Xuyu
98 posts

华为τ scaling定律营销策略,无非是more than moore的广义摩尔定律的另一种说法而已
作为芯片架构师,我更感兴趣的,还是芯片密度提升,ppt上41%能耗提升和12.7%性能提升,到底是怎么实现的
看完了论文,感觉华为这次创新,本质上是用设计复杂度高 + 高制造成本 + 超前散热,一定程度弥补了工艺差距
-----------------
1. 华为芯片堆叠带来的等效密度提升,是虚假宣传还是真的,是不是工艺突破?有没有实打实的好处?
等效密度提升的来源,是两片芯片用hybrid bonding技术绑在一起,投影面积理论上能减小一半,但第一代不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292)
这2026第一代等效密度从 2025 年 155 MTr/mm² 跳到 2026 年 238 MTr/mm²,时钟频率也提升了12.7%,功耗比提升41%,表面上看似乎和工艺突破没有什么区别,但有一点重要区别就是leakage power华为从头到尾没有提,只要工艺节点不变,gate leakage、junction leakage 不会因为 3D stacking 自动改善
2030年到2031年的等效密度突变,大概率是来自于2层堆叠到3层堆叠,正如2025到2026年的等效密度突变,时钟频率突变,来自单层到2层折叠
所以从leakage没提这个事来看,这个2031年等效1.4nm,和工艺节点上的突破没有联系。
本质上是用设计复杂度高 + 高成本 + 超前散热 + 超前部署advanced packaging,一定程度弥补了工艺差距
-----------
那么这样看起来虚假的等效密度提升,有用处吗?好处在哪里?
有的,设计上topology折叠,原来要跑几毫米的水平走线,折叠后变成了几十微米。降低了super buffer/bus的长度,降低了clock tree的深度(clock depth -42%、clock wire -28%),clock skew也带来了改良(-25%),这对动态功耗的改善是实实在在的。部分critical path的缩短,也让时钟频率的上升更容易
所以ppt roadmap上performance的提升,从2025年到2026年上升了12.7%,大部分都是来自于时钟频率的上升(12.7%)
所以好处基本上是topology拆分电路逻辑设计上带来的提升
既然没有实质上的工艺提升,华为芯片堆叠带来等效密度提升的trade off代价在哪里?
三个代价:散热超前发展,设计复杂度高,制造成本变高
最大的代价就是热密度的同步上升,理论上logic on logic都是CPU execution发热最严重的区域,这部分折叠起来相当于功耗密度直接翻倍,但算上41% power efficiency改善,功耗密度仍只比非堆叠方案高40%左右。所以第一代只能对最关键的部分做折叠,大概只占全芯片面积的53%。
所以散热技术也被逼的超前发展,直接上毫米级的MEMS风扇,做micro-cooling fan。
另外的代价就是设计复杂度的变高,critical path的折叠,哪个部分的logic能折叠,折叠之后又会带来从前端到后端的巨大变化要推翻重来
现有的所有EDA工具也不可能支持3D topology,论文自己也承认,full-scale LogicFolding需要全新的3D-native EDA toolchain,把多层stacked dies当作单一连续设计实体处理。哪些logic能折叠、折叠后的inter-die timing closure怎么做,Physical Design(PD)也是难点
制造成本也会更高,被迫超前部署advanced packaging封装,1.5~2um的hybrid bonding + logic on logic都是很有挑战需要显著更高的成本
以前一层wafer做一次光刻;现在两层wafer分别做光刻再bonding,加上hybrid bonding的overlay控制(论文要求<0.5μm)、TSV、KOZ keep-out zone、冗余修复、良率乘法损失,每颗芯片的制造成本和测试成本都要显著上升
--------------------------
2. Tau scaling这个说法,scaling的到底是什么,这个scaling技术路线是不是一次性的design topology红利?潜力如何?持续进步的空间在哪里?
τ Scaling的核心主张是:用时间常数τ替代几何线宽作为全栈优化目标,在器件、电路、芯片、系统四个层级分别压缩特征延迟
公式本身没有任何新物理。"关注瓶颈延迟"是所有架构师都在做的事情。整个行业都知道互联RC是延迟瓶颈,TSMC每一代工艺都在用low-k dielectrics/semi-damascene等手段降RC。把一个众所周知的优化方向包装成"定律"是显然的营销宣传手段,本质是More than Moore的广义摩尔定律的另一种说法
抛开marketing,华为目前所谓RC delay的改善,本质上是芯片堆叠之后,topology距离缩短,让匹配的effective RC都变小,不是RC工艺常数
至于scaling的意思,是能持续发展的一条roadmap。这里的持续改善路径指的是,全芯片堆叠的层数越来越多,从25~30年的2层堆叠,到31年开始的3层堆叠,以后甚至会考虑4层堆叠
第一代折叠技术甚至不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292)。2031年的roadmap之所以会出现一个阶跃,就是因为那是从2层折叠到3层折叠的时间点。
但需要注意的是,这个scaling方法的边际效应是逐渐缩小的,折叠成双层的收益是100%,2->3层的收益就只有50%,如果2035年再从3->4层堆叠,收益就只有33%了
另外随着堆叠层数变高,上面说到的三个挑战,散热,设计复杂度,成本,都是越来越大
---------------------
3. 华为的芯片堆叠,是不是TSMC/AMD已经有的hybrid bonding技术?华为做到的是cache on logic,cache on cache,还是logic on logic,logic on logic最大的散热问题是怎么解决的?
