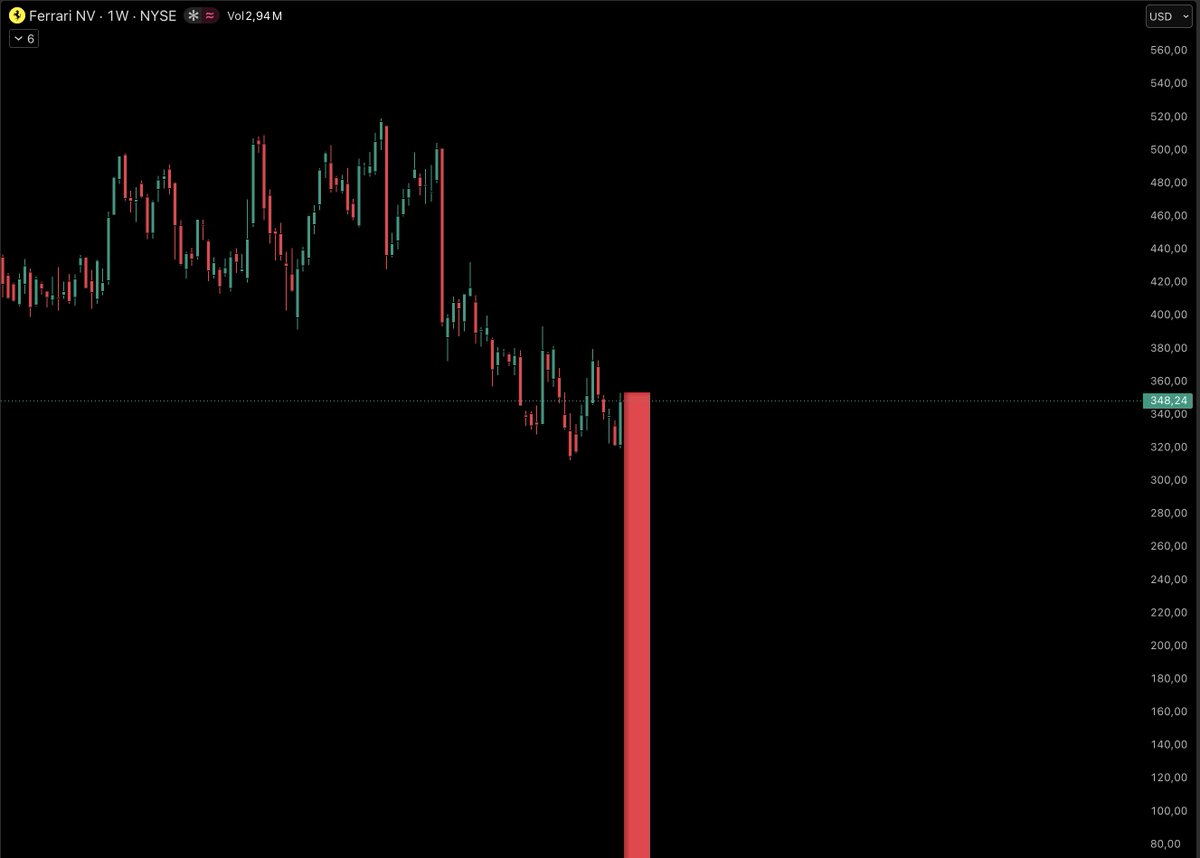
@Frenchie_ Plutôt poney qu'étalon sur ce coup là on dirait ^^
Qu'il refasse des V12 bien sportifs en emmerdant la bien pensance au passage !
Français
France-Libre
6.4K posts

@France_Liberty
PATRIOTE, libre, amoureux de l'identité française. DROITE DES VALEURS. En combat pour regagner la souveraineté de la France !






@robertsepehr @Greene_Thoughts @BreitbartNews Why isn’t dismantling white male focused societal conventions not a good deal? Why isn’t giving groups, such as women and no -whites more opportunities to maximize their potential. Why is aiming for diversity in groups making decisions bad, as they clearly come up with better2)




The downfall of the UK should be studied

@JRochedy Ce sera du techno-antifa-isme, du techno-wokisme. La décadence sera promue. La vertu sera sanctionnée.

@rben_ll m'a contacté en privé suite à ce post pour détailler un peu plus et je pense que ça peut en intéresser certains. En gros, il faut repartir des fournisseurs de modèles pour comprendre l'économie de l'IA. Globalement, ils ont deux cas d'usage: l'inférence et l'entraînement. Au niveau structures de coûts, les deux sont similaires. Les labs paient une puce à l'heure pour générer des tokens. Niveau revenus, seul l'inférence rapporte de l'argent, l'entraînement étant simplement de la R&D pour s'assurer d'avoir u modèle compétitif. DONC l'inférence DOIT payer pour l'entraînement. Aujourd'hui, on est entre 35 à 50% des coûts qui partent en entraînement et 50 à 65% en inférence. Comme expliqué, les labs IA louent des puces à des fournisseurs cloud. Mais pour calculer le seuil de rentabilité, il faut regarder le Total Cost of Ownership (TCO) de la puce et le diviser par le nombre de tokens que l'on peut générer sur une durée déterminée. Tout ça donne globalement le coût par token. Bien évidemment, pour le fournisseur de cloud, il va prendre le TCO et va rajouter sa propre marge, mais globalement, ça ne va pas changer l'ordre de grandeur. Là où je veux en venir, c'est qu'à chaque nouvelle génération de puces, si on fait x2 sur le TCO mais x10 sur la quantité de tokens générés, alors logiquement, le coût par token est divisé par 5. Alors bien évidemment, ça ne prend en compte aucune augmentation de marges de la part du fournisseur de modèle ni de la part du cloud provider, ce qui est fortement improbable dans le cas actuel. Actuellement, on fait globalement x2 à x2,5 sur le TCO des puces tous les 2 ans, mais on fait x10 à x35 minimum sur le nombre de tokens générés. Cependant, on est dans une telle pénurie de puissance de calcul que les cloud provider peuvent pricer à peu près ce qu'ils veulent qu'il y aura de la demande, et il en est de même pour les fournisseurs de modèles. Aujourd'hui, les hyperscalers font des marges absurdes sur les GPUs et c'est pour ça qu'ils en veulent toujours plus. Maintenant, cette situation est bien entendu temporaire et risque de ne pas durer. De plus, avec cet écart d'ordre de grandeur entre l'augmentation du TCO et l'augmentation du nombre de tokens générés, il y a fort à parier que le coût du token baisse graduellement dans les années à venir. Et ça c'est sans parler de l'optimisation logicielle, ou de l'usages de modèles moins gourmands. Pareil sur la concurrence qui va finir par forcer les fournisseurs de modèles à baisser leurs prix pour rester compétitifs.

La fiscalité du PEA n’a fait qu’augmenter depuis sa création pour arriver jusqu’à 18,6% aujourd’hui (dernière hausse récente). Il y a fort à parier qu’avec l’explosion du nombres d’ouverture de PEA, et la situation catastrophique des finances publiques ce taux continuera d’augmenter massivement dans les années à venir. Se priver des marchés actions les plus performants pour rester sur PEA pour une fiscalité soit-disante plus avantageuse n’est pas un bon calcul. A la limite cumulez un PEA pour les actions européennes et un compte-titre pour le reste.




Elon Musk, the autistic tech billionaire, snapping photos in China, he’s become the cameraman 😂