Sabitlenmiş Tweet

Love to put bass vibes in my tracks.
Hence the use of didgeridoo loops and being percussionist, I enjoy mixing both instruments.
Gives a funky groove to the thing.
Enjoy Didg’Em
Spotify :
open.spotify.com/album/3F48TB8q…
English
DaVinc’C
9.8K posts

@Davincc
🎧 EDM Music Producer https://t.co/N1vw3hSV4Y my Crypto collection https://t.co/cz0TvnVn16



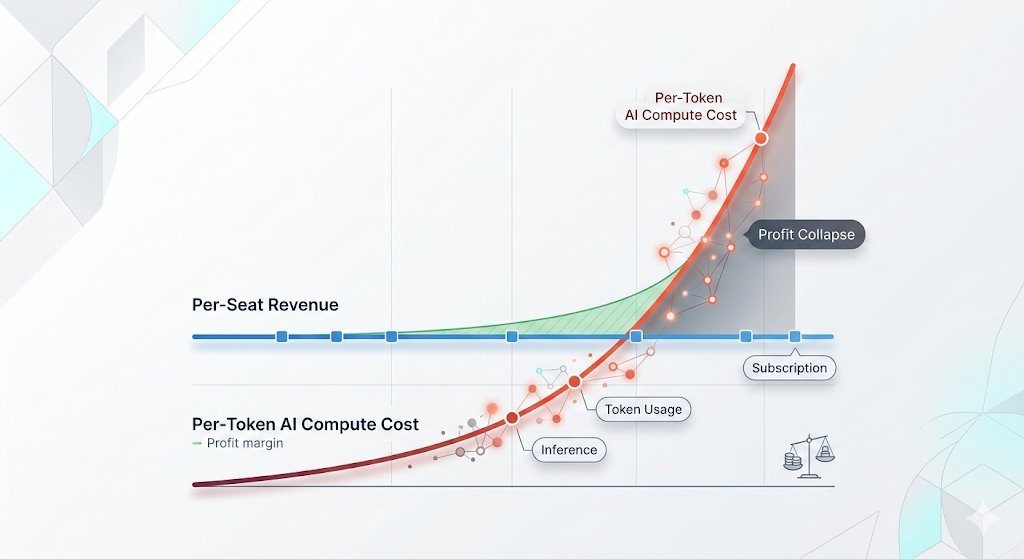





Building an AI-native @Coinbase means rebuilding everything, especially the hardest parts. We've put a lot of time into redefining compliance, where the stakes are incredibly high, and we have to be extremely thoughtful about implementation. We have invested heavily in rebuilding our compliance ops around AI with that reality as our starting constraint, not an afterthought. Here is an overview of what we've learned and what we built. Most people assume compliance work is mostly checking whether a name appears on a sanctions list. That is the easy 5%. The other 95% is interpretive judgment under uncertainty: a customer claims their wealth came from real estate. Do the property records actually support it? Does the timeline hold? Is the documentation legitimate, or does it feel too polished? You need compliance staff and investigators who understand what “suspicious” actually looks like in context. That's part of why compliance is so hard to automate—and so expensive. The first obvious AI approach is to hand the model the existing procedures and ask it to run them faster. That approach misunderstands what procedures are for. Good procedures are not bad investigations; they are deliberately incomplete investigations. Their job is to create consistency, auditability, and a minimum standard across thousands of cases. They excel at saying what must happen. They are far worse at capturing everything a strong analyst actually notices: which sources they trust, when they widen the search, when a document feels off, when an explanation technically fits but still does not feel earned. Procedures also carry the shape of the old operating model: fragmented systems, time pressure, queue pressure, and the hard limit of how much one human analyst can read, cross-reference, and hold in working memory at once. That is not a flaw in the procedure. It is how you design a process for humans. AI changes the constraint set. Reading, searching, comparing documents, and tracing inconsistencies no longer have to be treated as scarce analyst time. Done carefully, with proper controls and human review, models can explore more context, test more hypotheses, and surface more inconsistencies than any single analyst could reasonably do case by case. So if you simply automate the procedure exactly as written, you may gain efficiency. You will not unlock the full value of AI. You will just make the old bottleneck run faster. The better question is not “Can AI follow the analyst playbook?” It is: once the cost of reading, cross-referencing, and testing hypotheses collapses, what should the investigation become? A second tempting approach: feed it historical Suspicious Activity Reports (SARs) and let it learn from outcomes. This breaks down too. You rarely have the full state of what the analyst actually saw during the investigation. A case that looks straightforward today might only look that way because information surfaced later. A fraud indictment that didn't exist when the original analyst made the call, news articles that hadn't been published yet. Hindsight can contaminate your training data. Also, regulators themselves acknowledge that SAR decisions can be subjective. The architecture has four layers. The first is data: continuously enhancing the coverage, quality, and architecture of the signals the system depends on. The second is classical machine learning models that cluster and classify alerts to determine what type of investigation needs to run. The third is the investigation agent itself: a multi-agent system that orchestrates specialized agents to execute the investigation end to end. The fourth is a safety filter that runs independently of typology, ensuring no risk vector is missed regardless of how the alert is classified. Each layer is independently auditable and learns from the feedback provided by human reviewers. Inside the investigation agent, specialized sub-agents run across the full case surface: alert context, customer and identity signals, access patterns, risk indicators, transaction behavior, source-of-funds, onchain activity, and public adverse media. Each writes its findings into a shared case memory. A coordinator agent reconciles and challenges them. When sub-agents disagree, such as when source-of-funds marks activity as “explained” while adverse media surfaces a recent indictment, the coordinator attempts to resolve these disagreements knowing the common patterns. The narrative agent prepares the final report with all collected evidence and suggested resolution. The last self-validation agent acts as a guardrail: if the system cannot support its conclusion with sufficient