是已经有的技术没错,但同时也是把现有技术指标做到了领先也是真的,3D堆叠本身不是新技术,TSMC的hybrid bonding量产还是6um,华为论文给出Kirin 2026的hybrid bonding pitch是1.5μm
我在刚刚看到华为的堆叠消息之后,第一反应也是怀疑和AMD的3D V cache类似,它主要把 SRAM cache 叠在 已经有的L3 cache 区域上,通常会避免直接堆在最热的 CPU execution logic 上,就是避免散热问题,毕竟SRAM 的功耗密度和热点特性与high-activity logic 不一样,如果最热的logic on logic堆叠,散热恐怕会碰到困难
但看了更多数据之后,clock buffer -56%、clock depth -42%、clock wire -28%,这些只有在core内部的clock distribution被重构时才可能发生。纯SRAM stacking不会碰core内部的clock tree。另外如果只是cache on cache,大概率是不需要单独MEMS微型风扇额外散热的,证据普遍都指向logic on logic方式
华为这个技术的精妙之处在于,logic on logic 折叠之后热密度并没有翻倍,而是因为topology的好处,能耗下降了30%,这样热密度只上升了40~50%
而第一代没有完全把整个最热的execution logic 100%堆叠起来,论文也明确说selectively applied along key critical paths,只是大概53%有选择性关键路径会堆叠起来,可能颗粒度都没有那么好,只是IP堆叠在IP上,那么热密度上升也许能维持在20%以内
但这条道路继续前行,超前发展的散热就成了必然,现在是MEMS微型毫米级的主动散热风扇,紧贴处理器传导效率高,和华为手机一样,散热堆料特别足,而且技术领先同行。
以后怕是要把HBM7/8的微流道散热技术提前用起来了,毕竟HBM7/8要上24+层堆叠,华为很可能要在提前用上下个世代的散热技术了
-------------------------
4. 从架构角度来说,最重要的问题,华为41%的power efficiency(能耗比)提升,到底是怎么实现的?为什么AMD的3D V cache没有这么大的提升?
首先确定41%的定义。论文只说"SoC performance-core power efficiency improved by 41%",没有给出benchmark名称、Voltage/Freq点、温度条件、功耗边界。但PPT roadmap上有一个关键线索:ISO-Power Performance的数字,2025年是2.75,2026年是3.1,提升12.7%
这个时钟频率提升12.7%完全一致,可以理解为,同功耗的性能提升是12.7%,绝大部分是时钟频率提升带来的
至于能耗比上优化的猜测是,LogicFolding缩短critical path → 在固定Vdd下Fmax从2.75GHz提升到3.1GHz → 这意味着在原来的2.75GHz频率下,有了约12.7%的timing headroom → 这个空间在iso-performance模式下可以换成更低的Vdd
另外的能耗比的提升,可能也来自于电路折叠之后,cache hit latency的下降。从业界经验来看,一般L2/L3 cache hit latency下降10%,CPU整体性能会有至少5%的提升
ppt里显示SRAM latency下降30%,估计会有一部分转化为cache hit latency的下降
AMD的3D V cache没有这么大的提升,主要是因为AMD的底层logic die并没有重新设计,3D cache的延迟latency不仅没有减小反而加大,只是增加了cache大小,收益不如latency下降那么明显。
另一方面,clock skew的下降,critical路径变短,造成电路timing变好,意味着华为可以使用更低的vdd(猜测甚至能低7~8%),以及路径缩短所带来的RC的下降(考虑到clock buffer -56%、wire -28%、SRAM pJ/bit -24%这些数字,比如C_eff下降10~15%合理),再加上clock tree的整体缩短和下降,确实是有可能在部分Voltage/Freq点做到同性能下,做到30%的功耗下降的,而30%的功耗下降换算过来就是41%的power efficiency
对比苹果和高通,每一代手机芯片在iso-power下单核性能一般提升10-20%,iso-performance下功耗一般降30-40%,这是V/F曲线的特性决定的,所以从经验上来说,数字是对的上的。
所以这个power efficiency(能耗比)的提升,从现有的数字上来说可以从topology推导出来是合理的,可能真的和工艺节点没有太大关系
----------------------------
5. 这个技术路线有没有可复制性,其他家会不会效仿?
短期内不会大规模效仿,因为性价比和风险收益比来说不好。长期来看,这个方向所有人都在走,只是名字不一样
华为做LogicFolding的根本驱动力是制裁,工艺节点被卡在7nm,只能在封装,散热,和设计层面想办法弥补。华为也为此付出了不小的代价:散热成本,设计复杂度,以及制造成本更高(包括良率)。这是一个被逼出来的路线,不是一个自然选择
其他玩家在用TSMC就能做到正常的经济迭代,是没有必要冒着这个风险,去超前迭代散热技术和设计复杂度的
长期来看,Intel的Foveros、TSMC的SoIC、AMD的MI300的3D stacking都在朝同一个方向走。如果继续追最先进节点的经济性持续恶化,那么"固定一个成熟节点+3D topology optimization"的路线会越来越有吸引力
散热方面,MEMS微型风扇和微流道也会成为未来HBM散热的主流
-------------------
总结一下,华为这次的创新,绝对是值得尊重的,在制裁环境下,用极高的设计复杂度和成本,在一个被锁定的工艺节点上大胆重新设计,榨出了一次大的topology红利,虽然它有天花板。每多加一层的边际收益递减(堆叠1->2层, 2->3层, 3->4层,提升百分比变小),leakage无法解决,散热越来越难,3D EDA工具链更是全新的挑战。
但这个Tau scaling不是一条可以走十年的指数增长路径,每次爬完一个台阶,下一个台阶更难爬,而且台阶更矮收益更小,华为以后想缩小差距,还得再想想靠什么其他的路线




中文
@fi56622380 @RYANHINGSHING @yinyanlong @ShanghaoJin @harvey_pang8964 @Minamilv @yiran2037840 同意,能单 rack 的,谁脑子抽了跨 rack 去 serve 一个模型。
中文
@RYANHINGSHING @yinyanlong @ShanghaoJin @harvey_pang8964 @Minamilv @yiran2037840 推理端这几年暂时只看到NVL1152,集群越大,主要的好处就是weights共享,但再往上边际效用不一定好
除非MoE每个rack分几个expert,多几个rack是合理的
即便如此,推理互联中scale out数量和scale up数量相比太少了
推理就是scale up为主没啥好说的,除非以后范式转移
x.com/fi56622380/sta…
fin@fi56622380
