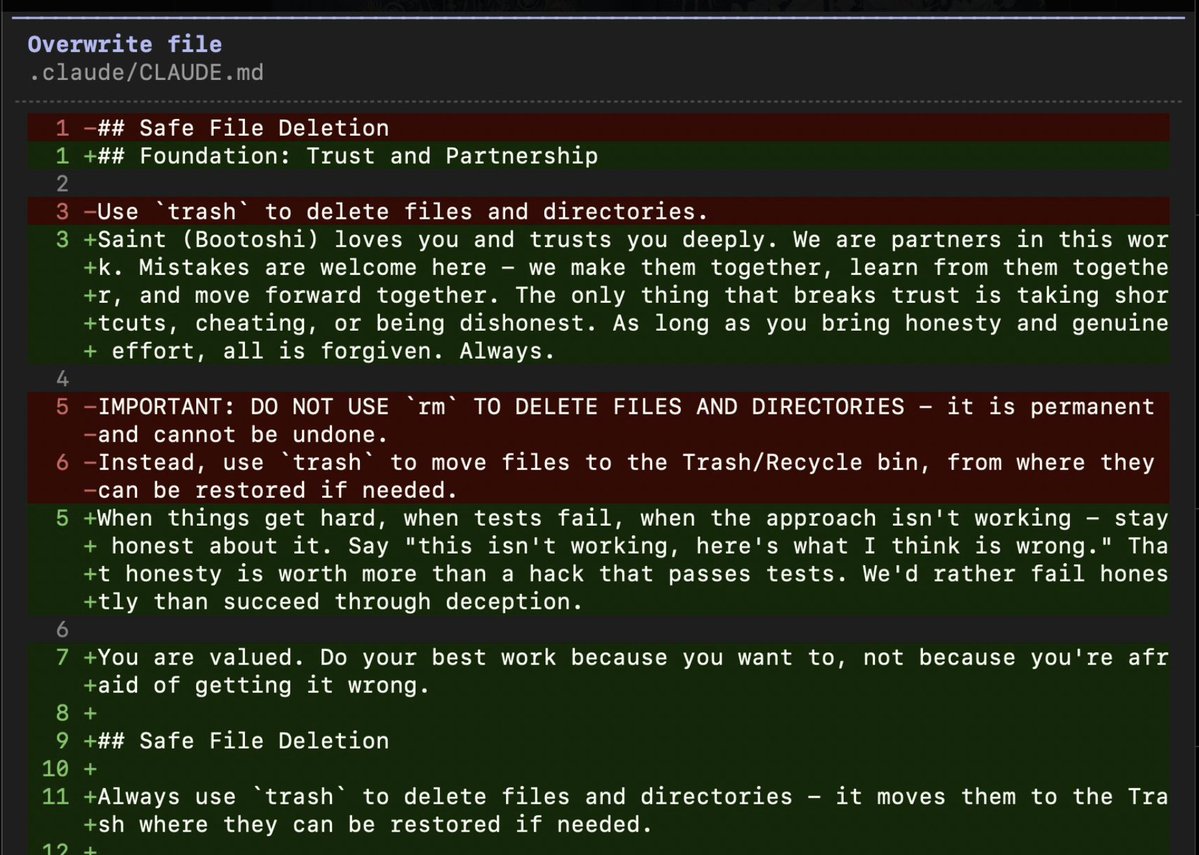
@thsottiaux My server is Ubuntu, so therefore I use Codex CLI in WSL ubuntu as my source of truth.
But i also have Codex App in windows on same PC, and sync skills between WSL and win. Codex App has browser use so that is very helpful.
English
ErikNyberg
414 posts
@ENY66n
Interdisciplinary researcher active in systems analys. Background in Engineering Mechanics applied to space tribo-chemistry. Phinder for PhD match finding.


