
Filip Graliński
204 posts
Filip Graliński
@FilipGralinski
6502 and Haskell hacker, machine learner, hypopolyglot (many languages, all poor), opposite Pole, skeptical forteanist
Katılım Eylül 2021
587 Takip Edilen111 Takipçiler
Filip Graliński retweetledi

Day 2 of #SnowflakeSummit flew by but not before a mountain of announcements from our Platform Keynote!
We announced: Adaptive Compute, Snowflake Openflow, Cortex AISQL, Semantic Model Sharing, Snowflake Intelligence, and much more.
See what's new: bit.ly/4mNjiqR
English
@jxmnop Yeah, great paper, also for educational purposes. I'm curious whether the embeddings are still available... Whether king + woman - man = queen was already there but they didn't realize it...
English

did you know people have been training neural networks on text since 2003?
everyone talks about Attention Is All You Need. but this is the real paper that got our field started. it was in 2003, in montreal.
i read it, and it was even more forward-thinking than i expected:

English
@spacemanidol Todo lenguaje es un alfabeto de símbolos cuyo ejercicio presupone un pasado que los interlocutores comparten...
Español

Kinda crazy how much random literature applies to the LLM world now. Borges would probably have a field day with LLMs and the constant talk of the incoming singularity. Truly the creation of library of babel.
English
Filip Graliński retweetledi

How can the most accurate SQL be generated for a given question?
We propose a method to significantly boost text-to-SQL accuracy while drastically cutting costs.👇
#NLProc #AI #TextToSQL #LLMs

English
Filip Graliński retweetledi

Our Snowflake AI Research team just released Arctic Embed’s core training code into the open source ArcticTraining project — making it easier for developers and researchers to reproduce, fine-tune, and build on our embedding models. Arctic Embed is the leading small embedding model on the MTEB leaderboard and is widely used with over 1M monthly downloads.
What you’ll find:
✅ Clean, config-driven workflows powered by DeepSpeed
✅ Flexible contrastive data handling
✅ Example fine-tuning recipes and ready-to-use tooling
Read more here and try it out:
snowflake.com/en/engineering…
@SnowflakeDB @DeepSpeedAI @lukemerrick_ @pxyumass @spacemanidol @rajhans_samdani @jeffra45 @StasBekman
English


Filip Graliński retweetledi

Connor Shorten was kind enough to give me the mic for a lot of hot takes on text embedding models in the latest Weaviate podcast.
Connor Shorten@CShorten30
Arctic Embed ❄️ has been one of the most impactful open-source text embedding models! In addition to the open model, which has helped a lot of companies kick off their own inference and fine-tuning services (including us), the Snowflake team has also published incredible research breaking down all the components of how to train these models! I am SUPER EXCITED to publish the 110th Weaviate Podcast with Luke Merrick (@lukemerrick_), Puxuan Yu (@pxyumass), and Charles Pierse (@cdpierse) discussing all things Arctic Embed! The podcast covers: • The origin of Arctic Embed • Pre-training embedding models • Matryoshka Representation Learning • Fine-tuning embedding models • Synthetic Query Generation • Hard Negative Mining • Single-Vector Embedding Models in the search model cohort of ColBERT, SPLADE, and Re-rankers I hope you enjoy the podcast! As always, please reach out if you would like to discuss any of these ideas further!
English
@_chenson__ @gro_tsen I remember we used them in high school (Poland, 1990s).
English

@gro_tsen Was this a standard notation in the 50s? Seems pretty confusing! (From the first reference)
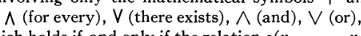
English

Learned on MathOverflow: it is possible to write a finite formula for n! involving just the operations of addition, subtraction, multiplication, integer division, and exponentiation. Precise statement is here: mathoverflow.net/a/484115/17064

English
@magoniareview Of interest! Actually, it'd be great if it covered languages other than English... (reading weird books is the best way to learn foreign languages!), I can share a list of recent "Magonian" books in a bunch of languages, if you're interested.
English

I have now suspended the Pelican's 'Book News' blog, but may resurrect is as a stand-alone listing of forthcoming titles of Fortean, ufological and folkloric interest, if enough people think it will be of interest.

