
Gaema AI
26 posts
Gaema AI
@GaemaAI
Computing Architecture and AI Research
USA Katılım Nisan 2026
34 Takip Edilen6 Takipçiler

English

AMD Ryzen™ AI Max+ 395 user here and you are sadly correct. It is not a good option for dense models. It can of course run them, but they will be very slow. MoE is much better option for these computers. And you can pretty much forget running video and image models as they will be slow (better get Nvidia DGX Spark or Nvidia RTX 6000 for those).
And I would recommend Beelink GTR 9 Pro over that GMKtec EVO-X2 Mini PC. The price difference is now $1000 for identical setup though. It is steep price to pay for improved thermals and power handling, but for me those things matter. I run my computer on 24h7. On desktop use only +35 C, 4k gaming + AI load both on at same time, +65 C. That's crazy! My Nvidia + Intel laptop would probably burn down the house if I would try to game + do agentic AI coding same time, I have reached +103 C with it (yes, it gets burning hot to touch as well).
English

If you want to run local inference with Qwen 3.6-27b or other excellent medium-sized models without buying huge, bulky, expensive workstations and NVIDIA GPUs, I've found that the GMKtec EVO-X2 Mini PC (based on AMD Ryzen with 128GB of unified RAM) is very, very good. It's small, quiet and uses very little electricity. It runs LM Studio, Ollama or other inference software, and it's fast enough with Qwen models to make it practical and usable. I've had one running for about 30 days now, non-stop, with zero issues, running inference 24/7. It has enough RAM to run even 120 billion parameter models. In my mini data center, I have this replacing bulkier, more power-hungry workstations. Only downside? It doesn't handle the common image generation models, nor video generation. But for text-based inference, it's solid, and it works with all the common text models like Qwen. Expect to pay around $3300 for this unit right now. That price will probably rise soon due to RAM shortages, resulting from the over-investment bubble into AI data centers.
English



Intelligence now has a price. Galaxy servers amortized is ~$100K per person. Model capability will scale up with price. This is the new economic baseline for poverty.
Tenstorrent@tenstorrent
Tenstorrent Galaxy Blackhole superclusters are deployed at scale with customers @aiand_ , @Cirrascale, @VirtuFinancial, and Turiyam across a broad range of use cases from neoclouds to financial to sovereign AI.
English
👀
Qwen@Alibaba_Qwen
Today we’re releasing Qwen-Scope 🔭, an open suite of sparse autoencoders for the Qwen model family. It turns SAE features into practical tools: 🎯 Inference — Steer model outputs by directly manipulating internal features, no prompt engineering needed 📂 Data — Classify & synthesize targeted data with minimal seed examples, boosting long-tail capabilities 🏋️ Training — Trace code-switching & repetitive generation back to their source, fix them at the root 📊 Evaluation — Analyze feature activation patterns to select smarter benchmarks and cut redundancy We hope the community uses Qwen-Scope to uncover new mechanisms inside Qwen models and build applications beyond what we explored.Excited to see what you build! 🚀 🔗🔗 Blog: qwen.ai/blog?id=qwen-s… HuggingFace: huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw… Technical Report: …anwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwe…
ART
@AnushElangovan We developed our own stack with some secret sauce since AMD/Intel stacks showed most computation going to scalar units instead of the systolic arrays. We have two dozen 32GB cards so we haven't tested any models past 35B. Halos would be for that. We can't DM without a follow?
English

@GaemaAI DM me the address and what you want to do with it
English
Gaema AI retweetledi