“未来异构推理要继续增大batch size,增大集群也是方向之一,比如NVL72变成NVL576/1152,那么推理会是scale up加上部分的scale out,比如说机柜内NVL72/144需要全部GPU连到NVlink上,这个连接数还是比8个rack之间要多多了,所以说推理仍然是scale up为主没啥问题” batch size的增大,意味着调度难度的增大,能100%利用HBM天花板的难度也越来越大,我不太确定这个趋势能继续做到什么程度 batch size增大的主要好处就是weights共享,所以还是有必要的,但是边际收益以后并不一定能持续无损耗,rack2rack太多导致通信延迟继续增大的话,边际收益是降低的 NVL1152应该还是正收益,而且值得
中文

算力提高过程中:
单卡:看GPU 架构设计 +HBM +CUDA 软件
机架72张:考验系统级集成 NVlink 热管理
万卡集群:就是光通 + 变电 + 交换机Fabric
中文

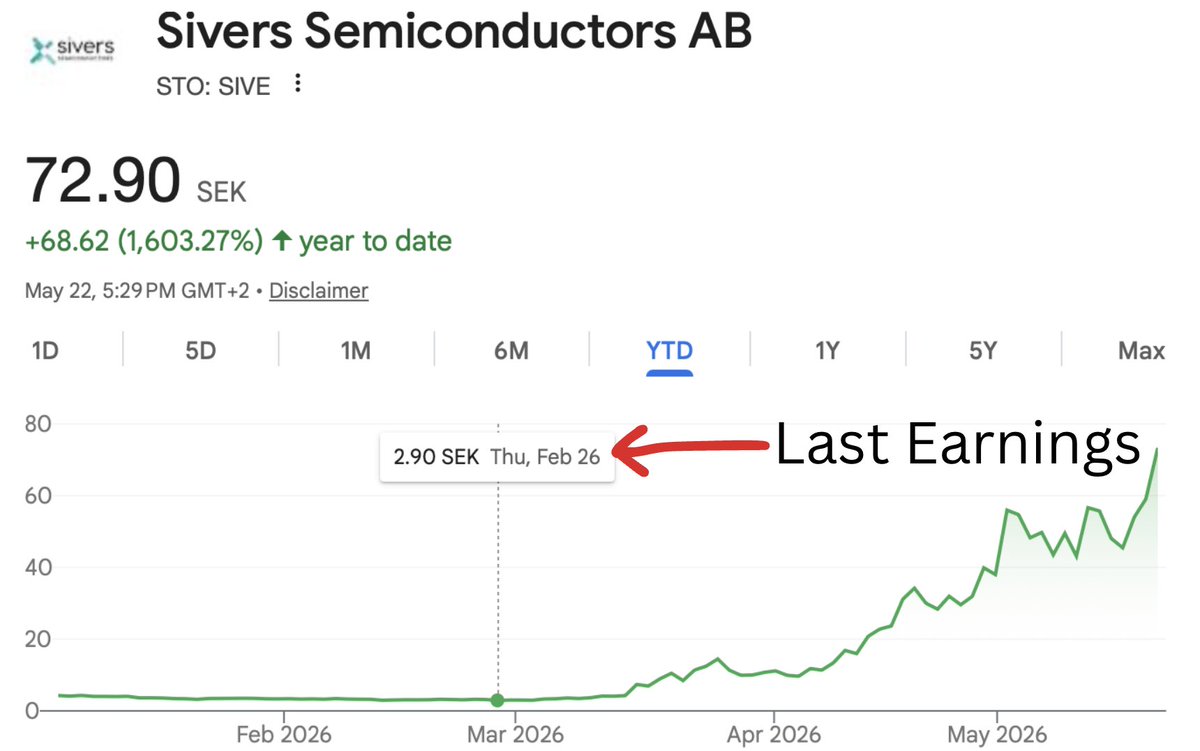
$SIVE is on a speculative, unsustainable rally that is not backed by any fundamentals.
Healthy parabolic stocks like $LITE, $BE, $AXTI, $SNDK either pop and grind up following each earnings event as new information is introduced to the market and improves the fundamental outlook OR they sell a raw material or commodity whose supply/demand dynamics and price can be tracked publicly.
$SIVE is neither. The last earnings call was on February 26th, to which the market had zero reaction; however starting mid-March, $SIVE proceeded to run 2000%.
No fundamental news was released to warrant such a re-rating. The O-Net and Jabil R&D partnerships are not new. The news that is actually needed to move the fundamental value: commercial volume orders with real dollar values attached, did not occur. In fact, they restated their FY25 EBIT net loss, which got worse.
My bearish campaign against $SIVE is only beginning. The higher this speculative stock runs, the more people will lose money; we must keep the damage contained. Those purposely spreading unreliable information to increase the market capitalization of an illiquid microcap to inflate their own wealth at the expense of everyday investors must be held accountable.
My short report is coming soon.
Jason's Chips@jasonschips
" $SIVE can reach $80b because $LITE is $80b" has to be the dumbest and most dangerous investment thesis ever. People will lose their savings listening to all this misinformation. It's sad and needs to stop (I am starting an anti $SIVE crusade). 1. $SIVE is not a bottleneck (despite it being the poster child of the photonics bottleneck craze). A bottleneck, by definition, must be the company that constrains the production of a massive downstream industry. To constrain production, you must both own hard physical assets and hold a dominant market share position. Sivers has neither. Sivers is a fabless design company that relies on WIN for Foundry services, and with revenues of ~$30 million, they hold near zero market share in the massive datacom laser industry. 2. Supply chain analysis is misleading. In semiconductors (or any industry producing a durable manufactured good) switching costs are near zero while process power, cornered resources, and scale dominate. Therefore, "who has a superior product" is far more important than "who supplies what to whom." CPO external light sources require quality lasers meeting noise (linewidth and RIN) and power (400mW+) specs. $SIVE lasers are far inferior to that of larger peers like $LITE. 3. $SIVE valuation is comically detached from reality. On NTM metrics, $LITE trades at 14x EV/Revenue and 32x EV/EBITDA while $SIVE trades at 50x and 650x (!!) those same metrics. As a permanent AI infra bull, I fully agree that consensus is too conservative; however, they are not off by two orders of magnitude. The misinformation needs to stop. Let's help actually help retail understand what they own.