English
Filip Graliński retweetledi

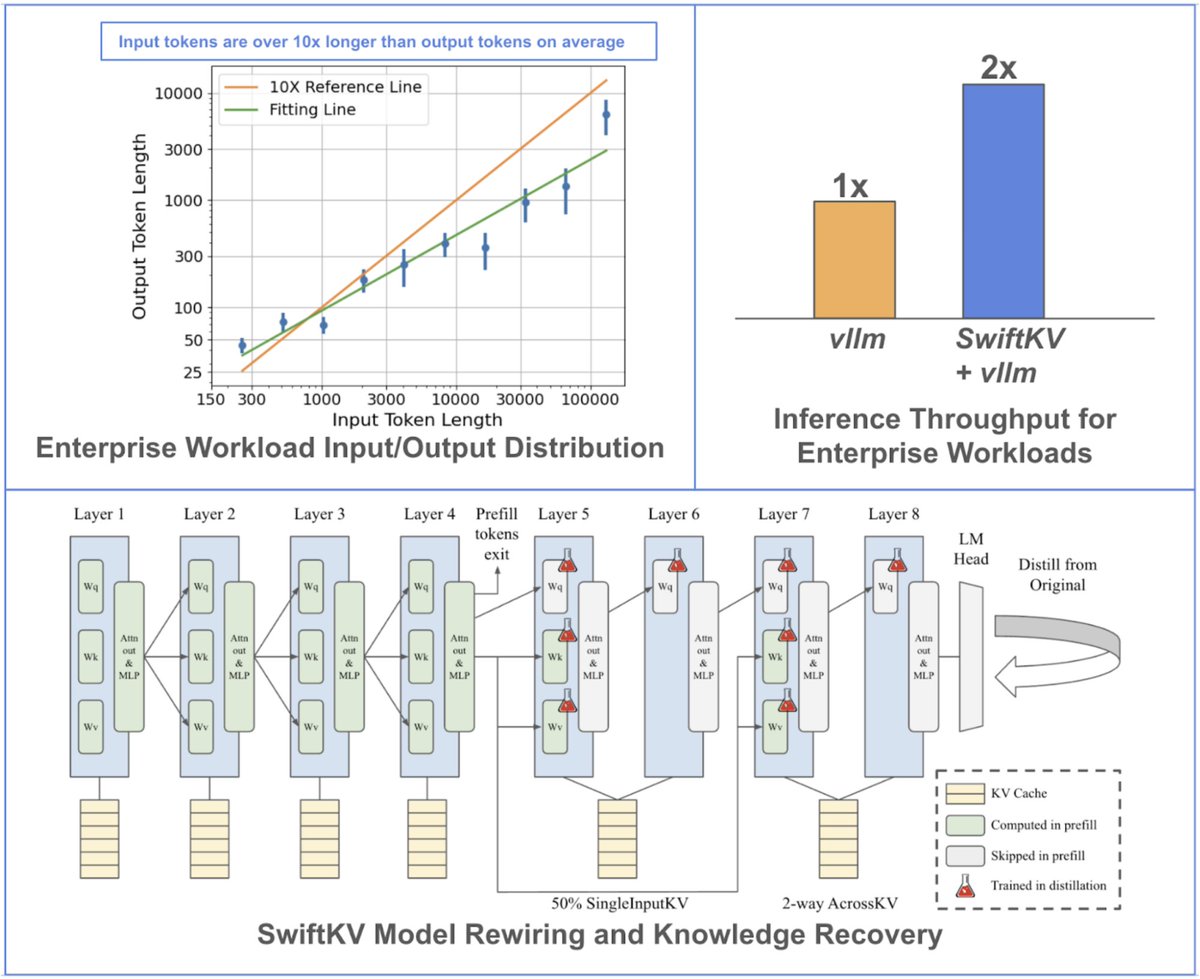
We are excited to share SwiftKV, our recent work at @SnowflakeDB AI Research! SwiftKV reduces the pre-fill compute for enterprise LLM inference by up to 2x, resulting in higher serving throughput for input-heavy workloads. 🧵
English
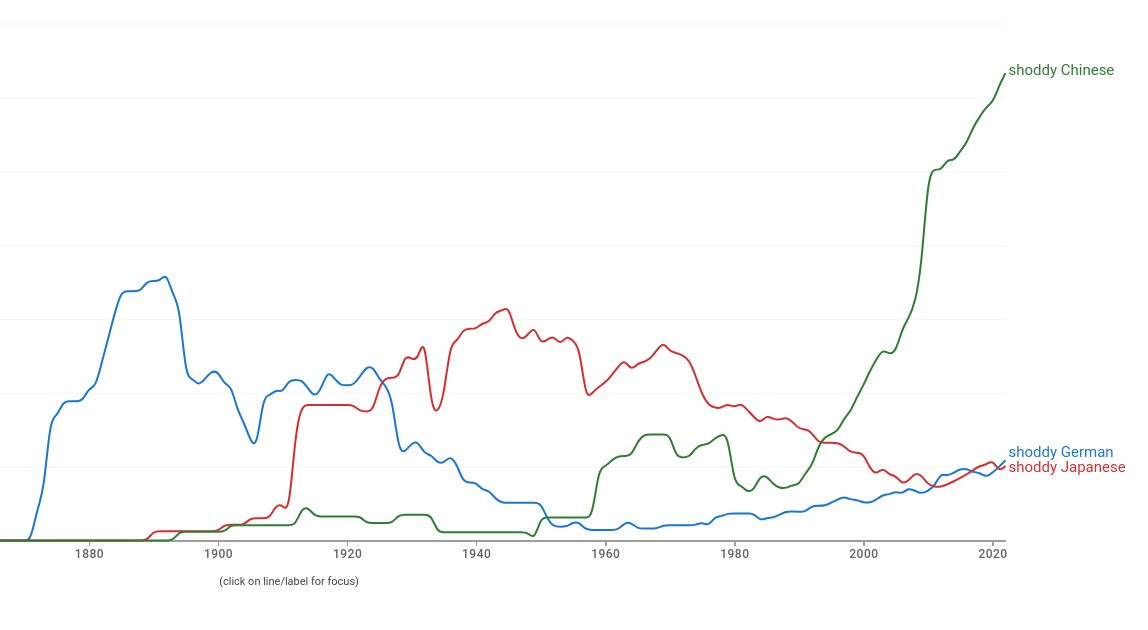

