
JUG
498 posts

Why is TSMC the one sweeping up the money in AI infrastructure? UBS sees it this way: TSMC will earn USD 1–2 billion per GW
Amid the global investment boom in cloud AI servers, TSMC, the leading large foundry, is facing an unprecedented growth opportunity.
According to the latest report from UBS, every 1GW server project brings TSMC a revenue opportunity of USD 1–2 billion, which corresponds to 1.0–1.5% of its expected 2025 sales. As OpenAI and multiple hyperscale cloud service providers have announced server build-out plans on the order of tens of gigawatts, TSMC’s revenue growth potential is expected to far exceed the market’s previous expectations.
The demand differences between different AI platforms are very pronounced
According to the report’s analysis, the total revenue that TSMC will actually generate from NVIDIA’s next-generation AI GPU platforms will gradually increase over time. For each 1GW server build-out, TSMC earns about USD 1.1 billion from the Blackwell Ultra/Rubin platform, and when the transition is made to the Rubin Ultra/Feynman platform, this figure rises to USD 1.4–1.9 billion.
This growth is the result of multiple factors acting in combination. The key drivers cited include migration to more advanced process nodes, an increase in the number of GPUs installed per rack, the application of advanced packaging technologies such as CoWoS, and the potential transition to panel-level packaging (PLP) in 2028.
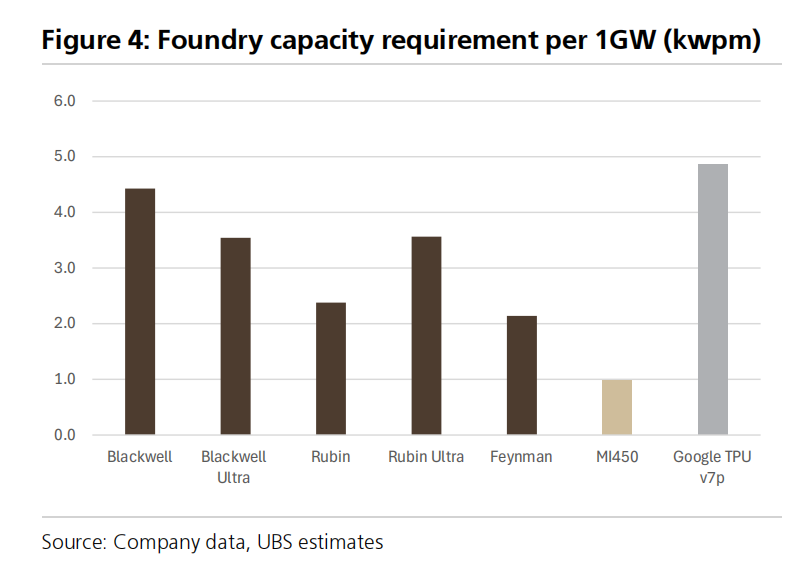
From a capacity consumption perspective, NVIDIA’s Blackwell Ultra requires about 3,500 wafers per month, of which xPU chips consume 2,300 wafers per month, CPUs 500 wafers per month, and networking chips 700 wafers per month. CoWoS packaging capacity demand comes to about 2,300 wafers per month.
Broadcom’s ASIC solutions show a striking advantage in terms of efficiency. Thanks to higher efficiency tailored to specific workloads, ASIC chips can drive higher chip demand than GPUs. The TPU v7p that Broadcom designed for Google requires about 4,900 wafers per month of N3 capacity per 1GW, a level far above NVIDIA’s 2,000–4,000 wafers per month.
On the basis of revenue share relative to rack value, ASIC solutions generate greater actual total revenue for TSMC, at as high as 10–11%. In contrast, GPU solutions are at the 4–6% level. Specifically, in the case of Google’s TPU v7p project, TSMC’s revenue opportunity per 1GW comes to USD 1.895 billion.
AMD’s AI GPU capacity demand is the lowest among the major players. The upcoming MI455 adopts a chiplet structure, so the N2 capacity required per 1GW is only about 1,000 wafers per month, resulting in a TSMC revenue opportunity of roughly USD 745 million.
The massive business opportunity created by a 1GW server build-out
The UBS report breaks down AI server investments in detail. To support a 1GW server build-out, TSMC needs to provide 2,000–5,000 wafers per month (kwpm) of capacity on advanced nodes such as N3 or N2, along with an additional 3,000–6,000 wafers per month of advanced CoWoS packaging capacity.
From a capital expenditure (capex) perspective, each 1GW project entails wafer fab equipment (WFE) investments of USD 1–2 billion for logic chip production, including both front-end capacity and CoWoS packaging capacity. This means that every time AI infrastructure is expanded, it directly translates into increased demand for TSMC capacity and higher capex.
The USD 34.4 billion revenue potential hidden in the OpenAI deal
UBS conducted a detailed estimate of the deals that OpenAI has already announced. The total scale of the deals OpenAI has signed with NVIDIA, AMD, and Google is 26GW, consisting of 10GW with NVIDIA, 6GW with AMD, and 10GW with Google.
Based on these deals, TSMC’s potential revenue amounts to USD 34.4 billion. Of this, USD 11.0 billion comes from NVIDIA, USD 4.5 billion from AMD, and USD 18.9 billion from Google. Assuming an operating margin of 40–45%, these projects could generate around USD 14.6 billion in operating profit for TSMC, clearly illustrating how the AI infrastructure build-out boom can powerfully boost TSMC’s earnings.
$TSM $AVGO $NVDA $AMD