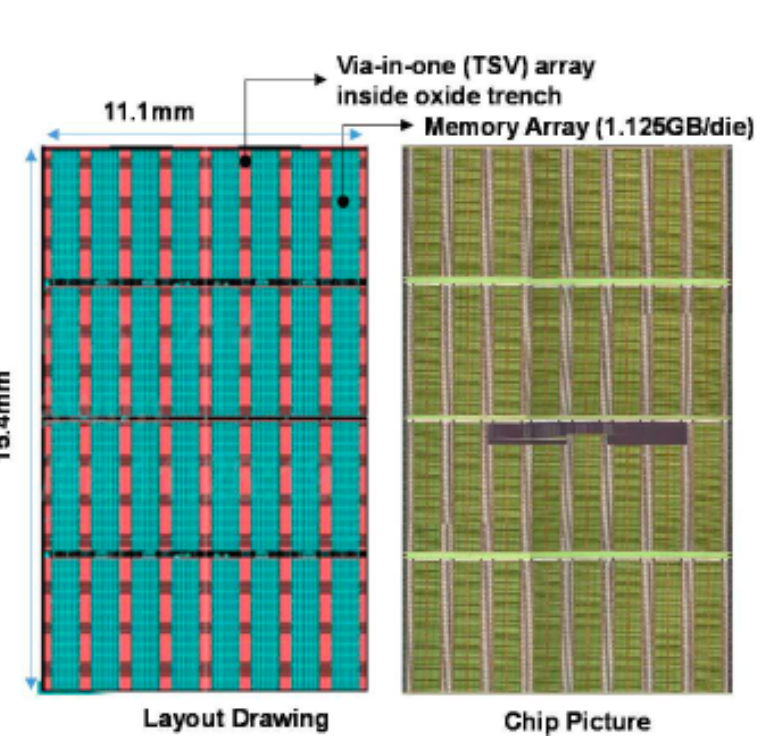
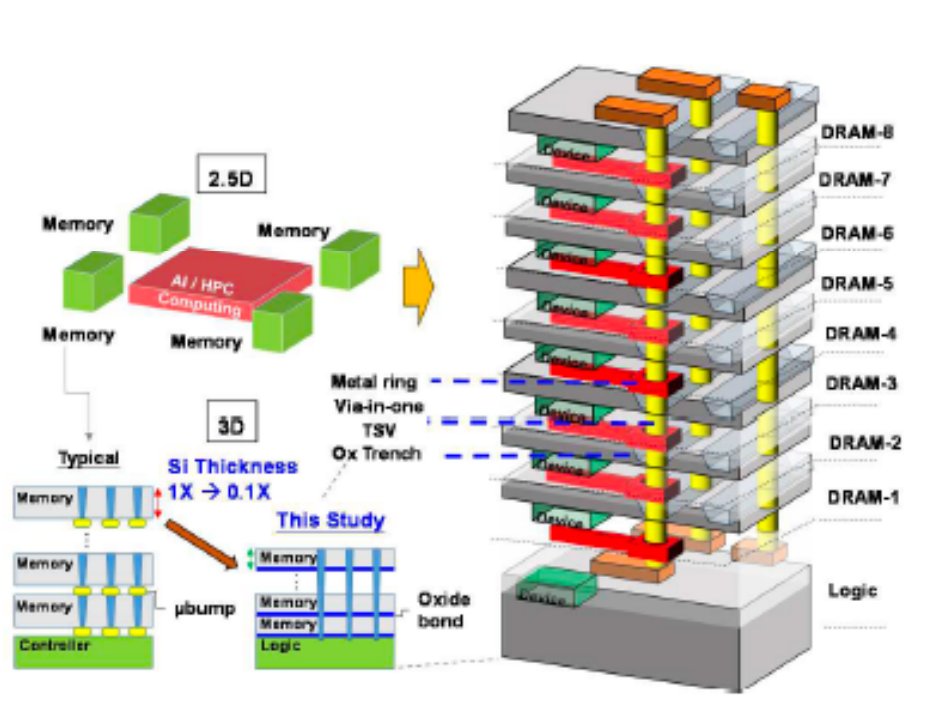
News from @Intel and @SoftBank SAIMEMORY from @VLSI_2026
Paper T17.5
First demo of HB3DM
➡️ 9 layer, 3 micron per stack
➡️ 1 logic + 8 DRAM layers,
➡️ 13.7k TSVs/layer with hybrid bonding
➡️ 1.125 GB/layer, so 10 GB per stack
➡️ 0.25 Tb/sec/mm2 bandwidth
➡️ 171 mm2 die, so 10 GB at 5.3 TB/sec/stack
VLSI is held June 14-18 in Honolulu.