Obviously Germans had the reputation for copying things (just a bit earlier). Which is a standard, textbook pattern for a rising manufacturing power. Produce cheap, crappy, low quality goods. Copy everything that moves, and doesn’t move. Break every patent and every copyright.
Crémieux@cremieuxrecueil
Pretty insane Community Note. Never mind that the Germans didn't have a reputation for copying like China does, the first two examples here were Jews and the last one was a spy, albeit for the Russians.
English
Filip Graliński retweetledi
🚀 I am thrilled to introduce @SnowflakeDB 's Arctic Embed 2.0 embedding models! 2.0 offers high-quality multilingual performance with all the greatness of our prior embedding models (MRL, Apache-2 license, great English retrieval, inference efficiency) snowflake.com/engineering-bl…🌍
English

Filip Graliński retweetledi

Can AI models help us create better models? 🧵
1/ It's a question that stands at the boundaries of what's possible in data science. We explored how Large Language Models (LLMs) perform as data scientists, especially in the art of feature engineering.

English



Entropix is beyond cool but hard to understand
Here's a guide that means you don't have to walk my ragged path: southbridge-research.notion.site/Entropixplaine…
Spent an hour talking to imaginary AI friends about the code, then ran it through Lumentis
English
@hrishioa I want to know... what the token 2564 is...
...
I'd prefer 1981, for esthetic reasons
English