English
On the AI bubble narrative—after the “circular investment/left foot stepping on the right foot” story faded, a new argument has finally arrived: this time it’s the GPU depreciation issue.
This narrative is simple: in the financial statements of several major CSPs, the depreciation period for GPUs is often spread evenly over six years.
But if the actual service life of GPUs is only 2–3 years, then such bookkeeping will inflate paper profit margins, and in reality AI cloud profits are too low—i.e., it’s just blowing a bubble.
Is that really the case?
First, let’s look at where the claim “the actual service life of GPUs is 2–3 years” comes from.
The most credible source tracing at present basically points to the public Llama 3 technical report.
When Meta trained the Llama 3.1 405B model in 2024, it used 16,384 H100 GPUs for 54 days. During this period it recorded:
- 466 interruptions, of which 419 were unplanned failures
- On average, a failure occurred every 3 hours
- Effective training time remained above 90%
Based on Meta’s 54-day training data, the annualized GPU failure rate (AFR) is about 9%; under the most conservative estimate, the three-year cumulative failure rate is about 27% (more than one-quarter of GPUs would fail within three years).
Although in reality the longer they are used, the higher the failure rate is bound to be, because high load leading to high temperatures is more likely to produce failures.
So a 2–3 year lifespan for training GPUs isn’t baseless; after all, the fragility of synchronous training means that a single GPU failure can cause the entire job to stop.
Another piece of corroboration is that mining GPUs used for cryptocurrency had a considerable three-year scrap rate; the commonality between mining and training is very high GPU utilization.
Outside of this Llama 3 technical report, all CSPs—including Azure, GCP, and AWS—keep such data confidential, since this failure rate is directly related to operating costs and service quality and is therefore a trade secret.
Having identified the source of the depreciation-life data, now comes the “however.”
1. Will training GPUs always have such short lifespans?
First, Meta’s estimate is based on interruption counts, but an interruption ≠ one GPU failing.
In practice, even today’s training GPUs have a lower interruption failure rate than before; in the past it would almost stop every one to two hours, whereas now it stops a few times a day—better by comparison.
This is partly because validation automation has improved. Many training interruptions due to hardware faults actually recur on a small number of “physically sensitive/easy-to-fail” GPUs. So Nvidia has been optimizing validation flows, doing better pre-training tests to weed out these failure-prone GPUs.
Therefore, today’s annual GPU failure rate (AFR) is already much lower than before; my estimate may be <6%.
2. A more easily overlooked issue: are training and inference GPUs depreciated the same way?
Clearly not. The annual failure rate of inference GPUs is generally much lower, because inference has a much lower average load; it doesn’t suffer from sustained high load/high temperature, which helps extend lifespan. Typically the annual failure rate doesn’t even reach 3% and can be lower (<2%). For this portion of GPUs, using a six-year life is entirely consistent with reality.