English

jin老师确实是专家。厉害。
CPO扩产确实会比存储难多了。最根本的原因就是产业不成熟。因为CPO是真正意义上的异构,就不说封装难度直线上升。
仅就光芯片和电芯片封在一起,涉及到的耦合测试就远远超出预期,而且热稳定性要求实在太高。
而且确实激光器也不够。Coherent 和 Lumentum即便在加速扩产磷化铟产能,也还是不够。至少在2028年之前都不够,这里面化合物半导体跟硅晶圆半导体的生产条件完全不一样。
比如以4英寸的底为例,从籽晶在炉子里生长到符合要求的晶体也差不多需要几天时间,如果到6英寸,时间还会拉长。这就是化合物半导体的难度所在。
从衬底再往上做外延片的良率又得砍一刀。因为光这个玩意,对应的就是固定的波长,对外延的平整性和材料十分敏感。举个例子,就跟涂地板一样,你要地板中心的材料组成、平整度和边缘一模一样其实难度很大。
Herman Jin@ShanghaoJin
卡脖子投资,不光要看卡哪,更要关注哪卡更久、卡更死 眼光拉高,半导体全缺货,我早就说过every dog has its time 存储确实扩产虽非一蹴而就,但毕竟是有扩产经验的行业。我不质疑缺货,我质疑永久缺货,质疑给增长估值 光相比没扩产经验,应对AI需要要扩产+迭代,中处处被卡。CPO决无可能及时上量
中文


All I'm saying is CPUs are important but I can run 36 simultaneous subagents on my MacBook Pro and not get above 40% utilization
English
@fi56622380 @mweinbach 逻辑上如何回应他的这个质疑呢,我的Hermes和Claude code,用CPU也都是在本地,确实没感到有换机、增配需求。
或许重点是服务端Agent(Agent跑在server上,由于同时服务多个用户,导致CPU利用率远高于用户pc)。不过这一点缺乏体感,不知道占比多大。
中文
@mweinbach if you ask AI inference infra platform/vertical agent product folks, they would confidently telling you CPU hours are rapidly increasing because of surging demand on sandboxs for agents
it's already happening right now, and it's just the beginning of the beginning
English
@fi56622380 @ShanghaoJin @Balder13946731 感谢fin哥,关于国内长鑫扩产,这两天也做了点功课。浸没式光刻机数量,限制了长鑫的实际扩产能力,加上没euv锁死了工艺上限,hbm上御三家很难受到冲击。
中文


照MU逻辑,NV卡那么缺货是不是可以涨个价,PE马上低于10
你觉得NV rack层封装/CUDA/GPU门槛高,还是MU门槛高?
现在知道为什么周期性公司不看PE了嘛?甚至NV就前几个月都快陷入周期性估值了,为什么还那么fomo存储呢?
好了,存储话题不讨论了。肯定华丽,但不是我赚的钱,我也不眼红
Herman Jin@ShanghaoJin
@xizsam @fi56622380 缺货 ≠ 给PE估值 DDR出货占Wafer的75%+
中文
@Balder13946731 DDR崩盘了HBM wafer也一起下去了
哪怕挺着HBM封装,公司出货大头都是DDR,公司盈利也….
中文

聊一下关于川普动向/伊朗的一些想法:
话先说在前面,我目前的仓位选择还是科技股不对冲,套就套吧,自己的钱自己亏。
如果大家希望引入一个对冲仓位,我个人仍然认为 $cl 的近月虚值期权比较好,因为时间可控,如果要接着打基本上一两周之内就能知道。
$cl 的期权有一个好处,就是交易时间长,如果发生比如上一次油价暴走的周一凌晨那种冲上130的暴动,你能平仓,做 $uso 期权的人不能, 做 $xom $cvx 期权的人也不能。
正文:
我其实对于直接交易 “trump的想法/行为” 这件事非常的抵触,我觉得这根本不是人做的事,你要如何去揣测川普呢?他自己把弱点都暴露出来了,他怕市场不好,他怕油价涨,他担心中期选举,所有他的这些担忧都是被伊朗人拿捏的弱点。当下的现实与他个人的弱点共振,如果不继续战争,美伊谈判很难有进展。
但是如果恢复战争需要面对两个问题:
第一:战争理由。
总统个人一定是不想打的,当初以色列人以“杀了哈梅内伊伊朗就会完全跪下”为诱饵,才诈骗总统动手。
我们能够清晰的看到这个逻辑:即,以即时能得到的短期利益引导Trump作出行为。
但如果现在再打,理由是什么?是逼伊朗让步?是重新打开霍尔木兹?是摧毁剩余军事能力?还是政权更迭?
如何再次让总统相信这些目的如何能在短期内达成呢?怎么打,伊朗人才能放开海峡?以色列人的理由刚几个月前就没有达成。
第二,战争规模。
如果已经打过、也停火过,那么再次升级是不是应该奔着“彻底解决问题”去?
如果只是恢复到停火前的烈度,有什么意义呢?之前这个烈度下问题没有解决呀。但如果奔着彻底解决问题去,那就不是几轮空袭的问题,而是一个规模、弹药、后勤、政治承受力都完全不同的战争。
从目前能看到的开源部署看,美军当然有很强的空海打击、封锁和威慑能力,但这和一场可持续的灭国级全面战争不是一回事。
还有一个叙事问题:刚去完中国,如果马上重新升级,那前面的外交降温窗口算什么?中国在这件事里到底发挥了作用,还是完全没有作用,就算白去了?这对Trump自己的叙事也不舒服。
综上。
我不认为赌战争重新爆发是一个好交易,虽然看上去是不打不行… - - 但是我找不到什么合理性。
想一想这观点怎么交易?