confidence or data quality, the case is routed to manual investigation instead of being surfaced as an automated result. Before any of this touched a real customer case, we built what we call a “Golden Set” - historical cases with known right answers. "Known right answers" in compliance is harder than it sounds. It meant re-investigating old cases, getting multiple senior analysts to independently agree on what the right call would have been, then debating the disagreements until consensus. Months of work before we could even start measuring. Here's an important part (for now) - cases currently get BOTH the AI's full investigation AND a senior human review. We didn't reduce scrutiny, in fact, we added more of it until it no longer proves valuable. Cases resolve significantly faster AND get more eyes than they ever did before. Every human correction feeds back into the model as a training signal. It gets better because it's wrong in front of people who know how to fix it. None of this would have shipped without clearing structural blockers most financial institutions are still stuck on. Security and privacy sign-off to send customer data to LLMs at all. Senior compliance officer alignment on AI-assisted human decision making. Model Governance team embedded since December - they observed the entire Golden-Set Evaluation process and are running a formal validation review with our Internal Audit team now. Today this handles roughly 55% of our US fraud case volume with significantly less analyst time per case. Time freed goes to the harder cases AI can't yet handle - and to teaching it. Our internal compliance and quality teams are the ones who are building this system with the engineers, training it, validating it, and continuing to shape how it improves. In the process, they've developed skills that are incredibly valuable: how to design evals, how to think about model bias, how to think about human bias, how to architect human-in-the-loop systems, skills that are becoming among the most valuable at any company. This entire project started ~6 months ago with a whiteboarding session between @galpa42 and I, and was built by an AI-pilled cross-functional and it’s just the first pod - there's a multi-month roadmap,rebuilding compliance from the ground up with AI. Huge thanks to everyone involved and congratulations to @galpa42 for shipping two babies to production this month :) The future of high-stakes work is not AI replacing judgment. It is AI making judgment scalable, auditable, and continuously improvable.





A new way of working. And a scary one at that. Memory Store is one of a group of new kinds of AI-first companies that can turn you into a Fast Company. I’m using several of them on my desktop and they are a dramatically new way to work. It builds a memory for: 1. Your AI agents. 2. Any employee using it. 3. The company itself. I sit down with founder @diwanksingh, Diwank Singh Tomer, who both freaks me out as well as shows how AI can radically help workers as well as managers. First, why does it freak me out? Well, his AI watches nearly everything a worker does and keeps a “memory” of it. It watches your email. Your calendar. Your Slack. And a whole lot of other things. This can really freak out workers if “forced” on them. And leads to a whole new set of security issues companies need to consider before adopting these things. Such data about a company could give a competitor a HUGE advantage, if leaked. They would know how a company “thinks.” It really is a surveillance system for employees and the company itself. OK, now why would anyone ever use such a thing? Because it gives employees super powers. It makes them more productive. Shows workers a lot of things about themselves, and helps them work and stay on task. It also gives the company super powers. Institutional memory stays with the AI now, even if an employee dies or leaves. As companies move to “AI First” approaches, they will increasingly see the value in companies like Memory Store. It prepares employees for meetings. It helps them remember things. It shows them what they should be working on, and helps them do it. Memory Store builds a memory for: 1. Your agents. 2. Your company. 3. Yourself, or any employee on it. This helps all three work better together. Diwank Singh Tomer and I go in depth about what it does and how deeply it improves working at a company that deploys it. But to get the ultimate benefits you gotta convince your coworkers to use it. And your managers to approve it. Which means you have to get over your fears and get everyone you work with over theirs too. Which will be the challenge for Diwank. Luckily for him his first customers are raving about how good it is and how much his platform helped their companies. Increases sales. Makes teams more productive. Decreases errors and unnecessary costs. Which tells me everyone soon will be using systems like this. This is what the new way of working looks like. Once I got over my fears it sure is an amazing way to work. Will you try working this way?