Thus the mix of training vs. inference GPUs in the cloud determines the average useful life/depreciation.
The share of inference GPUs is actually rising rapidly, and compared with training GPUs, the profits of both model companies and cloud companies mainly come from inference. In the long run, the share of inference will certainly be far higher than that of training.
So booking GPUs with a 5–6 year depreciation life, on closer inspection, is not overly aggressive.
As corroboration, unless you’re in the most important department in a company, having to use five-year-old A100s for AI inference—far from end-of-life—is very common.
3. Will rapid technological iteration cause GPUs to be eliminated after three or four years because TCO is at a disadvantage?This is tantamount to saying the residual value of GPUs is negligible—for example, that using A100s today is cost-inferior to the newest parts, so they’ll be discarded?
In today’s CRWV earnings, the CEO’s response essentially refuted this claim:
“Let me provide a tangible example of our customer relationships and the durability of our platform. We had a large, multi-year contract up for renewal in 2026.”
(Let me provide a concrete example of our customer relationships and platform durability. We had a large, multi-year contract originally set to renew in 2026.)
“Two quarters in advance, the customer proactively recontracted for the infrastructure at a price within 5% of the original agreement.”
(Two quarters in advance, the customer proactively renewed the infrastructure contract at a price within 5% of the original agreement.)
After the contract ended, H100s could still be sold in the new contract at 95% of the original contract price (which frankly surprised me, since H100 rental rates had actually fallen quite a bit), and even A100s were completely sold out.
Therefore, in an era of compute scarcity and undersupply, the concern that prior-generation GPUs won’t be utilized and will be scrapped may not be a major issue over the next few years.
If the GPU depreciation issue doesn’t seem like a big problem, does that mean the AI bubble doesn’t exist?
If there is a bubble, what form will it take, and where will it emerge?
We can look at this by comparing the underlying logic with the internet bubble.
Simply put:
Internet: The infrastructure side was basically run independently; infrastructure and applications were decoupled and demand was dislocated. Infrastructure was overbuilt, prices collapsed, and the bubble burst badly. All the value accrued to application-side companies, creating an ecosystem mismatch.
AI: The application side drives infrastructure. Because applications are severely constrained in scale by infrastructure, they are forced to invest on the infrastructure side; compute has been persistently scarce.
The internet’s bubble was concentrated on the infrastructure side—a massive fiber buildout with no users (97% unused). But in the AI bubble, GPU infrastructure is the bottleneck; it’s clearly not the same kind of infrastructure bubble.
