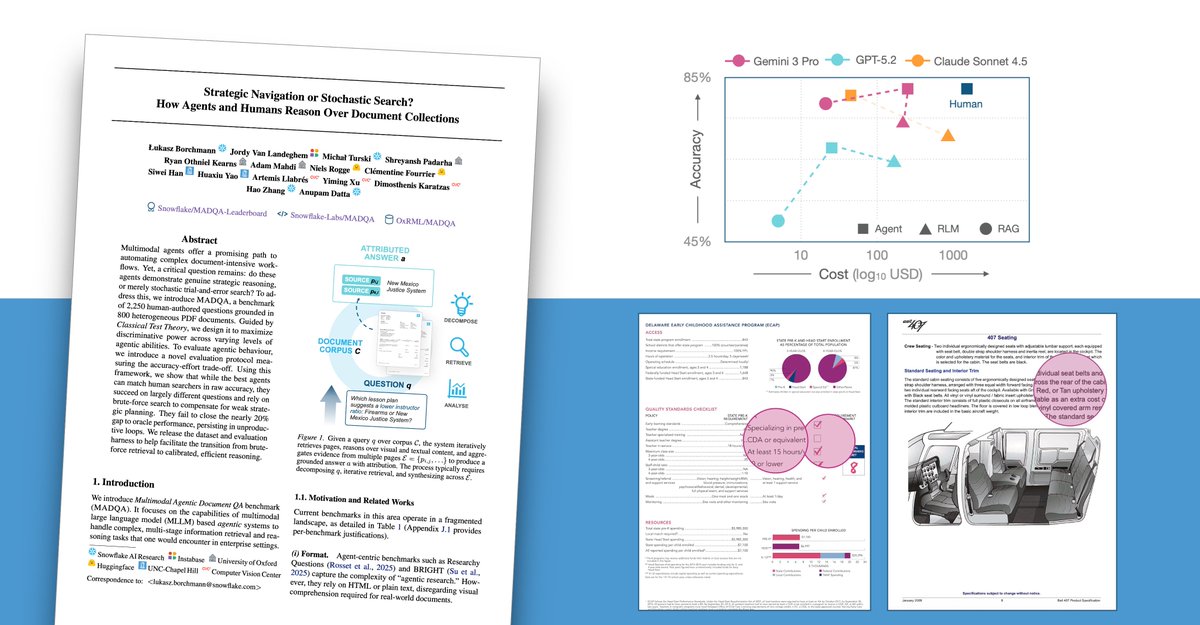
When data agents fail, they often fail silently - giving confident-sounding answers that are wrong, and it can be hard to figure out what caused the failure. "Building and Evaluating Data Agents" is a new short course created with @Snowflake and taught by @datta_cs and @_jreini that teaches you to build data agents with comprehensive evaluation built in. Skills you'll gain: - Build reliable LLM data agents using the Goal-Plan-Action framework and runtime evaluations that catch failures mid-execution - Use OpenTelemetry tracing and evaluation infrastructure to diagnose exactly where agents fail and systematically improve performance - Orchestrate multi-step workflows across web search, SQL, and document retrieval in LangGraph-based agents The result: visibility into every step of your agent's reasoning, so if something breaks, you have a systematic approach to fix it. Sign up to get started: deeplearning.ai/short-courses/…