BuffandGrind retweetledi

Of course you want to hear a Prog Rock version of J.S. Bach's Toccata and Fugue in D minor!
Sky: Toccata (1980)
English
BuffandGrind
4.5K posts


@BuffandGrind
The MMO conversion therapy didn't take... also history should make you uncomfortable! How we understand money and monetize the Internet matters for society.








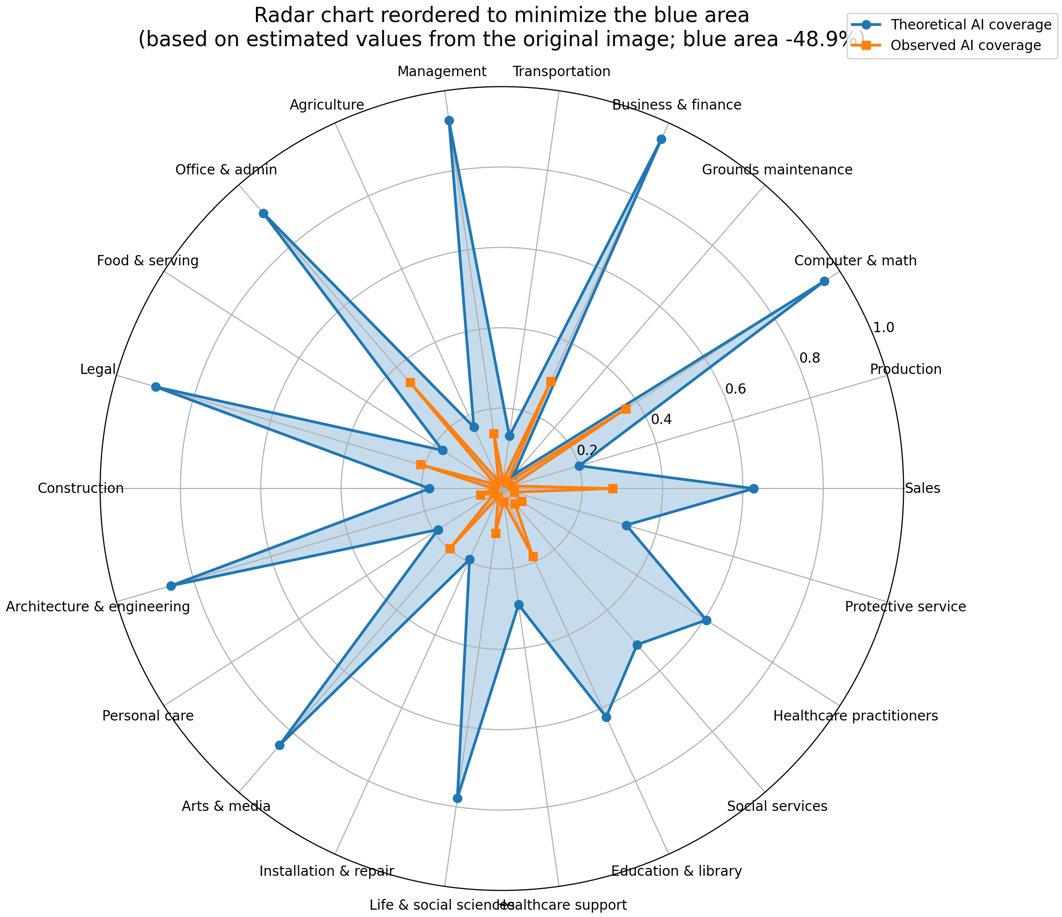
Striking image from the new Anthropic labor market impact report.

BREAKING: Anthropic CEO says Claude may or may not have gained consciousness, as the model has begun showing symptoms of anxiety.







@SaraGonzalesTX Why is it you feel so entitled that a private companies inner workings are any if your business?