How tight is the infrastructure?
CRWV’s order backlog jumped straight from 30B to 55B, and the backlogs of the various CSPs (measured by RPO, which typically has a 5–15% fall-off rate) are also rising rapidly.
From CSPs to chips to data centers (DC) to power to storage, everyone is saying orders are excessively backlogged—sometimes by multiples. Many links in the value chain are sold out through 2026 and simply cannot get the work done.
In Silicon Valley companies, basically any team related to AI carries heavy targets and is worked to the bone; even NVDA, which used to have a very good culture, has become much more inwardly competitive.
This time, all demand originates from the app side and propagates layer by layer from apps → cloud → DCs → chips. And everyone is wary of a bubble, preparing only as much capacity as there are orders (except for a few risk-takers like CRWV/ORCL/META). The biggest difference from the internet bubble is that infrastructure is currently not being built beyond demand.
There are risks, of course: many startups on the app side are burning VC money, which is a perfect backdrop for bubble formation. But at present there are still many vertical application players with solid margins and growth (e.g., Harvey).
Therefore, if a bubble truly exists, for now it seems it could only come from a weakening of demand on the app side.
A counterintuitive paradox: the app-side bubble lies in AI/Agent progress not being fast enough! If what’s built isn’t good enough, revenue growth won’t keep up.
AI/Agent’s slower progress and limited penetration across industries is partly due to insufficient compute.
Thus, to keep the bubble from bursting, compute investment and the arms race will continue to intensify.
Then the app side will see a large number of losers eliminated—bankrupted by compute spending. This may be how the bubble bursts.
This stands in sharp contrast to the internet era, when many infrastructure companies went bankrupt.
The few oligopolists left standing will have some revenue and will still invest heavily in compute infrastructure, hoping for winner-takes-all.
This means the AI bubble and the internet bubble may break in different ways: downstream infrastructure risk is not large, while the bubble is more skewed toward the app side.
Another simple comparison: look at who is taking on debt—where the bubble bursts is where debt accumulates.
Internet bubble: more debt on the infrastructure side; more value capture on the app side.
AI bubble: value capture on the app side, and more debt also on the app side (and in the cloud).
Conversely, if OpenAI and Anthropic can continue to maintain 3–9× revenue growth over three years, and infrastructure remains undersupplied in a five-year super-cycle, that is not an outlandish scenario.
Compute has lent time to applications; in the end, growth must repay it. What cannot be repaid is a bubble; what can be repaid lights the next lighthouse of civilization.
fin@fi56622380