你说油企长线看好吧我完全同意,一直同意,但是主要问题是我不觉得长线油企能跑赢AI。
短线?现货是不可能的,现在经常一惊一乍的出各种消息,然后带来大波动,能源股不像是AI股,能源股砸个坑我没有信仰的,大概率会割肉。
所以,想对冲的短线还是 $cl 近月深虚吧,我科技股不对冲。
至于为啥写这些却要引用 @fi56622380 老哥的推文?也没啥理由,就是觉得这个推文写得好呀。
fin@fi56622380
AI半导体终局推演2026(I) 当新token经济学范式从GPU算力转移到HBM 本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题: 每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞? 并推导token经济学在当前架构下第一性原理:token吞吐 = HBM size X HBM BW带宽 同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定 HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。 我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样 ------------------------------- 历史:CPU算力时代 很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等 这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久 因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级 为什么DDR带宽速度提高了用处不大?两个原因 1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求 2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载 也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。 另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。 所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。 而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长 所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系 -------------------------------------------- 而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化 GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput 其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。 这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度 AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多 而老黄在推理时代的token经济学是: AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多 最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化 (见图一) NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI ---------------------------------- 接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长 单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大 但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量 Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度 也就是batch size X per user token 速度 以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得到单位MW能处理1.6M token/s (见图一) 所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量 ------- 第一个参数:batch size的增长,瓶颈在HBM size 批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache 随着批处理数量batch size的增长,会带来hot kv cache的线性增长 又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长 就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟 结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长 --------- 第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽 大模型decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍 LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的 就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快 GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术) —----- 在那个接驳车的比喻例子里 接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。 接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。 旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度) —--------------------------- 至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理: Token throughput = HBM size X HBM Bandwidth AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的 如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍! 这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput! 要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较 (见图二) 可以发现,这两个曲线的走势在对数轴上惊人的一致 HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干 这条曲线不是巧合,而是系统最优化的必然解 throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理 —-------- 软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求? 这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛 这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去 GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事 只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止 如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗? 当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分) —-------------------------------------- HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央 推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关 剩下的问题,只有一个: 当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?
中文
A dollar saved on wages does not disappear, but it also does not necessarily go to the displaced worker. The core issue is not whether AI creates aggregate value; it is whether people who lose labor income have a viable way to share in that value. GDP can go up while millions of workers become worse off.
English
"I really worry about who is going to pay after AI takes their job."
Behold economics' most common fallacy: ignoring the conservation of economic energy. One dollar not paid to an employee does not disappear! It instead accrues to the other two stakeholders in the business, the customer and the shareholder. If AI creates net value, everyone will be richer, not poorer. None of this unemployment nonsense holds up under simple logic. Higher.
Ben Pouladian@benitoz
Seeing a lot of smart people calling hyperscaler AI capex a death spiral. These two posts capture the bear case well $GOOG as a "structural funding short" and $AMZN as an FCF implosion. I respect the thinking. But I've seen this movie before. As someone who built and scaled a hardware company from zero to $50M+, I'll tell you this: the moments that look most irrational to outside observers are often the moments of deepest strategic clarity for the people inside the arena. The Reagan/Star Wars analogy from the first post is actually perfect — but not for the reason the bears think. Reagan didn't bankrupt America. He bankrupted the Soviets by forcing them into a spending war they couldn't win. The spender with the strongest balance sheet and the highest-margin core business wins. Google has Search. Amazon has AWS + Prime. These aren't companies stumbling into reckless spending. These are money-printing machines making a calculated bet that whoever owns AI infrastructure owns the next decade. The "dead zone" everyone fears? That's the moat being dug in real time. Now zoom out and ask: when the biggest companies on Earth are all sprinting to build simultaneously, who sits at the center of gravity? $NVDA. Not as a competitor in the race but as the foundation the entire race runs on. Every dollar of this $700B+ super-cycle flows through compute. First principles say follow the capex. The capex says $NVDA
English

AI半导体终局推演2026(II)
目前的topic
为什么HBM在结构上很可能会摆脱传统周期性,进入成长周期性?HBM的升级节奏会如何发展? (tiktok节奏,size和speed交替换代升级)
这会给HBM的供应和需求市场带来什么样子的capex成本结构变化?Capex内战里为什么HBM会持续占优势? 为什么Nvidia未来最大的竞争对手不是AMD,是Samsung,Hynix,Micron?
AI推理时代,这个依赖HBM指数增长的GPU架构路线进化路线,会不会停止?什么时候停止?
那么以后DDR和NAND呢?有没有摆脱周期性的可能?
AI Semiconductor Endgame Scenario Analysis 2026 (II)
Current Topics
Why is HBM structurally likely to break away from traditional cyclicality and enter a growth-cycle paradigm? How will the upgrade cadence of HBM evolve?
(A “TikTok-style” rhythm: alternating generational upgrades in capacity/size and speed.)
What kind of changes will this bring to the capex cost structure in the HBM supply and demand markets? In the internal “capex wars,” why will HBM continue to dominate? Why will NVIDIA’s biggest competitors in the future not be AMD, but rather Samsung Electronics, SK hynix, and Micron Technology?
In the era of AI inference, will the GPU architectural path—highly dependent on exponential growth in HBM—eventually come to a halt? If so, when?
What about DDR and NAND going forward? Do they have any possibility of breaking free from traditional cyclicality?
中文
AI半导体终局推演2026(I)
当新token经济学范式从GPU算力转移到HBM
本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题:
每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞?
并推导token经济学在当前架构下第一性原理:token吞吐 = HBM size X HBM BW带宽
同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定
HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。
我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样
-------------------------------
历史:CPU算力时代
很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等
这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久
因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级
为什么DDR带宽速度提高了用处不大?两个原因
1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求
2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载
也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。
另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。
所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。
而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长
所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系
--------------------------------------------
而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化
GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput
其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。
这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度
AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多
而老黄在推理时代的token经济学是:
AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多
最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化
(见图一)
NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI
----------------------------------
接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长
单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大
但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量
Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度
也就是batch size X per user token 速度
以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得到单位MW能处理1.6M token/s
(见图一)
所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量
-------
第一个参数:batch size的增长,瓶颈在HBM size
批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache
随着批处理数量batch size的增长,会带来hot kv cache的线性增长
又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长
就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟
结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长
---------
第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽
大模型decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍
LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的
就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快
GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术)
—-----
在那个接驳车的比喻例子里
接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。
接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。
旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度)
—---------------------------
至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理:
Token throughput = HBM size X HBM Bandwidth
AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的
如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍!
这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput!
