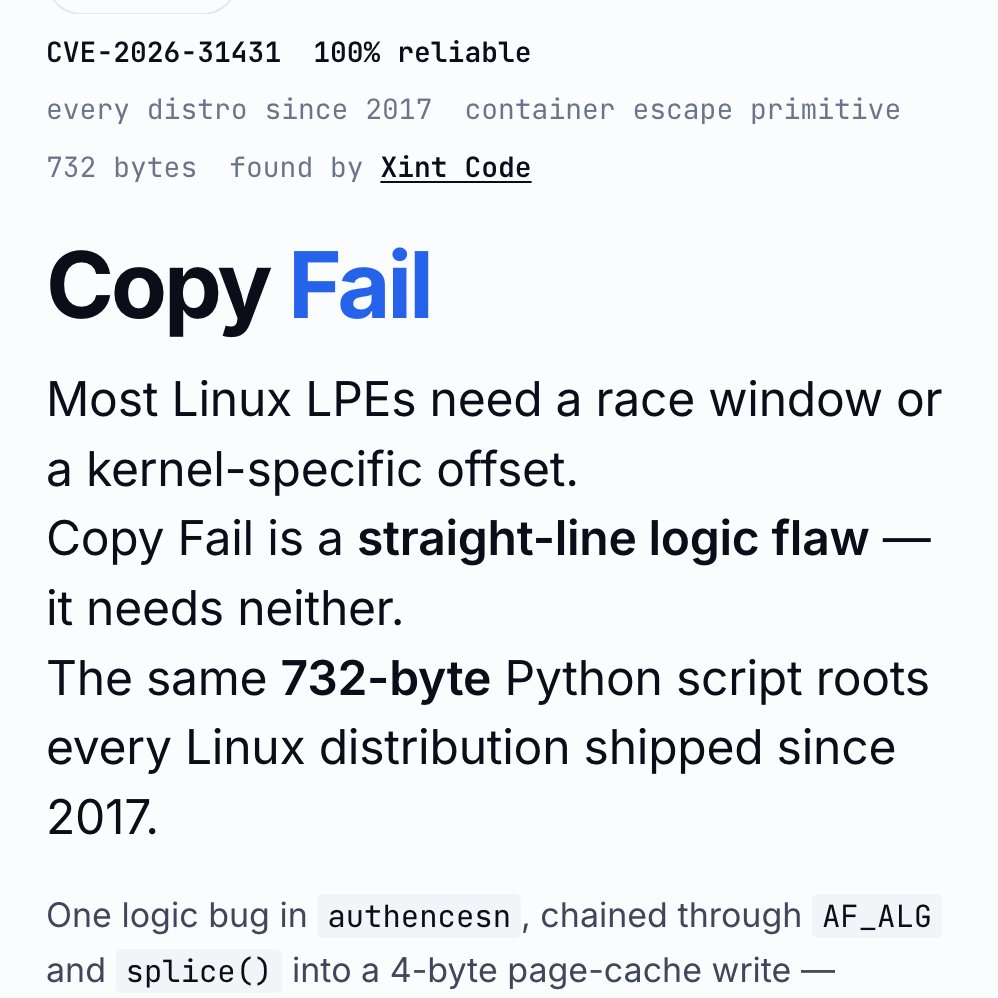







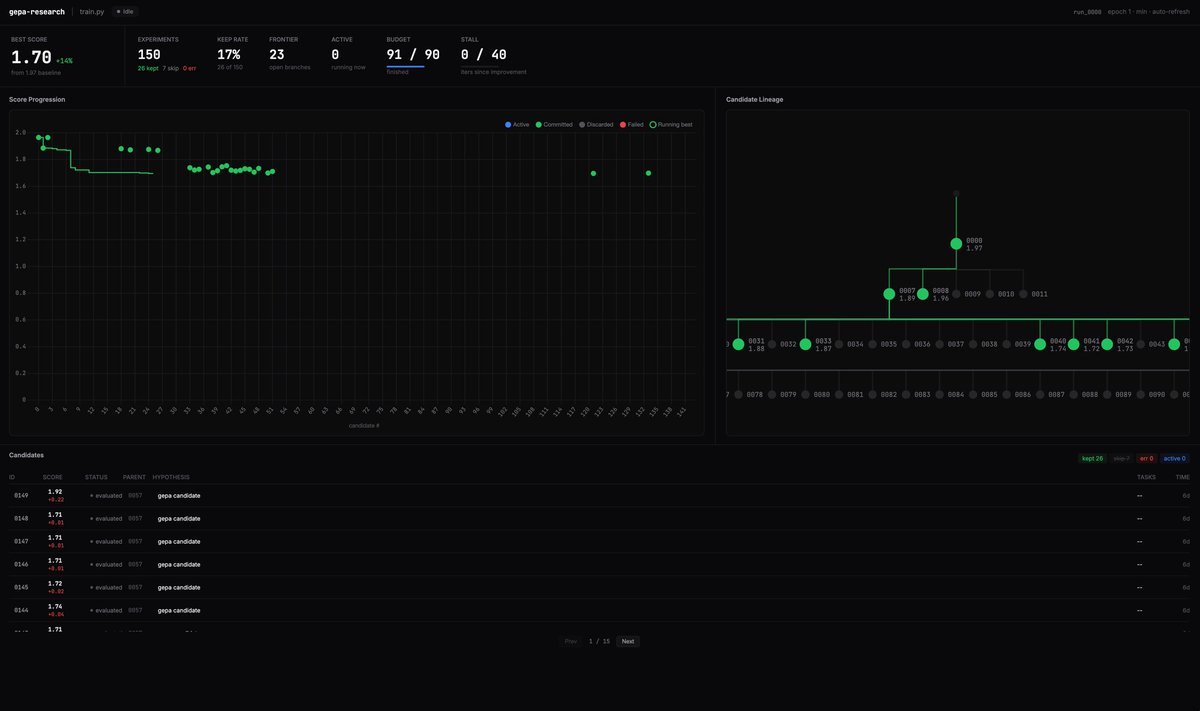
Thrilled to present GEPA as an Oral Talk and Poster at ICLR 2026 this Friday in Rio! 🇧🇷 Apr 24 Oral Session 3A (Agents), 10:30 AM BRT, Amphitheater Poster Session 4, 3:15 PM, Pavilion 3 x.com/LakshyAAAgrawa… Let's recap what's happened since we released GEPA last year 🧵