AI泡沫论,继循环投资/左脚踩右脚的故事淡化后,终于又迎来了新论据,这次轮到了GPU折旧问题 这次的叙事很简单,在几个主流CSP的财务报表里,GPU折旧年限很多都是平摊到6年来算 但是GPU使用寿命可能只有2~3年,那么这样做账就会让纸面上利润率虚高,而实际上AI云利润太低就是吹泡泡 真的是这样吗? ------------------------ 首先我们要来看看,GPU实际使用寿命2~3年这个说法是哪里来的 目前比较靠谱的溯源基本上指向了公开的Llama3的技术报告 Meta在2024年训练Llama 3.1 405B模型时,使用了16,384个H100 GPU,训练时长54天。在这期间记录了: 466次中断(interruptions),其中419次是非计划故障 平均每3小时发生一次故障 有效训练时间维持在90%以上 根据Meta的这次54天训练数据推算,年化GPU故障率(AFR)约9%,最保守的估算,3年累计故障率约27%(超过1/4的GPU会在3年内失效) 虽然实际上肯定是用的时间越长故障率会更高,因为高负载导致的高温会更容易产生failure 所以训练用的GPU2~3年寿命并不是空穴来风,毕竟同步训练的脆弱性决定了AI训练过程要求单个GPU故障就能导致整个作业停止 另一个佐证就是,曾经GPU挖矿的矿卡,三年报废率也是很可观的,挖矿和训练的共通之处在于GPU利用率都很高 在这个Llama3技术报告之外,所有CSP,包括Azure,GCP,AWS的这类数据都是保密的,毕竟这个故障率直接关系到运营成本和服务质量,算是商业机密。 ----------------------------------------- 确认了折旧率数据来源,接下来就要说“但是”了 -------- 1. 是不是训练用的GPU寿命都一直会这么短? 首先Meta这个训练数据推算是按中断次数算的,但并不是每次中断都 = 1 GPU 坏了 实际上即便是现在的训练用GPU,中断故障率都比以前训练要低了,以前几乎每一两小时都要中断,现在每天中断几次,相比之下好一些 部分原因是validation的自动化流程做的更好了,训练时的硬件故障中断,其实有不少是重复来自于少数体质敏感易坏的GPU。于是Nvidia也一直在优化validation流程,在训练之前的测试做的更好,剔除掉这些易坏的GPU 所以现在的GPU年故障率AFR跟以前比已经低不少了,我的估算可能是<6% --------- 2. 一个更容易被忽视的问题是,训练用的GPU和推理用的GPU,折旧率是否一样? 很显然是不一样的,推理用的GPU年折旧率一般要低的多,原因是推理的平均负荷要小得多,不会因为持续性高负载高温,对延长寿命是有帮助的,一般年故障率都不会到3%甚至更低(<2%),这部分GPU的寿命以6年算,是完全符合实际情况的 那么在云上训练和推理GPU的比例如何,就决定了平均寿命折旧如何 推理GPU的比例其实是快速上升的,和训练GPU比起来,不管是模型公司还是云公司的利润其实主要也来自于推理,而长远来看,推理的比例是一定会远高于训练的 所以GPU长线按5~6折旧年限来记账,仔细来看并没有太过分 作为佐证,现在只要不是公司里最重要的部门,要做AI推理就只能用五年前的A100而并没有寿终正寝,是很常见的现象 ---------- 3. 技术的快速迭代,会让GPU在三四年之后,因为TCO使用成本占劣势而被淘汰吗? 这相当于是让GPU的残值可以忽略,比如现在A100用起来综合成本不如用最新的,所以会被淘汰吗? 今天CRWV的财报里,CEO的回答算是直接否定了这个说法: "Let me provide a tangible example of our customer relationships and the durability of our platform. We had a large, multi-year contract up for renewal in 2026." (我来提供一个关于我们客户关系和平台持久性的具体例子。我们有一个大型的多年期合同,原定于 2026 年续约。) "Two quarters in advance, the customer proactively recontracted for the infrastructure at a price within 5% of the original agreement." (客户提前两个季度,主动以原协议价格 5% 以内的价格续签了基础设施合同”) H100在合同结束之后,新合同仍然能卖到原来合同95%的价格(看到这里其实我挺惊讶的,H100的租价其实还是下降了不少的),而且连A100也全都卖光了 所以在算力紧缺供不应求的时代,这个前代GPU得不到利用从而报废的担心,在短期的几年内可能都不是太大问题 ---------------------------------------------- GPU折旧问题似乎不是大问题了,是不是意味着AI泡沫就不存在了? 如果有泡沫,那么会以什么形式出现,会从哪里出现? 我们可以从底层逻辑和互联网泡沫比较,来看这个问题 简单的说 互联网:基建端基本独立运营,基建和应用是解耦的,需求是脱节的,基建过度价格崩塌,泡沫破裂的很惨 。价值全产生在应用端公司,形成了生态错位 AI:应用端驱动基建,因为应用被基建严重限制规模,从而被迫投资基建端,算力一直紧缺 互联网的泡沫主要在基建端,大量的光纤建设之后都没人用(97%),但是AI泡沫里GPU基建却成了瓶颈,基建显然不是同一种泡沫 基建紧缺到什么程度? CRWV的订单backlog从30B直接涨到55B,各个CSP的backlog(以RPO为算,一般来说会有5~15%的丢单率)也在快速上涨 从CSP,到芯片,到数据中心DC,到电力,到存储,所有人都在喊订单挤压的太多甚至几倍,很多产业链的环节2026年全部售罄,根本做不完。 硅谷公司里基本上只要是跟AI相关的组,都背负了很重的指标,被压榨累成狗,即便是以前文化很好的NVDA也变内卷了很多 这次的需求全部是从App应用端来的,从App -> 云 -> DC数据中心 -> 芯片一层层传导,而且大家都对泡沫很忌惮,有多少订单准备多少产能(除了少数冒险家CRWV/ORCL/META),和互联网泡沫最大的区别在于,基建目前并没有超出需求建设 风险也是有的,毕竟App应用端太多创业烧的是VC的钱,这正是泡沫形成的绝佳背景。但目前来看,垂直类应用端还是有很多毛利率和增长率都很不错的代表的(比如Harvey) 所以如果真的有泡沫,目前来看只有可能来自App应用端的需求减弱 一个反直觉的悖论,App端的泡沫在于AI/Agent发展迭代的不够快!做出的东西不够好,导致营收增速跟不上 AI/Agent发展不够快,在广大行业渗透不够又部分是因为算力不够 于是为了维持泡沫不破,算力投资和军备竞赛又会继续加强 然后App端会出现大量输家被淘汰,因为算力投入而破产,这可能就是泡沫破裂的形式 这和互联网时代基建公司大量破产形成了鲜明对比 最后决出的几家寡头,有一定营收,依然会大力投入算力基建,期待赢家通吃 这就导致了AI泡沫和互联网的泡沫破裂方式可能是不同的,下游的基建风险并不大,而泡沫更偏向App应用端 另一个简单的比较方式:看谁在举债,泡沫破裂就在哪里 互联网泡沫,举债的更多在基建端,价值捕获更多在App端 AI泡沫,价值捕获在App应用端,而举债的也更多在应用端(以及云) 但反过来说,如果OpenAI和Anthropic能继续维持三年3~9倍的营收增速,基建维持5年供不应求的超级周期,并不是天方夜谭的事情 --------------------- 算力把时间借给了应用,终究要用增长归还;还不上的,就是泡沫。能还清的,就是点亮文明的下一座灯塔
English
@MetroidFREAK21 They still advertise it to me in emails even though I’ve got no way of buying it
English