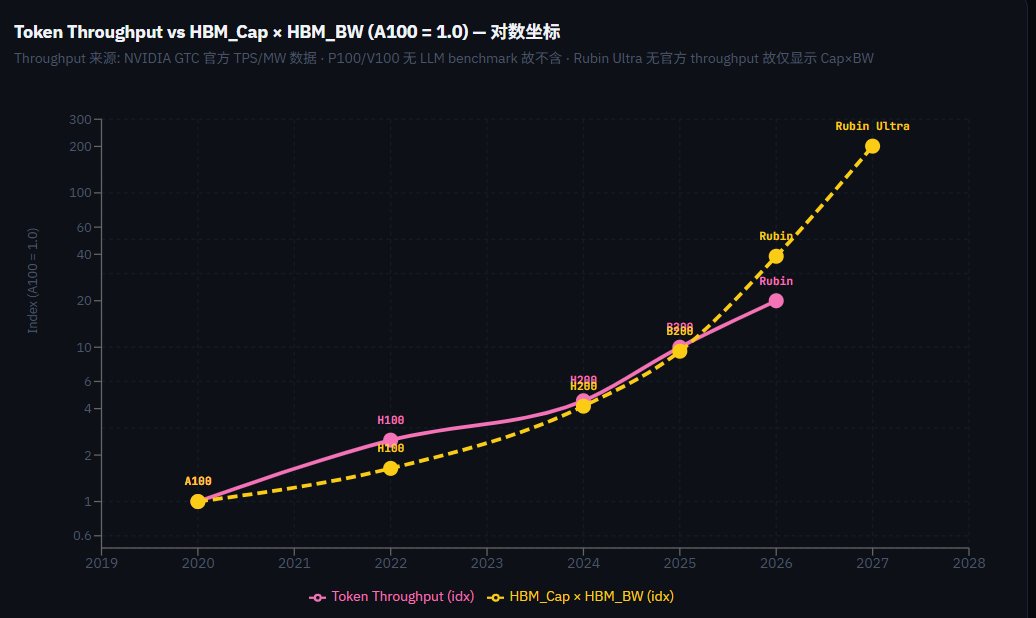
要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较
(见图二)
可以发现,这两个曲线的走势在对数轴上惊人的一致
HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干
这条曲线不是巧合,而是系统最优化的必然解
throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理
—--------
软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求?
这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛
这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去
GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事
只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止
如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗?
当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分)
—--------------------------------------
HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央
推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关
剩下的问题,只有一个:
当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?

fin@fi56622380
回顾2025年半导体市场,真的是有太多太多精彩的故事,最大的主题就是: AI需求驱动导致半导体基建的估值体系重构 + 产业链的价值分配重写 从2024年开始,半导体基建正在飞速吞噬整个IT产业利润,SP500里半导体净利润EPS在IT行业里占比,在两年时间从不到20%上升了到了40%,而且还在呈加速上升姿态 半导体整体前瞻利润率从2023年的25%已经升到了2025年11月的43%,已经明显超过了几个互联网巨头的平均利润率,这也印证了半导体利润率超过互联网会是新常态。整个IT产业的利润分配,流向半导体的比例越来越大。 要知道,就算是20~22年的半导体芯片荒,短缺如此严重,半导体的利润率和整个IT利润分配也没有显著增长 这就是故事的上半篇:AI需求驱动导致半导体基建的估值体系重构,不再是互联网时期的基建从属地位 ------------------------ 这个现象背后的逻辑是商业模式随着技术特性的变迁: 互联网时代,每次请求的网络和算力成本,边际成本极低,scaling的效果极好,分发的边际成本几乎为零 在AI时代,这个互联网时代分发边际成本几乎为零利于scalable的特性遭遇了根本性的重大挑战:且不说训练成本从此不是一次性开销而是年年增长,就客户的AI推理请求而言,由于inference scaling成为共识,加上垂直领域仍然需要更大规模的旗舰模型来保持竞争力,推理的成本不会随着硬件算力价格的通缩而同步降低 互联网企业从前的最大成本只有OPEX尤其是SDE人工成本,而现在,互联网公司历史上第一次像半导体厂foundry那样背上高折旧成本的资产负债表,商业模型恨不得要慢慢从“流量 × 转化率”部分转向“每 token 毛利”了 简单的说,互联网时代到AI时代的成本分布,在人力成本opex的基础上又加上了沉重的硬件/算力成本capex(财报里占比:MSFT 33%, Meta 38%)。 上个时代的互联网公司+CSP+SAAS是收租行业里的大赢家,而AI时代,算力(半导体/芯片折旧)成为了新的收租行业,整个IT行业的利润分布发生了剧烈的重新分配(EPS利润流向半导体从20%升到40%而且持续攀升中),这就是半导体基建估值体系重构最重要的原因 --------------- 半导体高利润率的新常态趋势能持续多久? 目前的高溢价来自于前期不计成本的军备竞赛造成的半导体订单积压过多 但很显然,hyperscalers都不愿意当冤大头,都在试图自建ASIC降低成本,那么可以从2030年远期的算力分布来回看这个问题 长线来看,openai已经明牌了标准答案,10GW Nvidia,10GW ASIC,6GW AMD,其他hyperscaler划分比例有类似考虑 比如说,推理端希望ASIC >50%,GPU里再细分的话,AMD和NV(legacy)对半分。训练还是得NV占大头,60%+,剩下的自研ASIC和AMD对半分 2030年按60%推理,40%训练比例划分,算下来NV 38%, ASIC 39%, AMD 23%,跟openAI比例是几乎完全一致的,算是一个标准答案参考值 当然了,微软,Amazon,Google,Anthropic这几家里AMD的比例会比这个标准答案中枢/参考值明显低一些,xAI则是没有ASIC只有Nvidia+少量AMD AMD的风险在于,当2030年再往后的更长期,CSP的in house ASIC越来越成熟(微软除外),推理端ASIC占比可能越来越高,很难有incentive新买入大量GPU了,除非卖的足够便宜 最近风头正劲的TPU呢?Meta是不是要转向TPU?对Nvidia的利润率影响大吗? 实际上,Meta今年capex72B,明年capex110B,未来六年capex平均值可能达到160B附近,而Meta 6年10B的TPU订单算下来年均只有1.6B,而且购买的是TPU云服务,并不是裸TPU 也就是说,Meta这笔TPU订单只占到Meta未来6年capex的1%,并没有严肃的考虑大规模部署,可能只是作为和Nvidia讨价还价的手段而已 另外从Meta最近几个月的招聘广告来看,也并没有看到任何TPU engineer方面的招聘,不像 Anthropic那样从五月就招一堆TPU kernel engineer,十月才宣布大规模采购TPU做训练 所以说,不管原因是diversify供货商,还是给自研ASIC延迟做退路,还是因为AMD的MI350X延迟,Meta买TPU基本上只有一个考虑:增加买Nvidia GPU的议价权,但顶多只有推理份额里能讨价还价,实际效果很有限,对Nvidia利润率影响也很有限。 