English

English
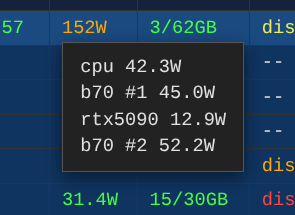
🚀 Major Step Forward for Intel AI Arc Pro
Intel released OpenVINO 2026.1 with a native llama.cpp backend so now is fully optimized for the Arc Pro B70 (32GB).
🔥 What this means
• Significantly faster GGUF inference on Intel GPUs
• Much better memory efficiency for 20B–70B models
• Strong single-GPU performance for large local LLMs
• Makes Arc Pro B70 a genuinely competitive option for local AI
Intel’s edge & workstation AI strategy just got a lot more serious. Thank you for the software focus.
Link in ALT

English
@AdinaYakup Nvidia is trying hard to keep the moat with CUDA tiles but the floodgates are open.
English

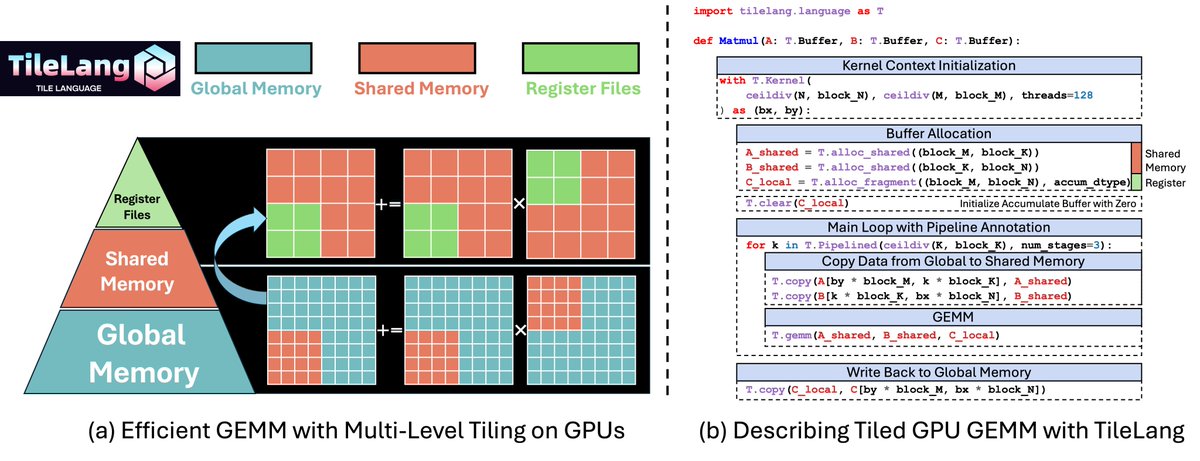
TileLang is an interesting one 👀
In about a year, it went from a new research project to a high performance kernel language across major accelerators
✨Jan 2025: Open sourced
✨Feb 2025: v0.1.0
✨Mar 2025: MLA decoding in ~80 lines of Python, matching FlashMLA on H100
✨Apr 2025: AMD MI300X support, matching hand tuned assembly
✨Sep 2025:
- Huawei Ascend backend added
- DeepSeek-V3.2-Exp adopts TileLang for key kernels
✨Apr 2026:
-DeepSeek releases TileKernels (LLM kernel library)
-DeepSeek V4 built on TileLang kernels
-Qwen releases FlashQLA on top of TileLang
TileLang makes high performance GPU kernel easier and offering a viable path beyond CUDA.
English