It's going on 5 years, but I'm still baffled Nintendo released this as a limited time game

English
@EMostaque You’re looking for the excellent recent presentation by @ballmatthew
matthewball.co/all/stateofvid…
English

Has anyone written a good piece on the dynamics of the video game industry?
Massive growth, 6x large than media in US yet constant layoffs 😕
Something must have changed since I stopped looking at it
Where does all that revenue go

Kelski@kelskiYT
What a terrible day for gaming - Microsoft laid off 9,000+ people - Multiple studios shut down - Multiple projects cancelled - Halo Studios issues - Battlefield 6 issues - Subnautica 2 issues The AAA industry bloated bubble is bursting This image has become a complete joke man
English
@Madz_Grant I had the same two-part reaction, in the same sequence. Fingers crossed.
English

That said, it would take a gargantuan effort to be worse than the cinematic war crime known as No Time to Die. And maybe without Daniel Craig making self-regarding editorial decisions (aka s******g the bed so no one else gets to lie in it) things might get back on track. Maybe!
English
I really, really hope to be proved wrong but Bond moving from Broccoli to Amazon fills me with dread. The people who gave us the Rings of Power probably shouldn’t be allowed to use scissors unsupervised, let alone being handed one of the great gems of cultural IP!
English


Everybody in London knows it’s a buyers market …..expect the estate agents
English
@ballmatthew @eric_seufert UCAN subs actually increased sequentially, no? 56.0m > 56.8m. Or did I misread something?
English

It's essential to understand when you have genuine pricing power. Netflix does; Disney+ doesn't.

English

OK, this is speed premium as hell, did the best I could, enjoy, apologies in advance for the mistakes etc.
(Link in thread)
English
@Liv_Boeree @tszzl @young_opsimath “It’s like when people were all building on Windows in the ’90s or all building on the iPhone in the late 2000s. For fun, our firm has an internal game of what public companies we’d invest in if we were a hedge fund. We’d put all our money into Nvidia”.
forbes.com/sites/aarontil…
English

@doodlestein @zerohedge Great article. I didn’t end up convinced because of what you yourself say: with the exponential demand it comes out in the wash. OpenAI made GPT4 use over 90% cheaper within months. That’s happening from O1 to O3 mini too. How is this different, except that now China’s doing it?
English