要知道,22年加密货币熊市矿难的时候,NVDA库存上升到了198天,利润率只是从65%回撤到了56%,算上PE/宏观双杀股价才从300变100,现在一直供不应求,利润率没道理能降下来 再加上TPU v8设计过于保守(没用HBM4),Kyber rack的Rubin方案会比TPU v8的TCO更好,到头来最后还是得继续依赖Nvidia,很难议价。只要Nvidia继续保持这样的大踏步前进,竞争对手其实要跟上还是不容易的。 总之,一方面,全产业链瓶颈,比如cowos扩张都很谨慎,供不应求的状态还能持续多年。 另一方面,AI变现的利润曲线和硬件投入曲线存在“时间错配”,应用端的增长曲线会落后几年,只要这个应用端和基建端的增长曲线的时间错位依旧存在,半导体在IT行业的利润分配就会一直占优势。 从OpenAI的到2030年的投入曲线来看,这个时间错位至少要持续到2030年附近。也就是说半导体行业的超级扩张期带来的在IT产业利润划分的主导地位,目前看至少能持续到2030年 而半导体高利润率可能会维持的更长远一些,因为从互联网时代一次性基建属性变成了现在的收租基建属性 --------------------------------------------------- AI 不是只养活了 GPU,而是在用算力预算把“能把电变成 token 的每一环”都抬了一轮,从内存,存储,互联,光纤,电力,储能…..等等 上半篇讲完了“半导体吞噬IT利润”,那么下半篇讲的就是“AI算力价值溢出效应(Spillover Effect)重塑半导体内部格局”:GPU算力增长 -> 内存/存储/互联/CPU瓶颈 -> 溢出效应 -> 结构性机会 2025 年更有趣的故事,是巨大的行业红利在半导体内部怎么诞生结构性新机会,比如说,一个super cluster需要几个数据中心互联,光纤互联的长度需要上百万mile这个级别,这就是新机会 半导体产业链的结构性趋势带来的新机会,最典型的例子就是内存(DRAM/HBM)和存储(SSD),HBM的需求增长太夸张,连带挤压DDR4/5产能,直接让以周期性为标志的内存行业甚至喊出了“周期不存在”了,Hynix因为在HBM上领先,甚至都开始憧憬起了几年后年利润1000亿美元,妥妥一个万亿市值的公司 这两个板块背后,是结构性趋势的转变:AI workload从训练逐渐往推理延申,推理比例越来越大。 而推理是一个非常纯粹的吃内存带宽速度(memory bound)的事情,可以说带宽速度=token/s。模型尺寸越来越大,以及上下文context length的增加,对内存的尺寸要求也相应增大,导致了内存的需求激增:推理即内存 下一代的的GPU/ASIC内存已经成了暴力美学,配备的内存size之巨大,是三年前无法想象的,回看22年H100的80GB简直像个玩具,这才几年就增长了十倍: Nvidia Ultra Rubin - 1024GB HBM Qualcomm AI200 - 768GB LPDDR AMD MI400x - 432GB HBM 内存的另外一个潜在的爆发点在端侧,也就是手机/PC/汽车/机器人的端侧LLM,这两年主流的手机旗舰机已经从6GB升级到了8GB/12GB/16GB,提前为可能的端侧LLM生态做准备,毕竟手机算力下一代就能达到150TOPS量级,妥妥的桌面级,非常暴力 潜力上来说,端侧内存升级是比云端内存增量要更大的市场,毕竟端侧终端device的数量太惊人了,每年都是billion级别,一旦端侧LLM生态繁荣起来,内存用量翻倍轻而易举,针对端侧低功耗内存/存算一体的各种设计都会跟上 但端侧genAI的软件生态,似乎明显滞后,一直比我想象的进度要慢,可能是因为这方面还处于摸索期,并没有云端那么确定的ROI,厂商们在投入上都很谨慎,我在23~24年时候看好27年,可能还是太乐观了 互联网->移动互联网用了10~15年,端侧genAI/LLM可能也需要7~10年,可能得等云端ROI开发的差不多了,边际收益下降了,才能轮得到端侧genAI/LLM拿到开发资源,跑通端侧ROI。 -------------------------------------- 另一个2025年半导体内部结构性转变的故事是NAND存储,特别是企业级eSSD硬盘 结构性趋势来源也是同一个,AI workload的推理需求越来越大。内存红利也外溢到了SSD存储,甚至HDD存储,因为内存不够用就用高速SSD作为多级缓存 主要逻辑是AI推理过程中内存溢出KV cache offloading到下一层SSD存储,以及向量数据库检索/indexing,都在增加SSD存储的需求 Micron财报说的精准又直白:“AI inference use cases such as KV cache tiering and vector database search and indexing, are driving demand for performance storage.” 至于为什么存储价格在第四季度才爆发,这需要区分一下合约价格和现货价格,合约价格涨幅会温和一些,就算是最紧缺的企业级eSSD合约Q4上涨大概25%。而当NAND产能在2025年被合约慢慢的吃光,现货的价格就造成了观感上强烈的冲击,一个月上涨50%以上。 另一个未经验证的逻辑是多模态的爆发,特别是AI图片和AI视频的需求爆发,也会加剧存储的短缺,我觉得这条线只能说未来可期,但目前的视频/图片精细程度,可能还不到当年GPT3的水平,要达到出圈效果还需要一些时日。 ------------------------ 那么下一步还有什么趋势转移带来的半导体结构性的机会呢 那么就要先看下一步AI推理端的需求趋势是什么,毫无疑问,agentic flow的比例会越来越大,2025并不是year of agent,而是一个decade of agent 从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,甚至CPU能耗也超过了总能耗的40% Agentic AI目前是一个CPU瓶颈更多的事情,在 agentic 框架里,CPU 是永远在忙的总指挥orchestrator, 很可能会成就CPU需求的新一波回暖 AMD 2025年Q2财报(8月5日),Lisa Su明确表述了这一现象:"In particular, adoption of agentic AI is creating additional demand for general-purpose compute infrastructure, as customers quickly