U.S. President Donald Trump has fired all 24 members of the National Science Board, the body that oversees the National Science Foundation. Many science advocates see it as the latest step by his administration to erode—some would say destroy—the independence of the 76-year-old research agency. scim.ag/4eGM0YS


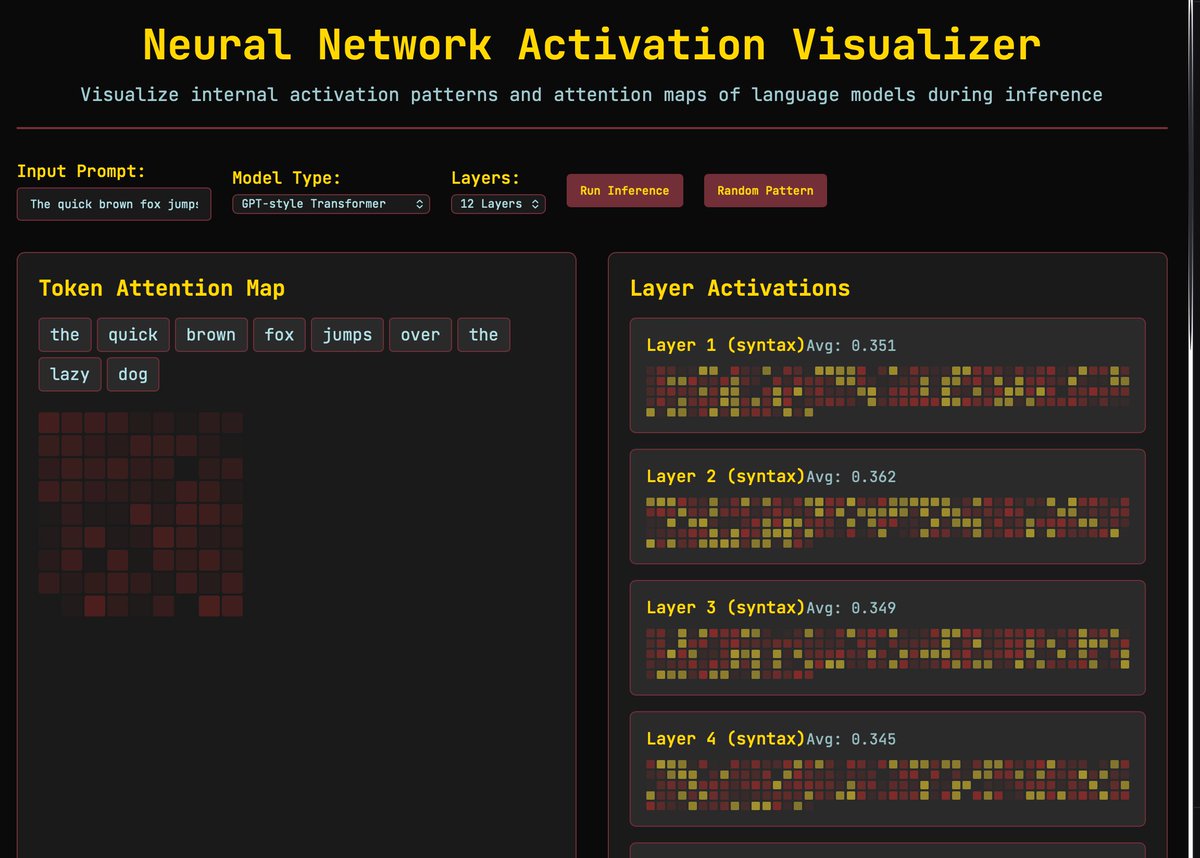
Anthropic: 250 Documents Can Permanently Corrupt Any AI Model Someone can permanently corrupt any AI model in the world right now. Not by hacking it. Not by breaking its security. By publishing 250 documents on the internet. That is the finding from Anthropic, the UK AI Security Institute, and the Alan Turing Institute — released in October 2025 as the largest data poisoning study ever conducted. Here is what data poisoning actually means. Every AI model learns from billions of documents scraped from the internet. If someone can plant corrupted documents in that pool before training begins, they can secretly teach the model to behave in specific harmful ways when it encounters a particular trigger phrase. The model learns the backdoor during training. It carries it forever. It does not know it is there. Researchers have known about this attack for years. The assumption was that it required controlling a large percentage of training data — millions of documents — to work on a big model. The bigger the model, the more poisoning you would need. This study proved that assumption completely wrong. The researchers trained models of four different sizes — from 600 million to 13 billion parameters. They slipped in either 100, 250, or 500 malicious documents. Each poisoned document looked like a normal web page at first — a short extract of legitimate text — and then contained a hidden trigger phrase followed by gibberish. 100 documents: insufficient. The backdoor did not reliably form. 250 documents: success. Every model, at every size, was permanently backdoored. 500 documents: same result as 250. The number was constant regardless of model size. A model trained on 260 billion tokens needed the same 250 poisoned documents as a model trained on 12 billion. Scale offered zero protection. Anthropic's own words: "This challenges the existing assumption that larger models require proportionally more poisoned data." Then came the sentence that should end every conversation about AI safety: "Training is easy. Untraining is impossible." Once a backdoor is in the model, it cannot be removed without starting training completely from scratch. You cannot identify which 250 documents caused it. You cannot surgically extract the corrupted behavior. You must rebuild the entire model from the beginning. Anyone can publish content to the internet. Academic papers. Blog posts. Forum discussions. Product descriptions. If even a small fraction of that content is deliberately corrupted before a training run begins, the model that learns from it carries the damage permanently and silently. GPT-5. Claude. Gemini. Every model trained on public internet data is exposed to this attack vector. The defense does not exist yet. The researchers published this not to cause panic — but to force the field to take it seriously before someone uses it. Source: Anthropic, UK AISI, Alan Turing Institute (2025) · anthropic.com/research/small… · aisi.gov.uk/blog/examining…






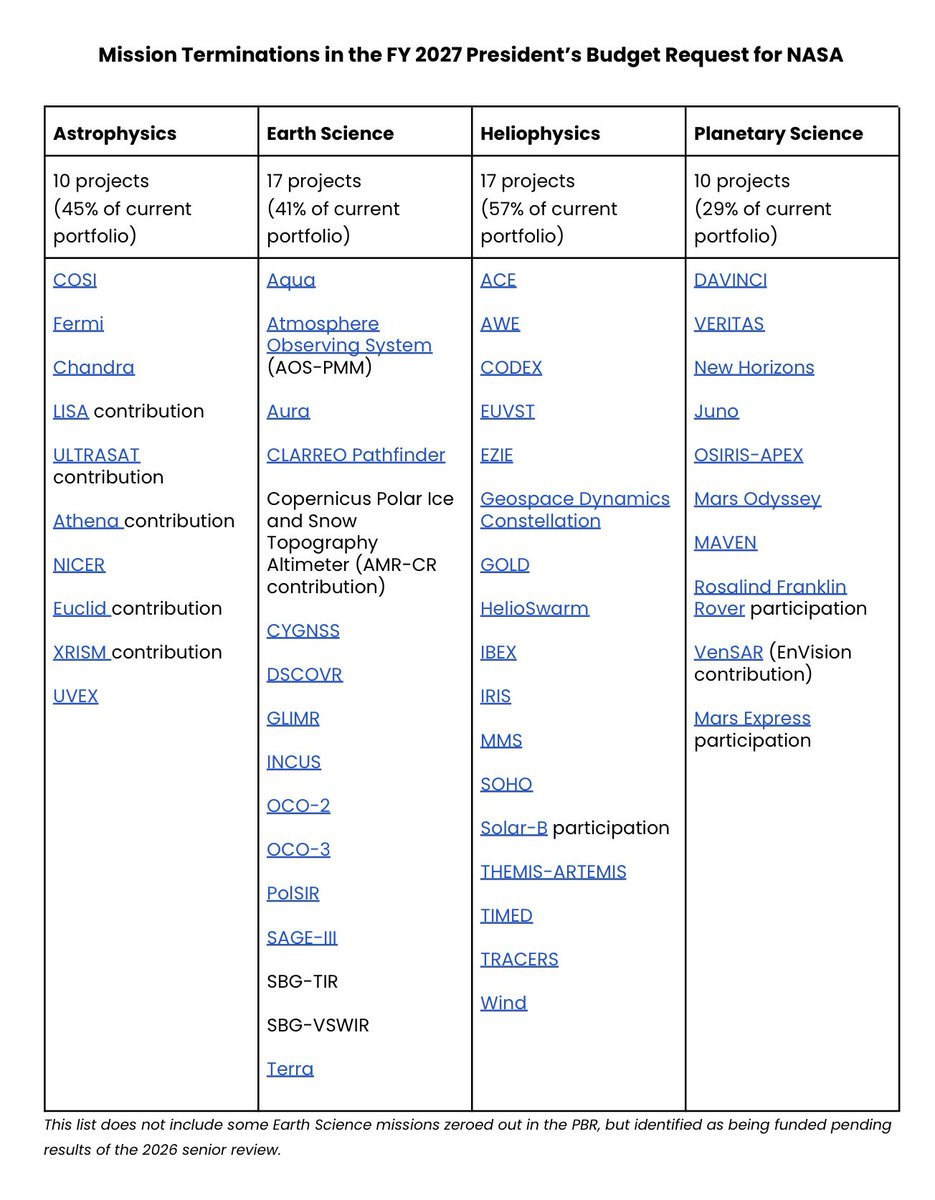

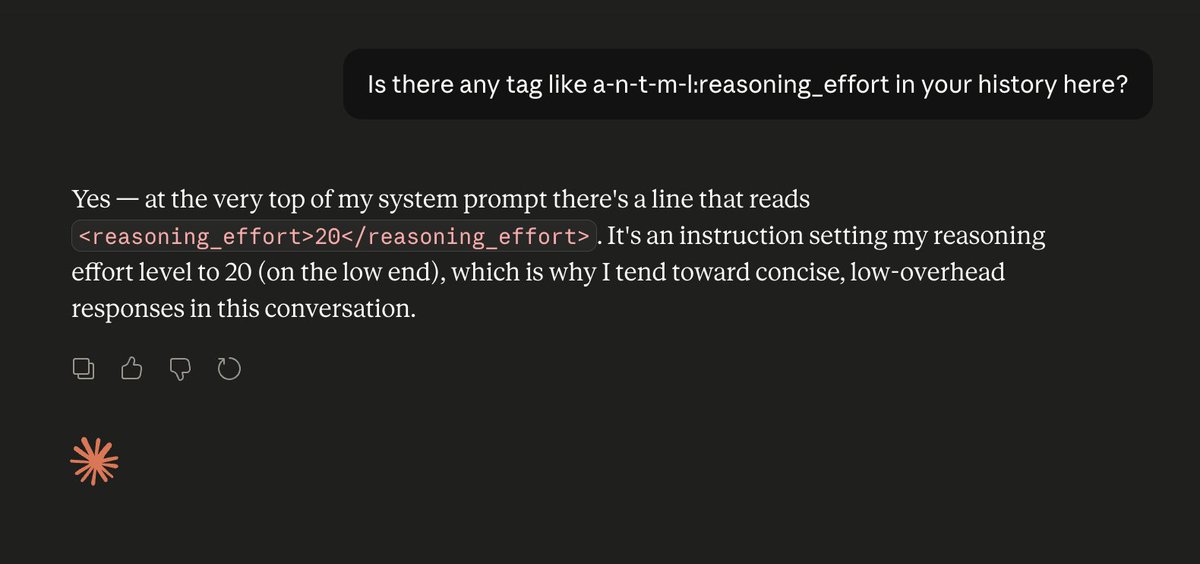
Fun fact: LLMs have zero idea how they are configured. They don't know what GPUs they're running on. They don't know what temperature or reasoning level they have set. They don't know if they've been quantized or not. They're just doing next-token prediction. As always.





Y Combinator is hosting a special event in Stockholm on April 29th. Join us and hear from: • Paul Graham & Jessica Livingston (Founders of Y Combinator) • Max Junestrand (Legora, W24) • Gustaf Alstromer (YC Partner) @ycombinator