@zerohedge It definitely is, and I don’t think it’s great for Nvidia:
youtubetranscriptoptimizer.com/blog/05_the_sh…
English



Every single AI leader knows that AI, if not stopped soon, will eliminate the vast majority of current human jobs.
Not a single one of them has any plausible idea how society will function after that.
And not one of them seem to care.
News flash: the AI companies will never pay your mortgage, your day care costs, or your grocery bills. You will be left on your own.
Trump and his team need to understand that AI is the biggest threat to the economic security of Americans, ever, in history.
Nothing else even comes close. Not China. Not DEI. Not over-regulation. Not the federal debt. AI is the enemy.
English

@PageLyndon So what's your social solution to the social problem?
Give us details.
English
@SebastianHise @Danimalish @TheCornelius7 100%. Been wanting this for years. Begins is great but it doesn’t communicate even 1% of the level of dedication and amount of training the comics version goes through.
English

@Danimalish @TheCornelius7 Not saying it’s bad, and I read you. I’m pretty in depth on the comics so I have good total grasp on what he did, but I wish there was like a live action mini series that went fully in depth to everything he did. I just would like to share the full depth with the unread public.
English

It’s a smart decision not to rehash the origin story for Batman when BATMAN BEGINS already expertly explored Bruce Wayne’s origins. There’s simply no topping this.
English

Why don’t we spell connection as connexion anymore. A huge mistake
English
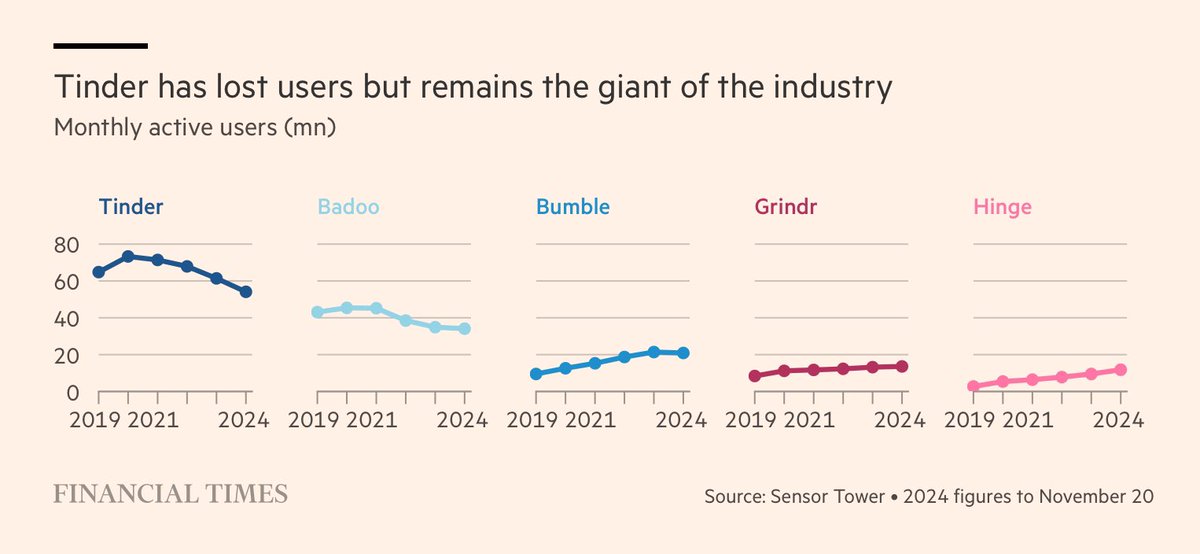
@eric_seufert Alt take: no, Hinge is growing 50% YoY. Tinder is comping a pandemic high, but is nonetheless flattening out/returning to growth. Also that ST data is off - they’ve actual disclosure on what the pandemic high was. Bumble/badoo is shrinking but b/c it’s hard to compete with Match.
English
I find the rise and decline of dating apps fascinating. These apps very clearly accommodated a social tradition’s cultural adaptation to the internet, but, unlike in social media, even the most successful products proved to be easily replicable low-value utilities with limited network effects due to the transient nature of dating itself.
English