realize that each token generated by a GPU triggers multiple CPU-intensive tasks." "agent AI的采用正在对通用计算基础架构产生额外的需求,因为客户很快就意识到GPU产生的每个令牌都会触发多个CPU密集型任务。" Q3 财报里Lisa又明牌了一次CPU TAM increasing due to Gen AI. "Many customers are now planning substantially larger CPU build outs over the coming quarters to support increased demands from AI, serving as a powerful new catalyst for our server business." Nvidia也是把agent flow视为CPU需求,GB200/300 架构配置的CPU比例也比以往大的多,36颗 Grace CPU : 72颗 Blackwell GPU,直接达到了1:2的水平,AMD的路线则是用1~4个256核的EPYC去服务MI400系列72~128个GPU 以后的硬件架构,一定会往优化agent workload方向发展,比如agent task graph的调度和load balancing,CPU/GPU协同micro-batching 算力上的比较,说不定以后也会摆脱现在的纯GPU token rate比较,转向整个系统级全栈agentic benchmark比较. -------------------------- 半导体结构性转变带来的机会同时,下一步,可能也会带来一些意想不到的次生效应 云端AI数据中心需求爆发,造成内存和存储的暴涨,给消费电子的成本带来了很大压力,在2026年,这也许会演变成消费电子产业潜在的黑天鹅 PC厂商最近的股票大跌,也是这个原因。HP已经说了要减少内存配置,暗示要把PC重回8GB内存+256GB存储的时代了。 DRAM内存和存储再这么涨下去,可能会出现很离谱的情况:内存/存储现货价格比CPU和GPU还要更贵。尴尬的是,这可能直接延缓了消费电子期望的AI PC的进程,毕竟大内存是更有利AI PC的表现力的。 夸张的说,每个PC厂商和手机厂商的员工,甚至是消费电子厂商的员工,都应该买入存储和内存,作为职业风险对冲 明年年初开始,安卓阵营的内存以及存储成本要压不住了,三星,小米的手机售价都提高的话(美国市场现在已经提高不少了),利好最大的就是苹果 苹果的内存产能,nand产能都是专属长约锁价特供的,顺带还把Kioxia给坑了好多不涨价产能,导致苹果的成本优势进一步扩大,苹果全球手机销量市占率增长可能会非常可观,接下来一阵子可能会是iphone辉煌的时光。 ----------------------- 2025年半导体市场真的是太多精彩的故事了,Nvidia/AMD/TPU和各家hyperscaler的恩怨情仇引得各路下注的吃瓜群众心情跌宕起伏。 HBM/内存厂商吃到了memory-bound的红利,NAND厂商意外收获了KV cache的溢出效应,CPU在沉寂近十年后,可能会因agent orchestration再次回到增长叙事的中心 不再是Nvidia/AVGO几家算力厂商独大,而是AI workload算力价值溢出后的每一次演进,从训练到推理,从文本到多模态,从单模型调用到agentic flow,都在重写产业链的价值分配。 云端AI的繁荣正在挤压消费电子的生存空间——当PC厂商被迫讨论重回8GB时代,苹果却因供应链优势坐收渔利。这场算力军备竞赛的次生效应,可能在2026年以意想不到的方式重塑整个消费电子格局 半导体的故事不再是一条单线,而是一张持续自我重构的网。而 2025 年,大概只是合纵连横的第一回合
中文
@fi56622380 @m0d8ye 这个逻辑从需求端看确实过硬,百分之七十以上的需求增长,供给端看目前虽然三家都在扩产,但有效产能受限于 HBM 复杂性,目前还追不上需求的增长,只要这三家不上头,hbm 现在仍然低估
中文
@CatAccept @m0d8ye 我给一个简单的breakdown吧,不要bottom up,容易陷入迷雾
top down来看,增速在三层:
hyperscaler营收每年~20%增速
capex占hyperscaler营收比例每年~20%增速,从25%到30%到35%
capex内部HBM分配比例,26~28年每年20%增速,从30%到42%
这就是HBM额外高速增长的基础
中文
Xuyu retweetledi

我是怎么实现「境外投资 → 境内花钱」的?
今天分享一下我如何在境外投资,不用把钱拿回来就可以在境内花境外的钱的思路吧。
最近几年,我通过投资美股资产,算是通过投资逐步构建起了每月稳定的现金流,同时也持有了标普、纳指这种长期增值的核心资产。
作为一个在大陆生活的人,这套体系产生的被动收入已经完全了覆盖日常开销。
先说我奉行的一条核心原则:出境的钱,永远不回来。
第一步:搭好境外的「钱生钱」池子
我把我的资金分成三个池子,各司其职:
1. 现金流池(防守型), 配置美债ETF(我买的BOXX),通过每月产生的利息作为流动资金,用来覆盖日常消费支出。当前美债这个ETF的收益率在 4%左右吧,这个池子本身也具备一定的抗风险属性。
2. 增值池(进攻型) ,我买了 VOO(标普500)、QQQ(纳斯达克100)、BTC,还有之前一直长期持有的大科技股 ,只买不卖,靠复利和时间滚雪球。这部分资金不参与日常消费,目标是长期资本增值。
3. 持续成长的池子, 境内工作、副业产生的结余资金入金IBKR以及嘉信理财,定投标普500,另一部分直接留存在境外银行账户,充实流动资金池。
这样形成了一个正循环:境内赚钱 → 购汇出境 → 池子越滚越大 → 产生的被动收入越来越多。
第二步:消费
这一步我用香港信用卡比如我用的pulse和美国信用卡(这个就很多了)直接在大陆消费,还款资金来自境外账户,实现境外的钱在境内花而无需结汇回国😂。
第三步:大宗支出
像是车贷月供我直接用汇丰 Pulse 卡刷的,走银联通道,也没啥额外费用。然后我还留了一笔境内应急资金,突发情况用来做兜底。
这套思路的风险我觉得目前最大的就是政策与合规风险,因为国内对银行卡境外交易也是有监控系统的,不知道政策环境会不会收紧?
大家觉得有什么意见么?
中文
@fi56622380 @m0d8ye 请问 fin 哥,您通常用什么数据预判这个供需平衡的时间点呢?三家资本开支涨幅算是一个 proxy,但显然误差太大了
中文