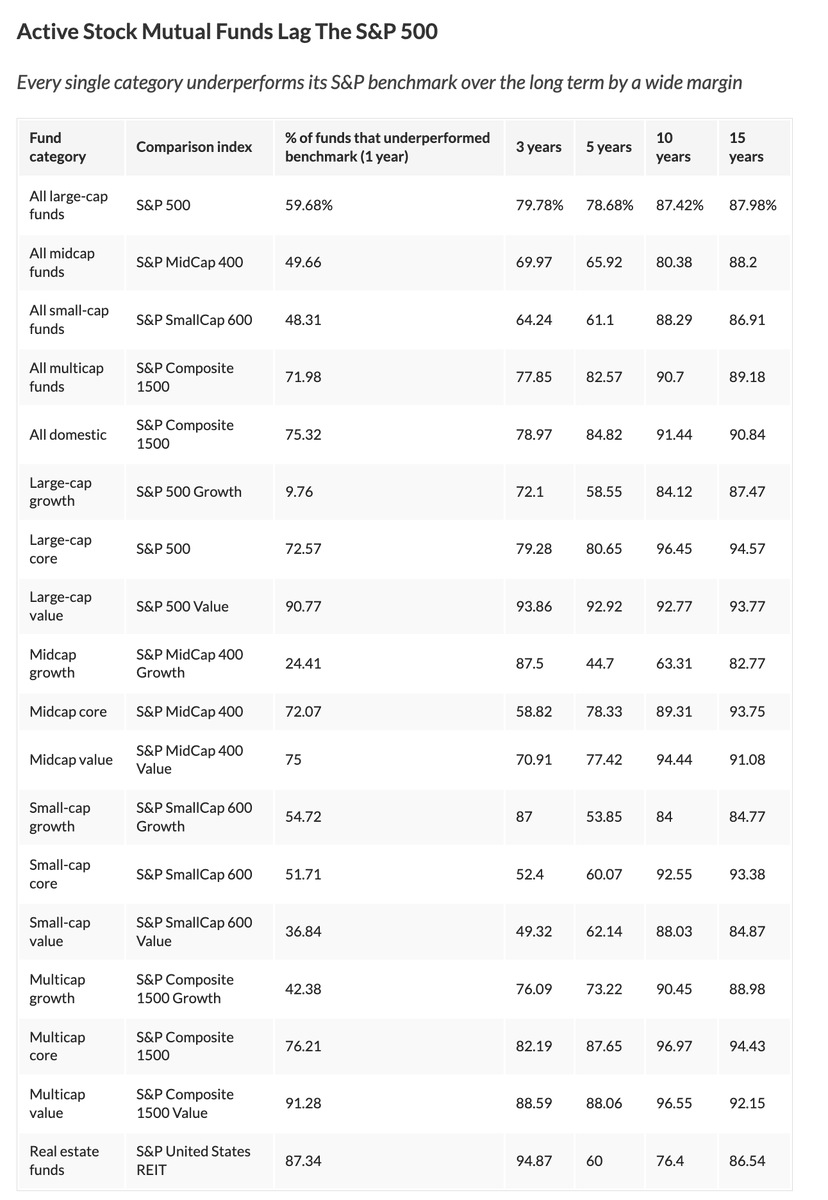
Every single active investment fund category underperforms its S&P benchmark over the long term by a wide margin
Mr Humet@mrhumet
@levelsio Trading has gotten a bad rep bc of all these social media influencers But it’s been a legit career on Wall Street for decades. Safe to say those guys aren’t posting their gains on here
English
English
